其实在上节课数量生态学笔记||数据探索中我们已经简单接触了数据的转化,我们为了使不同刚量的数据能在一起比较使用了标准化。在数据分析的过程中,经常要根据分析的需要对数据进行转化,以符合模型的内在需要。
要知道我们采集来的一手数据有时会带有我们的采集痕迹有时这种痕迹可能会掩盖问题的实质。我们常常出于以下几方面的考虑需要对数据进行转化,转化的方法也有很多,这里我们仅举几个例子。
- 使不同物理单位的数据具有可比性,比如我们的环境因子数据。常采用归一化,z-scores标准化。
- 使变量更符合正态分布和具有稳定方差。常用平方根转化,对数转化等
- 改变对象变量的权重,例如赋予所有对象向量相同的长度或者范数。
- 将分类变量转化为二元变量(1-0)或者对照码。
对于我们的物种数据,通常具有相同的刚量,通常是正值和零,对这样的数据几种简单的转化函数,可以降低极大值的影响:
- sqrt()平方根
- sqrt(sqrt())4次方根
- log1p()多度+ 1 的自然对数(保证0值转化后仍为0)
- 某些特殊的情况需要把正值化为1 也就是有-无(1-0)
下面介绍vegan包的几种转化方式。
# 数据转化和标准化
##################
#访问decostand()帮助文件
?decostand
# 简单转化
# **********************
# 显示原始数据某一部分(多度数据)
spe[1:5, 2:4]
# 将多度数据转化为有-无(1-0)数据
spe.pa <- decostand(spe, method="pa")
spe.pa[1:5, 2:4]
#物种水平:两个方法;
#有-无数据或多度数据
# *******************
# 通过每个数值除以该物种最大值标准化多度
# 注意: 这里参数MARGIN=2 (默认值)
spe.scal <- decostand(spe, "max")
spe.scal[1:5,2:4]
# 计算每列最大值
apply(spe.scal, 2, max)
#这些标准化过程是否正确运行?最好利用绘图函数或总结函数密切追踪.。
这种追踪是很有必要的,有时候我们懒得起名字,直接把处理前的名字赋给处理之后的数据,这样我们再想重复上一步的操作就很困难。对于计算量大的数据更是如此,好不容易计算出来一个数据集,重来的话又要计算好久。
#通过每个数值除以该物种总和标准化多度(每个物种的相对多度)
#注意: 这里需要设定参数MARGIN=2
spe.relsp <- decostand(spe, "total", MARGIN=2)
spe.relsp[1:5,2:4]
#计算标准化后数据每列总和
apply(spe.relsp, 2, sum)
# 样方水平:3种方法;有-无数据或多度数据
# ***************************************
#通过每个数值除以该样方总和标准化多度 (每个样方相对多度或相对频度)
#注意: 这里参数MARGIN=1 (默认值)
spe.rel <- decostand(spe, "total") # 默认MARGIN = 1
spe.rel[1:5,2:4]
#计算标准化后数据每列总和以检验标准化的过程是否正确
apply(spe.rel, 1, sum)
#赋予每个行向量长度(范数)为1(即平方和为1).
spe.norm <- decostand(spe, "normalize")
spe.norm[1:5,2:4]
# 验证每个行向量的范数
norm <- function(x) sqrt(x%*%x)
apply(spe.norm, 1, norm)
#这个转化也称为"弦转化":如果用欧氏距离函数去计算弦转化后的数据,#将获得弦距离矩阵(见第3章)。在PCA和RDA(见第5、6章)及k-means
#聚类(见第4章)分析前通常需要对数据进行弦转化。
# 计算相对频度(样方层面),然后取平方根
spe.hel <- decostand(spe, "hellinger")
spe.hel[1:5,2:4]
# 计算标准化后数据每行向量的范数
apply(spe.hel,1,norm)
#这个转化也称为Hellinger转化。如果用欧氏距离函数去计算Hellinger转
#化后的数据,将获得Hellinger距离矩阵(见第3章)。在PCA和RDA(见
#第5、6章)及k-means聚类(见第4章)分析前通常需要对数据进行Hellinger
#转化。注意,Hellinger转化等同于数据先平方根转化后再进行弦转化。
# 物种和样方同时标准化
# ****************************
# 卡方转化
spe.chi <- decostand(spe, "chi.square")
spe.chi[1:5,2:4]
# 请查看没有物种的样方8转化后将会怎样?
spe.chi[7:9,]
#如果用欧氏距离函数去计算卡方转化后的数据,将获得卡方距离矩阵(见
#第3章)
# Wisconsin标准化:多度数据首先除以该物种最大值后再除以该样方总和
spe.wis <- wisconsin(spe)
spe.wis[1:5,2:4]
# 常见种(石泥鳅 stone loach)转化后的多度箱线图
# *******************************************
par(mfrow=c(2,2))
boxplot(spe$LOC, sqrt(spe$LOC), log1p(spe$LOC),
las=1, main="简单转化",
names=c("原始数据", "sqrt", "log"), col="bisque")
boxplot(spe.scal$LOC, spe.relsp$LOC,
las=1, main="物种标准化",
names=c("max", "total"), col="lightgreen")
boxplot(spe.hel$LOC, spe.rel$LOC, spe.norm$LOC,
las=1, main="样方标准化",
names=c("Hellinger", "total", "norm"), col="lightblue")
boxplot(spe.chi$LOC, spe.wis$LOC,
las=1, main="双标准化",
names=c("Chi-square", "Wisconsin"), col="orange")
#比较多度数据转化或标准化前后的数据分布范围和分布情况。
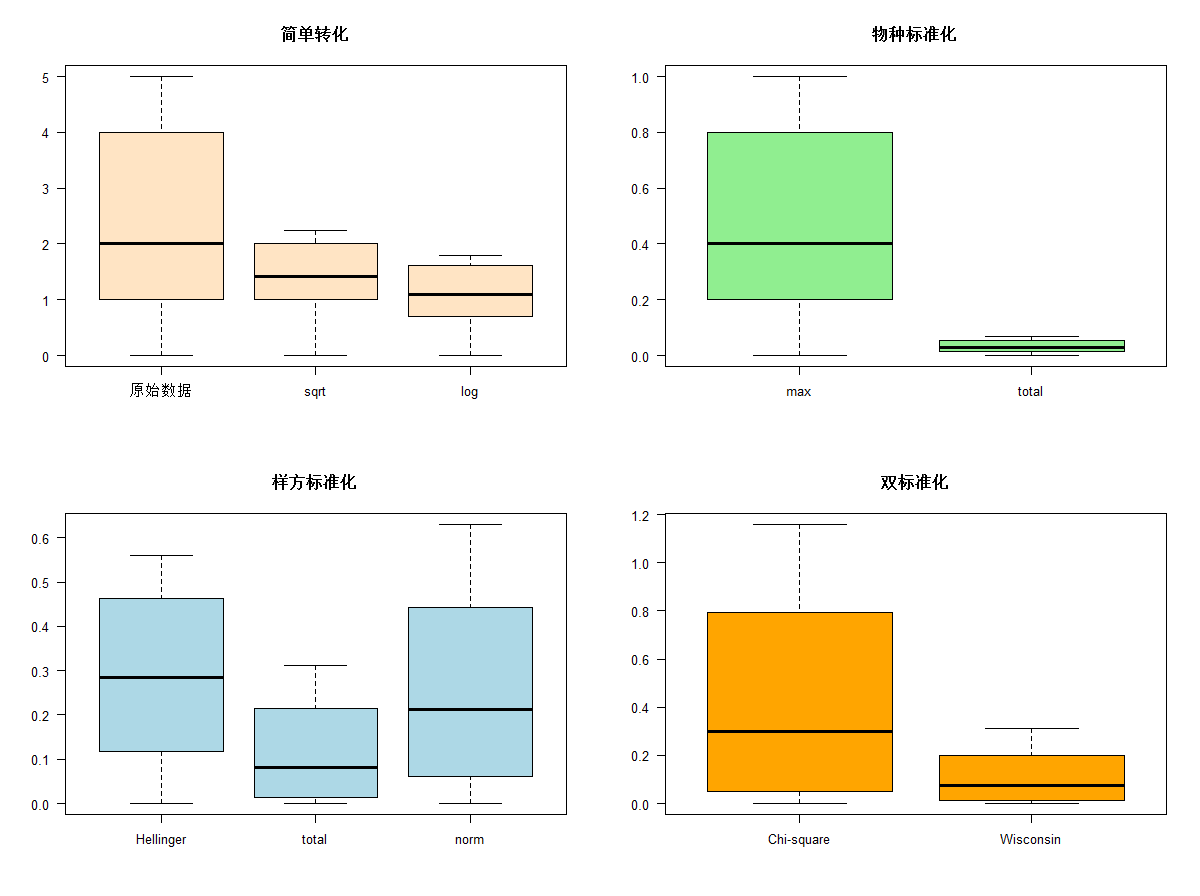
比较不同转化对数据分布的影响,理解物种水平的两种方法,样方水平的三种方法以及物种和样方水平的两种转化方法。
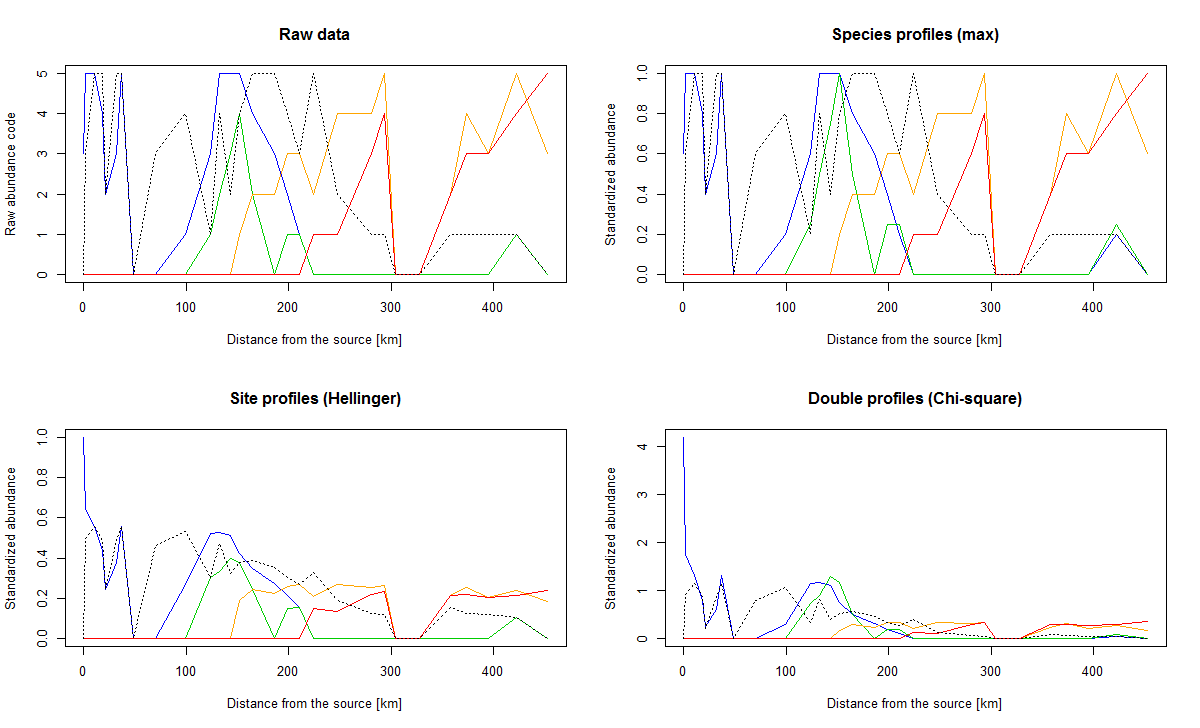
我们来看看物种数据转化前后的沿河流变化情况。
#绘制物种从河流上游到下游分布图
# ******************************
par(mfrow=c(2,2))
plot(env$das, spe$TRU, type="l", col=4, main="Raw data",
xlab="Distance from the source [km]", ylab="Raw abundance code")
lines(env$das, spe$OMB, col=3)
lines(env$das, spe$BAR, col="orange")
lines(env$das, spe$BCO, col=2)
lines(env$das, spe$LOC, col=1, lty="dotted")
plot(env$das, spe.scal$TRU, type="l", col=4, main="Species profiles (max)",
xlab="Distance from the source [km]", ylab="Standardized abundance")
lines(env$das, spe.scal$OMB, col=3)
lines(env$das, spe.scal$BAR, col="orange")
lines(env$das, spe.scal$BCO, col=2)
lines(env$das, spe.scal$LOC, col=1, lty="dotted")
plot(env$das, spe.hel$TRU, type="l", col=4,
main="Site profiles (Hellinger)",
xlab="Distance from the source [km]", ylab="Standardized abundance")
lines(env$das, spe.hel$OMB, col=3)
lines(env$das, spe.hel$BAR, col="orange")
lines(env$das, spe.hel$BCO, col=2)
lines(env$das, spe.hel$LOC, col=1, lty="dotted")
plot(env$das, spe.chi$TRU, type="l", col=4,
main="Double profiles (Chi-square)",
xlab="Distance from the source [km]", ylab="Standardized abundance")
lines(env$das, spe.chi$OMB, col=3)
lines(env$das, spe.chi$BAR, col="orange")
lines(env$das, spe.chi$BCO, col=2)
lines(env$das, spe.chi$LOC, col=1, lty="dotted")
legend("topright", c("Brown trout", "Grayling", "Barbel", "Common bream",
"Stone loach"), col=c(4,3,"orange",2,1), lty=c(rep(1,4),3))
#比较这些图,并解释它们的不同。