
本文将介绍如何为 Rasa 添加基于检索的响应选择。Rasa 1.3.0 中引入了检索动作和 ResponseSelector NLU 组件,这两个组件拼接在一起使之更容易处理特定的对话元件,如:闲聊、FAQ 消息和其他单回合的简单互动。简而言之,本文主要表达了三个主要思想:
- 轻松处理 Rasa 中的单回合互动
- 将单回合互动的响应定义为训练数据,这与 domain 文件中的简单发送不同
- 构建模型以达到在单回合互动中选择适当的助理响应
本文的目录结构:
- 检索动作
- 有监督响应选择器
- 训练数据
- 使用响应选择器玩转更多内容
- 为什么该功能是实验性的
- 总结
1. 检索动作
检索动作旨在简化 FAQ、闲聊和其他单回合互动的处理。单回合意味着你的助手应该始终以相同的方式作出反应,而不管在以前的互动中发生了什么,让我们看看以下对话示例:
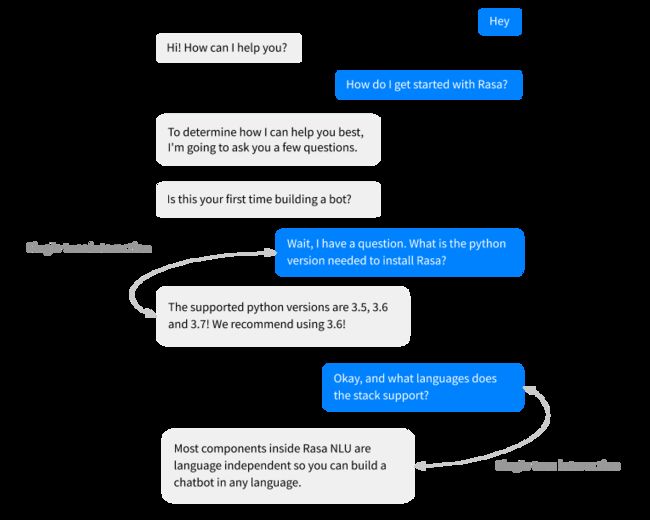
无论在对话过程中发生了什么,当用户向 bot 询问推荐 Python 版本时,bot 应该始终给出相同的答案。以前,你需要为每个要处理的 FAQ 配置一个 story,看起像下面一样:
## Ask Python version
* ask_faq_python_version
- utter_ask_python_version
## Ask languages supported in Rasa
* ask_faq_languages
- utter_ask_languages
如果你使用检索动作,则只需要一个 story!
## Some question from FAQ
* ask_faq
- respond_ask_faq
那有什么变化吗?所有与 FAQ 相关的意图都归到一个检索意图,并通过一个 respond_ask_faq 动作来响应。这使得更容易以相同的方式处理所有的 FAQ 消息,无论他们的具体意图如何,都可以通过一次检索动作来进行处理。
由于对此类意图的响应不依赖于先前的消息,因为我们不需要复杂的核心策略来预测相应的检索动作。但是,由于只有一个检索动作,因为我们需要构建一个机器学习模型,它用来在所有候选响应中选择最合适的响应,该怎么做?
2. 有监督响应选择器
我们在 NLU 中引入了一个新的组件 ResponseSelector,该组件的工作原理是:
- 为每个用户消息和候选响应收集词袋特征;
- 通过将词袋表示法传入紧密的连接层,分别计算每个学习嵌入表示;
- 使用相似度函数来计算用户消息嵌入和候选响应嵌入之间的相似度;
- 最大化正确的用户消息和响应之间的相似度,并最小化错误对的相似度,这是训练过程中 ML 模型的优化功能;
- 在推理时将用户消息的相似度与所有候选响应进行匹配,并选择具有最高相似度的响应作为助手对用户消息的响应。
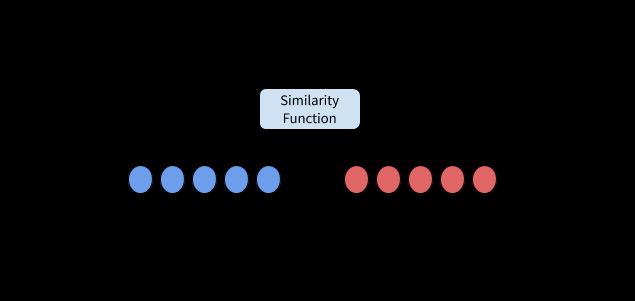
这与 EmbeddingIntentClassifier 的工作方式很相似,主要区别在于将意图替换为响应的实际文本。
该组件之前应该有一个分词器、特征提取器和意图分类器,以便它处理传入的消息。你可以通过以下方式在 NLU pipeline 中配置该组件:
language: "en"
pipeline:
- name: "WhitespaceTokenizer"
- name: "CountVectorsFeaturizer"
- name: "EmbeddingIntentClassifier"
- name: "ResponseSelector"
3. 训练数据
3.1 检索意图
我们的检索意图 ask_faq 可以包含以下 NLU 示例:
## intent: ask_faq/python_version
- What version of python is supported?
- What version of python should I have to install Rasa package?
## intent: ask_faq/languages
- Does Rasa support Chinese?
- What languages does Rasa stack support?
以上示例中有两个相关的意图:ask_faq/python_version 和 ask_faq/languages。意图分类器会将这些意图分组为单个检索意图 ask_faq,只有 ResponseSelector 才会关心 ask_faq/languages 和 ask_faq/python_version 之间的差异。
3.2 响应短语
实际的响应文本现在已经成为训练数据的一部分,因此你的 domain 文件将不再有这些文本数据,这是检索动作的响应与标准机器人响应之间的重要区别。另外,由于我们直接在用户消息文本中选择了响应,因此响应选择是端到端聊天机器人训练的一步。我们使用的响应格式与用于端到端评估的 story 格式有些相似:
## FAQ python version
* ask_faq/python_version
- Rasa currently supports python 3.5, 3.6 and 3.7! We recommend using python 3.6.
## FAQ supported languages
* ask_faq/languages
- Most components inside Rasa NLU are language independent so you can build a chatbot in any language.
在一个单独的文件(例如:responses.md)必须要有这些响应短语,而不是在同一个文件作为 NLU 训练数据。单独的文件仍然可以包含在 NLU 训练数据的同一文件夹下。
3.3 检索动作
Rasa 使用命名约束将检索意图的名称 ask_faq 与正确的检索动作相匹配,在这种情况下,正确的检索动作名称是:respond_ask_faq,必须使用前缀 respond_ 才将其识别为检索动作。你应该像其他任何动作一样,将检索动作添加到 domain 文件中,有两种方式触发这些动作:
- 如果你始终只想响应然后接收下一个用户消息,请使用
MappingPolicy将检索意图映射到 domain 文件中的响应操作。
intents:
- ask_faq: {triggers: respond_ask_faq}
- 如果你想要特定的后续动作(例如:询问用户是否要继续执行流程),你应该像其他任何动作一样,在你的 stories 中包括
respond_ask_faq动作,例如:

* greet
- utter_greet_user
* contact_sales
- utter_moreinformation
- sales_form
- form{"name": "sales_form"}
* ask_faq
- respond_ask_faq
- utter_ask_continue_sales
* affirm
- utter_great
- sales_form
- form{"name": null}
总体而言,我们尝试在两方面简化训练数据格式:
- 开发人员经验:训练数据格式对于开发人员应该竟可能直观,并且与现有训练数据格式没有太大不同。
- 逻辑意义:训练数据的所有元素应符合 Rasa 内部元素的现有逻辑结构,例如:训练数据应该在 domain 文件中。
4. 使用响应选择器玩转更多内容
Rasa 支持具有多个检索意图和响应的多个检索动作,在这种情况下,你有两种选择方式:
- 你可以构建一个共性的响应选择器模型,该模型将针对助手的所有检索意图上的用户消息和响应消息对进行训练,这种情况下,你无需在
ResponseSelector的配置中定义retrieval_intent参数。 - 你也可以为每个检索意图构建一个特定的响应选择器模型,每个模型都将在该检索意图分组的用户消息和响应消息对上进行训练。因此,在 NLU 配置中的响应选择器组件的数量与训练数据中的检索意图的数量要相同。为此,在每个
ResponseSelector组件的配置中使用retrieval_intent参数来定义相应的检索意图。
pipeline:
- name: ……
- name: "ResponseSelector"
retrieval_intent: ask_faq
…… # other architectural parameters
- name: "ResponseSelector"
retrieval_intent: chitchat
…… # other architectural parameters
通过实际用例场景来驱动构建特定响应选择器还是共享响应选择器模型,如果特定检索意图中的话语是特定领域的,例如与 FAQ 相关的问题,那么学习共享的嵌入表示法并使用来自诸如 chitchat 和 greeting 的意图的通用词可能就没有多大意义。与共享模型所使用的参数相比,使用不同的参数集可以使特定模型的性能更好。例如:如果你将某些常见问题的答案数据多于其他常见问题的答案,则在使用 balanced batching 作为批处理策略师,训练可能有所改善。
我们希望开发人员具有这种灵活性,以尝试测试他们最合适的方法。在我们的实验中,为每个检索意图构建单独的模型相比,为所有检索意图构建一个共享的响应选择器模型产生了相似的结果。
5. 为什么该功能是实验性的
随着响应选择器和检索动作的引入,我们提出了一种解决单回合互动的新方法。训练数据格式并不完全支持端到端训练,但朝着这个方向迈出了一步。同样,响应选择器组件位于 Rasa NLU 和 Core 的交集处,尽管我们认为端到端的训练是一个令人兴奋的领域,但我们希望在进一步进行之前,从社区中获取有关开发人员的总体经验、模型性能以及功能本身的足够多的反馈。因此,我们计划暂时保留该功能,这意味着可能根据收到的反馈来更改或删除该功能。
6. 总结
我们引入了响应选择器和检索动作功能,提出了一种全新的方式来处理 Rasa 助手中的单回合互动,由于该功能是实验性的,因此我们可能会根据收到的反馈来更改和删除该功能。
作者:关于我
备注:转载请注明出处。
如发现错误,欢迎留言指正。