什么是机器学习和价值预测?
What Is Machine Learning and value Prediction?

前言叨B叨
没有叨B叨直接入主题
1. 什么是机器学习
作为一个码农,你的工作就是写出各种规则来告诉计算机如何解决某个特定问题。机器学习走的却是另一种途径。机器学习是计算机自己学习事物的规则来解决问题,而不是靠编写特定的规则。让我们从一个大家都熟悉的例子开始,垃圾邮件。想象一下,你正在编写一个程序,用传统的程序来过滤收件箱中的垃圾邮件。首先,你必须编写一个复杂的程序,它包含所有的规则来决定一个特定的电子邮件是垃圾还是真实有用的信息。例如,程序可能会寻找某些你认为只出现在垃圾邮件中的关键词,或者你可能会检查发件人是不是你曾经发送过邮件给他。
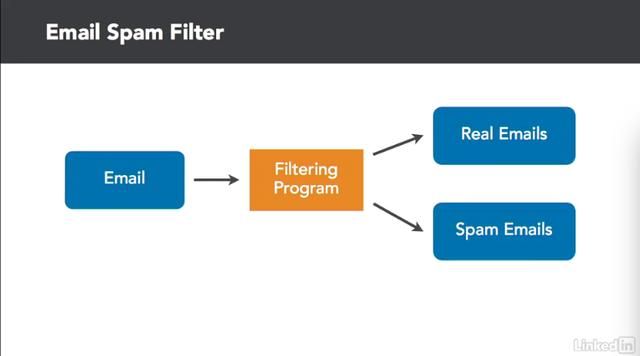
然后,通过跑一些测试电子邮件来调试程序。最后,你检查程序的结果,看看它是否正确地从垃圾邮件中分离出真实的电子邮件。在这个过程中,最难的部分是找出哪些规则有助于识别电子邮件为垃圾邮件还是真实邮件。要找出正确的规则,准确地识别垃圾邮件,而不会有任何误报,这需要大量的尝试。更闹心的是,当垃圾邮件发送者改变自己的战术,你又得相应更新你的过滤规则来应对。所以这是一个无止境的体力活。
如果计算机能自己想出过滤电子邮件的逻辑,那该多好哇,所以这个就是我们可以用机器学习来实现的东西。机器学习来搞定这个事情大概有以下几个步骤: 首先,我们收集数千封电子邮件,把它们分成两组。一组是正儿八经的邮件。另一组则是垃圾邮件。接下来,我们将这些电子邮件放入机器学习算法中。机器学习算法是一个现成的系统。我们不必编写任何自定义代码便能使其工作。机器学习算法将检查两组电子邮件,并创建它自己的规则,告诉他们如何区分它们。这个过程叫做训练。
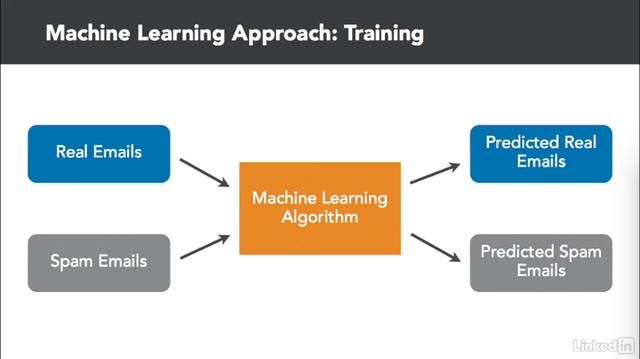
我们正在给机器学习算法输入原始的电子邮件和预期的输出数据,每一封电子邮件应该被分类为真实的或垃圾邮件,它创建了自己的规则来确定输入什么样的数据会产生什么样的输出。训练过程中使用的数据越多,就越有可能学习到如何准确地做到这一点。一旦模型被训练出来,我们现在就可以用它来以前从未见过的电子邮件了。当我们输入一个未知的电子邮件,它将使用训练过程中所学到的规则,正确地区分垃圾邮件和正常邮件。有了机器学习,我们就不必自己做苦逼的体力活了。也就是说我们不用写任何邮件过滤规则。
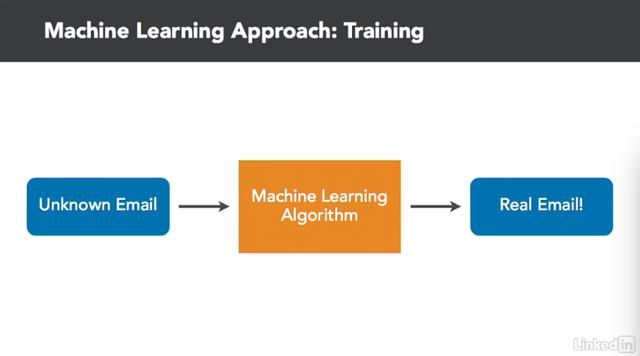
计算机根据自己所看到的训练数据提出了自己的建议。机器学习最酷的部分是我们用电子邮件分类的算法可以通过改变我们输入的数据来解决很多其他的问题,而这不需要改变任何一行代码。例如,输入的时候我们不输入电子邮件, 而是输入一张照片或者手写数字。该算法可以决定每个图片所代表的数字,无论是0还是1,或者在本例中为8。同样的算法,即可用于电子邮件过滤,也可以用来做手写识别。

用传统的编程方法,你可以给计算机精确地说明如何解决问题。计算机只能做它以前做过的事情。与机器学习不同,计算机不需要显式地编程便会学习如何解决未解决过的事情。取而代之的是,你给计算机输入数据,计算机从数据中学习到那些类似的逻辑来替代你的手工编程。
机器学习是解决传统编程难以解决的复杂问题的一种有效方法。
2. 有监督的机器学习 价值预测
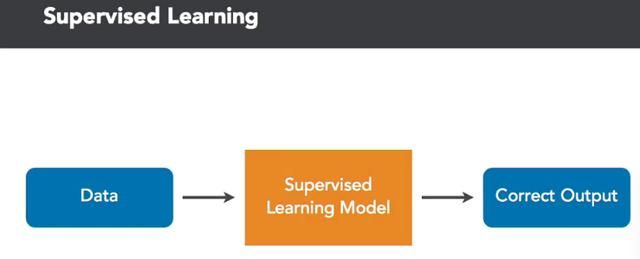
在本课程中,我们将使用有监督的机器学习来预测价值。有监督学习是机器学习的一个分支,计算机通过在标记的训练数据上学习如何执行函数。机器学习还有其他分支,如无监督学习和强化学习,但监督学习是最常用的,也是我们入门的最佳选择。这里我们将使用监督学习做价值预测。
我们通过输入数据并告诉机器正确的值输出应该是什么样的数据,然后来训练有监督的学习模型,我们的机器学习算法使用这些数据来生成规则来重现相同的结果。
例如,如果我们显示数字2和2,并且告诉它答案是4,然后我们显示数字3和5,并且告诉它答案是8,它将开始决定如何做加法。


只要看了足够多的例子,它就会发现,每当看到两个数时,我们就希望结果是这些数之和。总和是系统预测的值。我们称这种过程为训练(training)。一旦对模型进行训练,我们就可以使用它来查找新的数据,并告诉我们它对新输入数据应该值多少的估计。如果我们展示它7和2,现在它依据对它已有的训练, 可以告诉我们答案是9。该系统能够通过从训练数据中学到的知识来预测新数据的值。让我们来看一个更复杂的例子。
假设你是一个有多年房产销售经验的房地产经纪人。因为你已经卖了很长时间的房子了,所以你可以随便瞄一眼任意一套房子,便可估计这房子大概多少钱。你几乎可以在不知不觉中做到这一点。例如,这个房子很宽敞,它位于一个很好的社区,它有一个很大的前院,从街上看起来很吸引人。基于这些因素,你可能会估计在当地市场价值450000美元。但现在你的房地产业务不断增长,你不能自己管理所有的客户。你决定招几个小弟来帮你。
但是有一个问题,你的小弟没有你的经验,所以他们不知道如何给房子定价。为了帮助你的小弟,你想写一个程序,可以根据你的房子的大小,是否学区房和最近类似房型成交价等等来估计房子的价值。我们可以用有监督的机器学习来做到这一点。首先,记录下来三个月内这个地区成交的房子。对于每一栋房子,我们都会写下房子的基本特征,比如卧室的数目,房子的大小和平方英尺,房子所在的社区,等等。但最重要的是,我们将把房子的最终销售价格写下来。
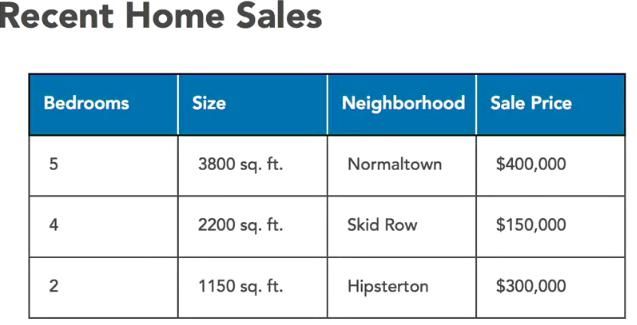
这是我们的训练数据。为了构建我们的程序,我们将把训练数据输入到机器学习算法中,该算法将找出如何为每一个房子找到正确的估值。这就是有监督的机器学习。我们之所以称之为学习,因为计算机正在学习如何根据我们所提供的价值来对房子的价格进行建模。我们说这是有监督的,因为我们给计算机正确的回答每个房子的价值。计算机所要做的就是计算输入数据和最终价格之间的关系。
3. 建立一个简单的房价估值程序
在深入研究更复杂的机器学习算法之前,让我们构建一个最简单的程序,根据它的属性来估计一个房子的价值。打开simple_value_estimator.py。在这里我们有一个功能叫做estimate_home_value。这个函数的目的是根据属性来估计一个房子的价格。这个函数包含两个属性来描述一个房子的大小,房子的平方英尺和卧室的数量。在函数的结尾处返回该房屋的预测值。要预测房子的价值,我们所要做的就是决定房子的大小和卧室的数量对房子的最终价值有多大的影响。
def estimate_home_value(size_in_sqft, number_of_bedrooms):# Assume all homes are worth at least $50,000value = 50000# Adjust the value estimate based on the size of the housevalue = value + (size_in_sqft * 92)# Adjust the value estimate based on the number of bedroomsvalue = value + (number_of_bedrooms * 10000)return value# Estimate the value of our house:# - 5 bedrooms# - 3800 sq ft# Actual value: $450,000value = estimate_home_value(3800, 5)print("Estimated valued:")print(value)
让我们先假设任何一个房子,不管多么小,至少值50000美元,所以我们可以从初始值估计50000美元开始。下一步,我们必须决定房子的大小对最终价值有多大影响。我猜每平方英尺值92美元,所以我们可以说现在的值是平方英尺乘以92。接下来,让我们看看卧室。似乎有理由认为拥有更多卧室的房子比卧室少的房子更有价值。
对于每一个卧室,我要加上,比如说,10000美元的附加值。我们会说这个值是现在的值加上卧室的10000倍。最后,让我们试试这个函数,在真正的房子上试试,我们知道它的价格是450000美元。我们将在这里走过3800平方英尺和五个卧室。我们可以通过右击和选择运行来运行这个文件。值得一提的是,还有一个用于运行文件的键盘快捷方式,但在系统上可能会有所不同。对mac来说是 control+ Shift + F10。
它将打开控制台,并显示我们程序的输出。我们的计划预测这房子价值449000美元。这真的接近我们预期的450000美元的价值。我们的估计工作得很好。在这个例子中,我们所做的就是取每一个输入值并乘以一个固定的权值。平方英尺的权重是92,卧室的权重是10000。
换句话说,我们说房子的真正价值是它的大小和卧室的数量的组合。权重告诉我们这些因素在最终计算中有多少。用一组固定的权值建模某物价值的过程称为线性回归。它是最简单的机器学习算法之一,但随着机器学习的发展,计算机通过查找训练数据自动生成权值。接下来,我们将学习让计算机如何能自己找到最佳的权重。
4. 自动找到最佳权重
上一节我们写了一个程序,通过将每一个属性乘以一个固定的权值来估计一个房子的价值,然后把它们加起来得到总的价值。我们写的函数和这个等式的数学完全相同。房子的价值=50000+(总平方英尺X第一个权重)+(卧室个数X第二个权重)。

但是我们如何知道每一个权值使用什么值,这样函数所产生的预测是不是准确的呢?诀窍在于将权重转换成计算机可以自己解决的优化问题。当我们训练机器学习算法时,我们要求它在训练数据集中找到最接近答案的最佳权重。
首先,我们需要一些训练数据。这是我们三个房子的数据,我们可以用它来训练我们的算法。
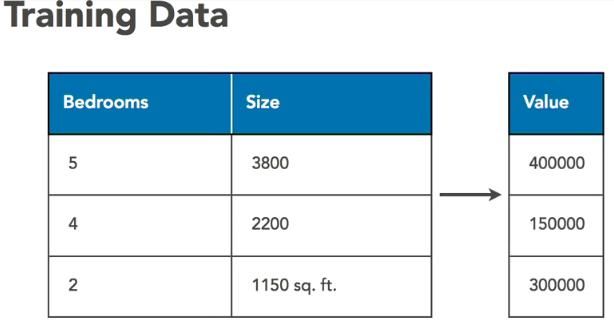
对于每一个房子,我们有卧室的数目,面积平方英尺,和家庭的实际价值。让我们为这三所已知的房子写出我们的房价等式。我只是从训练数据中替换了所有已知的值。每个方程中唯一未知的值是两个权值。我们的目标尽可能在所有这些方程里找到两个权重值。我们必须从某处开始。首先,让我们为每个权重选择完全随机猜测。

我们将两者定为10。现在我们将通过评估每一个方程来看看效果如何。让我们用10代替每一个重量,然后评估每一个方程来得到我们的初始价格估计。看看每一栋房子的实际价格,与我们计算的相比,我们可以看到我们的估算与这些权重相当遥远。让我们量化一下目前的估计是多么糟糕。让我们从房子的实际价格中减去对每个房子的预测,然后把它们全部加起来。现在,让我们把方程中的每个项平方。每个房子的误差平方值较大。

我们宁愿每个房子的估计都有一点小的误差,而不是某个房子误差太大。最后,让我们将整个数据与数据集中的房屋数分开。我们有三所房子,所以我们分三套。它给我们数据集中单个房子的平均平方误差。按照惯例,我们将把这个错误计算称为成本函数。它告诉我们当前的权重是错的多离谱,换句话说,就是当前模型的总成本。我们的目标是找到在我们的数据集中最小化所有房屋成本的权重。如果我们可以使成本等于零,那么我们的预测算法就是完美的。
成本函数的价值越高,我们的预测就错的越离谱。让我们以更一般的方式重写完全相同的成本等式。

这个等式是说总成本是每一个猜测和每个房子的实际值之间的平方差之和。然后整以房子的数目。现在我们有一个优化的成本函数,我们可以使用一个标准的数学优化算法来寻找函数的最小值。一个非常常见的优化算法可以用来解决这个问题:梯度下降(Gradient descent )。
梯度下降(Gradient descent )是一种迭代优化算法,我们可以用它来找到最佳的权重。它的工作原理是在一个方向上微调每一个重量,使成本下降。以下是它的工作原理。首先,我们通过成本函数和随机起始权值来进行梯度下降。然后,通过反复调整权重,将权重值梯度下降成千上万次直到0,从而使成本函数尽可能接近零。最后,当梯度下降到成本无法下降时,将返回它找到的最佳权重。
在我们的例子中,它会返回92.1和10001。让我们用梯度下降的权重再重新计算房价。分92.1和10001作为我们的权重。现在让我们计算一下我们的系统对每个房子价格的预测。我们可以看到这三个预测看起来都很好。

它们都不是完美的,它们都非常接近各自房子的实际价值。让我们回顾一下我们如何为简单房价估值找到最佳的权重。
首先,我们创建了一个方程来模拟问题,估算一套房子的价值。
第二,我们创建了成本函数来量化模型中的错误。最后,我们使用梯度下降优化算法找到模型参数,尽量减少成本函数。
我们将在本课程中使用的机器学习库将为我们处理所有这些计算,包括运行梯度下降。但是对幕后发生的事情有个基本的想法是很重要的,这样你就可以更好地理解什么样的问题可以用机器学习来解决。
5. 使用酷酷滴价值预测程序
价值预测是一个非常有用的技术,因为我们可以用它来解决很多不同种类的问题。在这个过程中,我们的项目是建立一个系统,可以预测房子的价值,根据它的属性。但是只要你有训练数据,你就可以用完全相同的技术来评估任何产品。例如,我们可以建立一个系统,可以根据它的属性,比如它的年份,它的状况,颜色和里程来估计二手车的价值。或者我们可以建立一个系统,根据手机的特点和类似手机的过去销售情况来评估我们想转售的二手手机的价值。还有就是可以预测诈骗。
当你在网上买东西或使用信用卡时,你支付的时候很可能要经过欺诈检测算法的检测。在这种情况下,该模型使用您购买的细节来决定您的这次支付是不是可能是欺诈的。如果该模型返回高欺诈的可能性,支付将被阻止。同样,价值预测被用来模拟控制发放住房贷款的风险。在这种情况下,输入是关于借款人的详细信息,输出是贷款偿还的可能性。这有助于银行决定哪些贷款值得冒风险。但价值预测并不局限于金融交易。
例如,你可以建立一个模型,其中输入是电影评论中出现的词,输出是评论的正或负。这叫做情绪检测。它允许计算机查看一个人写的一段文字,并猜测人类是否正在写一个正面或负面的评论。
医学领域的价值预测也有许多用途。机器学习模型经常被用来帮助医生阅读X射线和其他类型的医学图像。这些模型有时比砖家更可靠。人工智能研究人员甚至预测在五年内,计算机解析x光片将比放射科医师更牛逼可靠。
值预测算法非常有用,因为很多问题可以被建模为价值预测问题。如果输入的算法是一张带摄像机的图片,输出是转动方向盘的角度和按下油门踏板的量---- 呐, 你小子刚刚创建了一个简单的自动驾驶模型!
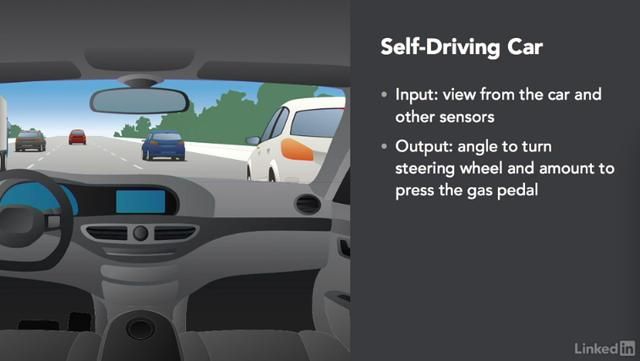
学习如何将问题建模为一个价值预测问题是一项非常有用的技能。一旦你确定了输入和输出,你通常可以用机器学习来建立一个解决方案。
今天内容有点多哈, 但全是知识点啊朋友们, 认真点哦. 我先洗洗睡了
如有错误请高手指正.
你的 关注-收藏-转发 是我继续分享的动力!