
#一
使用的数据集是SofaSofa上练习赛的自行车数据,通过简单的分析,构建线性回归模型,RMSE评价好于标杆模型中的线性回归模型和决策树回归模型。
#二
第一步,看看训练数据长啥样子,加载数据,查看下前3个观测

看下数据的说明
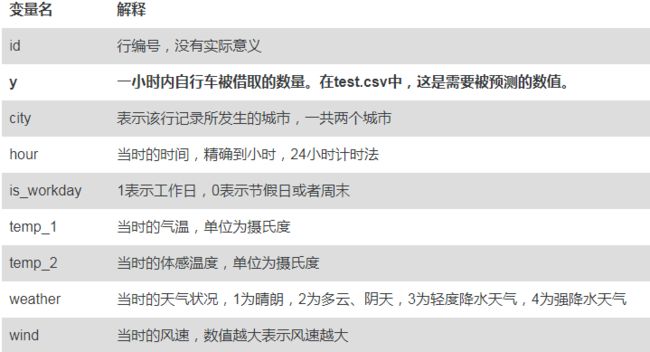
看下观测数量以及有没有缺失值
可以看到,共有10000个观测,没有缺失值。
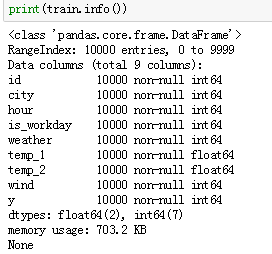
接下来可以看看每个变量的基础描述信息
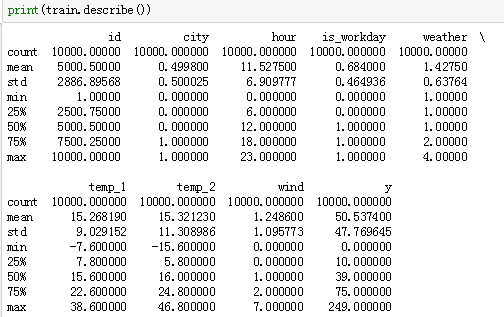
通过观察可以得出一些猜测,如城市0和城市1基本可以排除南方城市;整个观测记录时间跨度较长,可能还包含了一个长假期数据等。
最后看看相关系数(为了方便查看,绝对值低于0.2的就用nan替代)
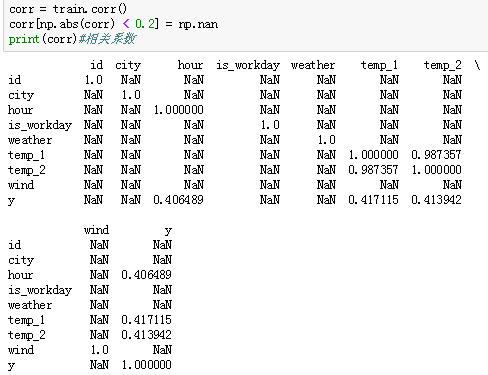
从相关性角度去看,用车的时间和当时的气温对对借取数量y有较强关系;气温和体感气温显强正相关(共线性),这个和常识一致
#三
现在开始看看图。
先看下城市和时间变量,对借取量y有没有影响
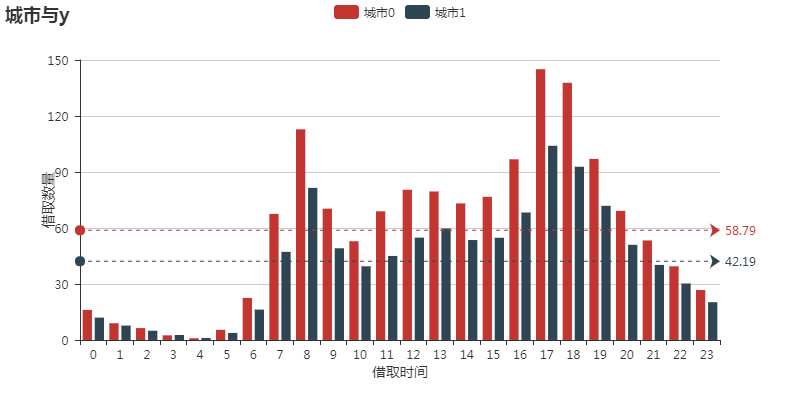
城市0的借取量高于城市1,借取量的高峰在早上8点和晚上5/6点,和日常上下班高峰时间基本吻合,估计都是命苦的上班族
节假日是否会影响借取量?
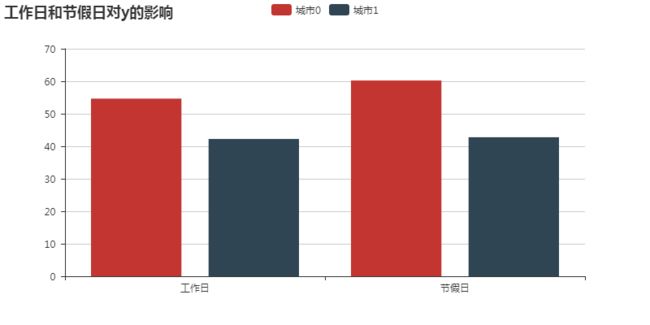
可以看出,只对城市0有影响,但影响有限
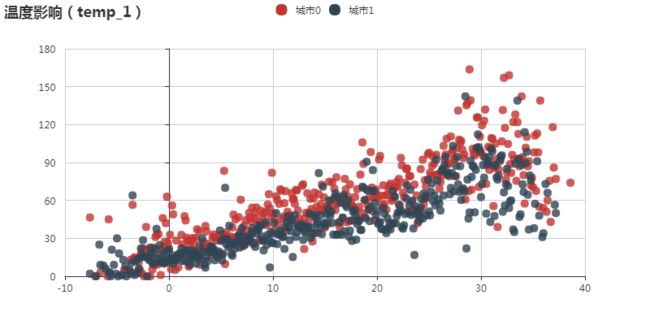
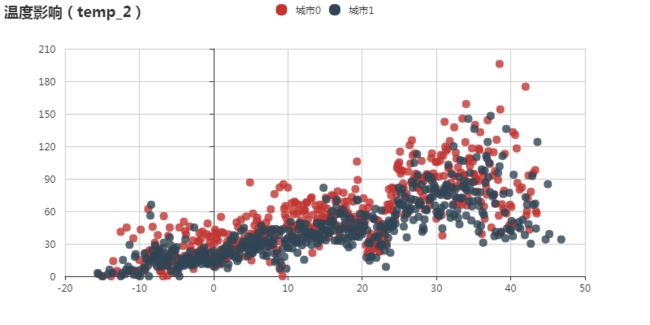
温度对借取量呈现线性相关

天气对借取量影响明显,而且城市0的人好猛,强降雨天气依然借取出行
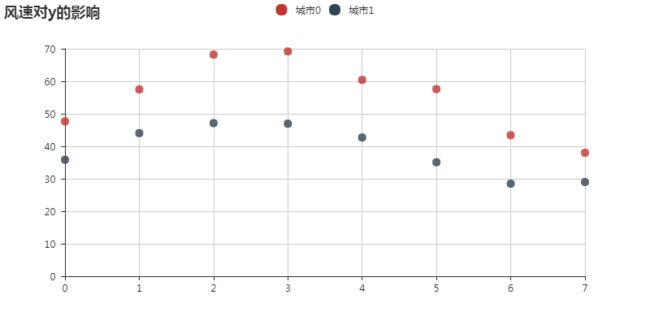
风速对借取量也有影响,无风或大风天借取量较少
#四
依据上面的情况,选择城市、时间、当时的气温、天气状况、风速等5个变量作为特征变量拟合模型

模型训练完成,剩下的就是使用测试集进行预测,上传预测结果
RMSE( 均方根误差 )
比标杆的线性回归和决策树回归要好。