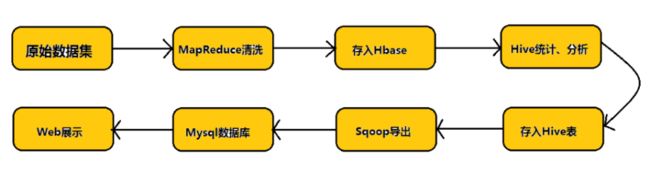
Sqoop 简介
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
特征
- Sqoop:SQL-to-Hadoop
- 连接传统关系型数据库和Hadoop的桥梁 把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFS、HBase 和 Hive) 中; 把数据从 Hadoop 系统里抽取并导出到关系型数据库里
- 利用MapReduce,批处理方式进行数据传输
Sqoop的优势
- 高效、可控的利用资源,任务并行度、超时时间等
-
数据类型映射与转换可自动进行,用户也可自定义
- 支持多种数据库(MySQL、Oracle、PostgreSQL)
架构图

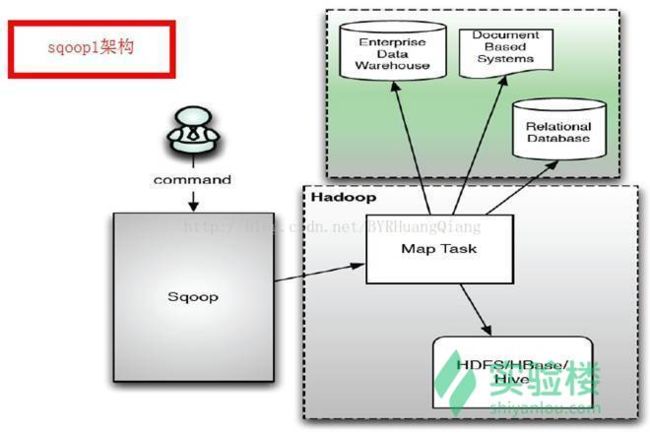
Sqoop 发展至今主要演化了两大版本:Sqoop1 和 Sqoop2。
- 两个不同的版本,完全不兼容
- 版本号划分区别,Apache 版本:1.4.x(Sqoop1); 1.99.x(Sqoop2) CDH 版本 : Sqoop-1.4.3-cdh4(Sqoop1) ; Sqoop2-1.99.2-cdh4.5.0 (Sqoop2)
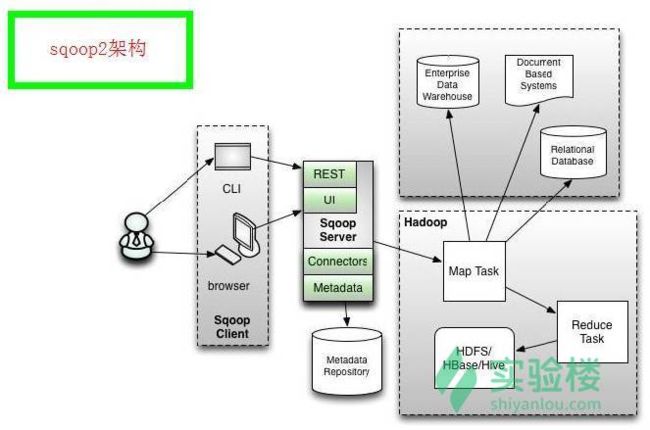
- Sqoop2 比 Sqoop1 的改进
- 引入 Sqoop server,集中化管理 connector 等
- 多种访问方式:CLI,Web UI,REST API
- 引入基于角色的安全机制
Sqoop 架构图 1
Sqoop 架构图 2:
Sqoop1 与 Sqoop2 的优缺点

Flume 介绍(日志收集)
日志收集
工作方式
优势
具有特征
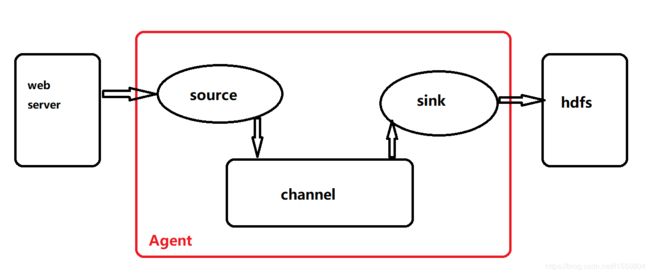
结构
Source:
常见类型: :avro 、exec、 jms、spooling directory、source 、kafka 、netcat 等
Channel:
常见类型:Memory、JDBC、File等
sink:
常见类型:HDFS、Logger、File Roll、Avro、Thrift、HBase等
Flume 还具有 Reliability、Scalability、Manageability 和 Extensibility 特点
Reliability:Flume 提供 3 种数据可靠性选项,包括 End-to-end、Store on failure 和 Best effort。其中 End-to-end 使用了磁盘日志和接受端 Ack 的方式,保证 Flume 接受到的数据会最终到达目的。Store on failure 在目的不可用的时候,数据会保持在本地硬盘。和 End-to-end 不同的是,如果是进程出现问题,Store on failure 可能会丢失部分数据。Best effort 不做任何 QoS 保证。Scalability:Flume 的 3 大组件:collector、master 和 storage tier 都是可伸缩的。需要注意的是,Flume 中对事件的处理不需要带状态,它的 Scalability 可以很容易实现。Manageability:Flume 利用 ZooKeeper 和 gossip,保证配置数据的一致性、高可用。同时,多 Master,保证 Master 可以管理大量的节点。Extensibility:基于 Java,用户可以为 Flume 添加各种新的功能,如通过继承 Source,用户可以实现自己的数据接入方式,实现 Sink 的子类,用户可以将数据写往特定目标,同时,通过 SinkDecorator,用户可以对数据进行一定的预处理。
多个Agent连接
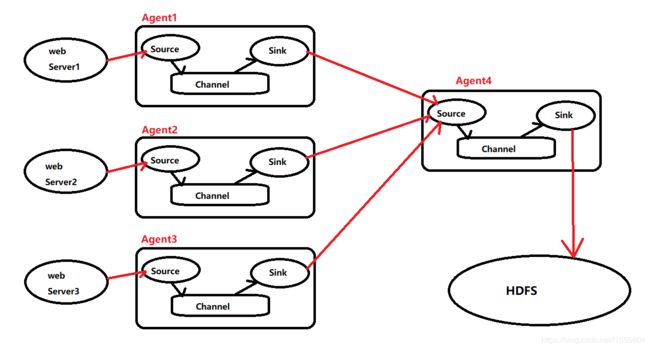
3个Agent连接一个Agent时,要注意的是,3个Agent中Sinks的类型需要统一,因为另一个Agent的Source类型需要统一的数据源类型来接收。
一个或者多个Agent连接就形成了流,流将数据推送到了另一个Agent,最终将数据推送到存储或者索引系统。
Chukwa 简介
Apache 的开源项目 hadoop, 作为一个分布式存储和计算系统,已经被业界广泛应用。很多大型企业都有了各自基于 hadoop 的应用和相关扩展。当 1000+ 以上个节点的 hadoop 集群变得常见时,集群自身的相关信息如何收集和分析呢?针对这个问题, Apache 同样提出了相应的解决方案,那就是 chukwa。
chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
结构图:

2. chukwa 不是一个实时错误监控系统.在解决这个问题方面, ganglia,nagios 等等系统已经做得很好了,这些系统对数据的敏感性都可以达到秒级. chukwa 分析的是数据是分钟级别的,它认为像集群的整体 cpu 使用率这样的数据,延迟几分钟拿到,不是什么问题.
3. chukwa 不是一个封闭的系统.虽然 chukwa 自带了许多针对 hadoop 集群的分析项,但是这并不是说它只能监控和分析 hadoop.chukwa 提供了一个对大数据量日志类数据采集、存储、分析和展示的全套解决方案和框架,在这类数据生命周期的各个阶段, chukwa 都提供了近乎完美的解决方案,这一点也可以从它的架构中看出来.
1. 总体而言, chukwa 可以用于监控大规模(2000+ 以上的节点, 每天产生数据量在T级别) hadoop 集群的整体运行情况并对它们的日志进行分析
2. 对于集群的用户而言: chukwa 展示他们的作业已经运行了多久,占用了多少资源,还有多少资源可用,一个作业是为什么失败了,一个读写操作在哪个节点出了问题.
3. 对于集群的运维工程师而言: chukwa 展示了集群中的硬件错误,集群的性能变化,集群的资源瓶颈在哪里.
4. 对于集群的管理者而言: chukwa 展示了集群的资源消耗情况,集群的整体作业执行情况,可以用以辅助预算和集群资源协调.
5. 对于集群的开发者而言: chukwa 展示了集群中主要的性能瓶颈,经常出现的错误,从而可以着力重点解决重要问题
基本架构
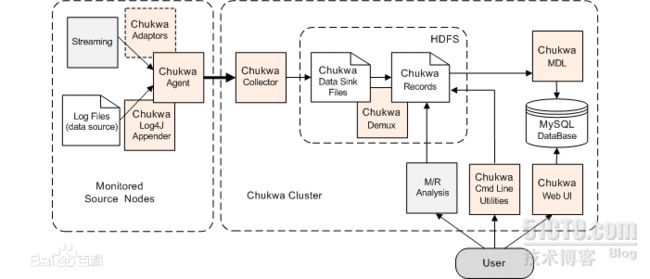
其中主要的部件为:
1. agents : 负责采集最原始的数据,并发送给 collectors
2. adaptor : 直接采集数据的接口和工具,一个 agent 可以管理多个 adaptor 的数据采集
3. collectors 负责收集 agents 收送来的数据,并定时写入集群中
4. map/reduce jobs 定时启动,负责把集群中的数据分类、排序、去重和合并
5. HICC 负责数据的展示
adaptors 和 agents
在 每个数据的产生端(基本上是集群中每一个节点上), chukwa 使用一个 agent 来采集它感兴趣的数据,每一类数据通过一个 adaptor 来实现, 数据的类型(DataType?)在相应的配置中指定. 默认地, chukwa 对以下常见的数据来源已经提供了相应的 adaptor : 命令行输出、log 文件和 httpSender等等. 这些 adaptor 会定期运行(比如每分钟读一次 df 的结果)或 事件驱动地执行(比如 kernel 打了一条错误日志). 如果这些 adaptor 还不够用,用户也可以方便地自己实现一个 adaptor 来满足需求。
另一方面, 对于重复采集的数据, 在 chukwa 的数据处理过程中,会自动对它们进行去重. 这样,就可以对于关键的数据在多台机器上部署相同的 agent,从而实现容错的功能.
collectors
agents 采集到的数据,是存储到 hadoop 集群上的. hadoop 集群擅长于处理少量大文件,而对于大量小文件的处理则不是它的强项,针对这一点,chukwa 设计了 collector 这个角色,用于把数据先进行部分合并,再写入集群,防止大量小文件的写入。
另 一方面,为防止 collector 成为性能瓶颈或成为单点,产生故障, chukwa 允许和鼓励设置多个 collector, agents 随机地从 collectors 列表中选择一个 collector 传输数据,如果一个 collector 失败或繁忙,就换下一个 collector. 从而可以实现负载的均衡,实践证明,多个 collector 的负载几乎是平均的.
demux 和 archive
放在集群上的数据,是通过 map/reduce 作业来实现数据分析的. 在 map/reduce 阶段, chukwa 提供了 demux 和 archive 任务两种内置的作业类型.
demux 作业负责对数据的分类、排序和去重. 在 agent 一节中,我们提到了数据类型(DataType?)的概念.由 collector 写入集群中的数据,都有自己的类型. demux 作业在执行过程中,通过数据类型和配置文件中指定的数据处理类,执行相应的数据分析工作,一般是把非结构化的数据结构化,抽取中其中的数据属性.由于 demux 的本质是一个 map/reduce 作业,所以我们可以根据自己的需求制定自己的 demux 作业,进行各种复杂的逻辑分析. chukwa 提供的 demux interface 可以用 java 语言来方便地扩展.
而 archive 作业则负责把同类型的数据 文件合并,一方面保证了同一类的数据都在一起,便于进一步分析, 另一方面减少文件数量, 减轻 hadoop 集群的存储压力。
dbadmin
放在集群上的数据,虽然可以满足数据的长期存储和大数据量计算需求,但是不便于展示.为此, chukwa 做了两方面的努力:
1. 使用 mdl 语言,把集群上的 数据抽取到 mysql 数据库中,对近一周的数据,完整保存,超过一周的数据,按数据离当前时间长短作稀释,离当前越久的数据,所保存的数据时间间隔越长.通过 mysql 来作数据源,展示数据.
2. 使用 hbase 或类似的技术,直接把索引化的数据在存储在集群上
到 chukwa 0.4.0 版本为止, chukwa 都是用的第一种方法,但是第二种方法更优雅也更方便一些.
hicc
hicc 是 chukwa 的数据展示端的名字.在展示端, chukwa 提供了一些默认的数据展示 widget,可以使用“列表”、“曲线图”、“多曲线图”、“柱状图”、“面积图式展示一类或多类数据,给用户直观的数据趋势展示。而且,在 hicc 展示端,对不断生成的新数据和历史数据,采用 robin 策略,防止数据的不断增长增大服务器压力,并对数据在 时间轴上“稀释”,可以提供长时间段的数据展示
原文来源:https://www.cnblogs.com/hollowcabbage/p/9536785.html 、 https://blog.csdn.net/f1550804/article/details/88544158 、 https://baike.baidu.com/item/Chukwa/1854010?fr=aladdin