作为大数据,我们需要获取大数据来源,今天把日志收集这块整理下,采用 Apache 的 开源技术 Flume 作为日志收集的工具。接下来根据官方文档按照自己的理解进行梳理。
1、理论理解
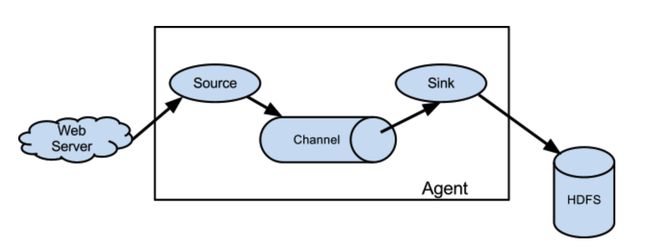
Flume 是一个日志采集模块,需要根据源、通道、目的地三个组件来完成把源的日志或者信息通过这个管道运输到另外一个地方,如下图
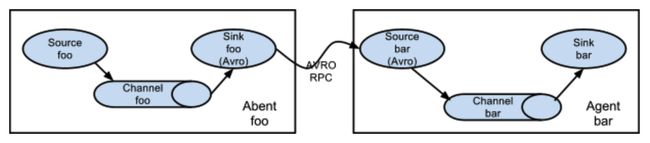
当然管道的目的地(Sink)也可以是下一个模块的源,如下图
一个管道可以有多个源,如下图
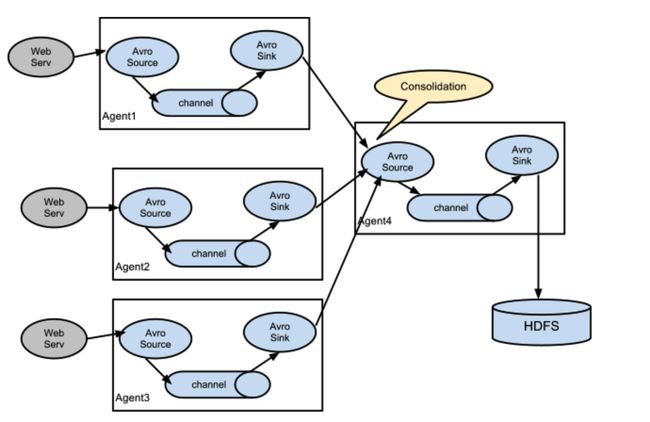
一旦有多个代理进行嵌套,他们之间基本是采用 avro 这样的source和sink。
2、搭建环境
环境搭建非常简单,首先是基于 java,所以需要 JDK 支持,这里使用目前最新的 Flume 1.8.0,官方说明需要至少 JDK1.8以上。
按照 JDK 不再描述,装完之后,我们需要下载最新的 Flume 安装包
链接地址
为了使用方便,解压该包之后,配置下环境变量

之后再新开命令窗口,输入
flume-ng help
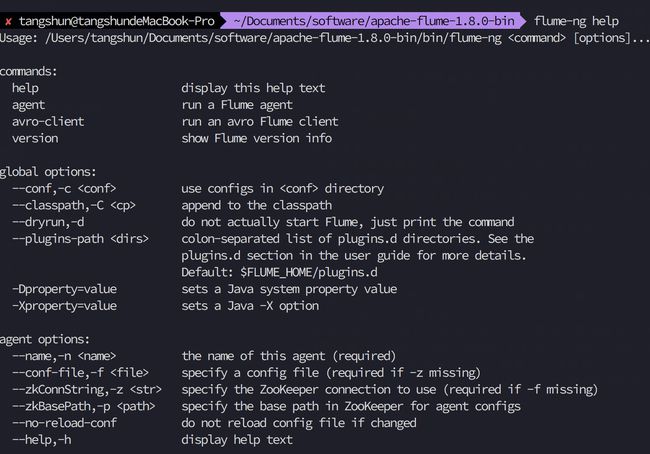
可以看到基本信息内容,其中包括命令和参数,其中命令如下
help display this help text,显示帮助信息
agent run a Flume agent ,运行一个 flume 代理
avro-client run an avro Flume client 运行一个 avro 客户端
version show Flume version info
参数部分较多,常用的是
--conf,-c
--name,-n
--conf-file,-f
还是比较好理解的。接下来我们来运行官方的一个例子
3、从指定网络端口采集数据到控制台
官方有个例子的配置文件,其实 flume 大部分功能只需要配置就可以搞定,特殊的需要额外的第三方包,或者自行定义 Source、Channel 和 Sink 组件。这里我们进行简单的配置,能够入门即可。
为了方便,把配置文件统一放在 $FLUME_HOME/conf/目录下,我们在该目录下建立一个配置文件叫 example.conf,内容如下,说明非常细致了。
#使用 Flume 的关键就是写配置文件
# A)配置 Source
# B) 配置 Channel
# C) 配置 Sink
# D) 配置 把三组件串起来
#下面是在这个 agent 上命名组件
# a1 是 agent的名称
# r1是数据源的名称,a1可能有多个数据源,这里是复数
# k1是sink 的名称
# c1是 channel 的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#配置 source
# a1的数据源,其中叫 r1的进行配置
# https://flume.apache.org/FlumeUserGuide.html#netcat-tcp-source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# a1的 sinks 中叫 k1的进行配置
# https://flume.apache.org/FlumeUserGuide.html#logger-sink
a1.sinks.k1.type = logger
# 使用一个带有 buffer 的内存式的 channel
# https://flume.apache.org/FlumeUserGuide.html#memory-channel
a1.channels.c1.type = memory
#a1.channels.c1.capacity = 1000
#a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
# 配置源到 channel 注意复数,一个 source 可以输出到多个 channel
# 配置 sink 和 channel,一个 channel 可以输出到的 sink 只有1个
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
有了上面的配置文件,就需要运行他了,根据官方的提示,我们得知
#运行
$ bin/flume-ng agent \ 表示运行代理
--conf $FLUME_HOME/conf \ 表示配置文件的目录
--conf-file $FLUME_HOME/conf/example.conf \ 指定配置文件
--name a1 \ 指定运行的代理名称
-Dflume.root.logger=DEBUG,console
-Dorg.apache.flume.log.printconfig=true
-Dorg.apache.flume.log.rawdata=true
然后我们telnet 到本地44444端口,进行消息发送,看看控制台有什么变化
接收到的数据
Event: { headers:{} body: 68 61 68 61 61 68 0D hahaah. }
一个 Event 就是 Flume 的一个最小单元,包括可选 headers 和 body。
4、监控文件实时采集到控制台输出
一般我们的项目都是把日志通过 logback 输出到文件,然后需要把这些文件迁移到另外个地方进行分析处理,现在我们使用 Flume 进行日志移动。
先分析下 Source,Channel 和 Sink 和上一个类似
Source 我们需要使用一个Exec Source,他可以执行一个命令,比如 tail ....
#下面是在这个 agent 上命名组件
# a1 是 agent的名称
# r1是数据源的名称,a1可能有多个数据源,这里是复数
# k1是sink 的名称
# c1是 channel 的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#配置 source
# a1的数据源,其中叫 r1的进行配置
# https://flume.apache.org/FlumeUserGuide.html#exec-source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /tmp/log/log.log
# a1的 sinks 中叫 k1的进行配置
# https://flume.apache.org/FlumeUserGuide.html#logger-sink
a1.sinks.k1.type = logger
# 使用一个带有 buffer 的内存式的 channel
# https://flume.apache.org/FlumeUserGuide.html#memory-channel
a1.channels.c1.type = memory
#a1.channels.c1.capacity = 1000
#a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
# 配置源到 channel 注意复数,一个 source 可以输出到多个 channel
# 配置 sink 和 channel,一个 channel 可以输出到的 sink 只有1个
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置完成之后,我们开始测试
先启动整个配置文件example01.conf
$ bin/flume-ng agent \ 表示运行代理
--conf $FLUME_HOME/conf \ 表示配置文件的目录
--conf-file $FLUME_HOME/conf/example01.conf \ 指定配置文件
--name a1 \ 指定运行的代理名称
-Dflume.root.logger=DEBUG,console
-Dorg.apache.flume.log.printconfig=true
-Dorg.apache.flume.log.rawdata=true
启动之后,我们现在追加日志到/tmp/log/log.log 文件,就可以看到控制台输出日志。
5、将一个服务器的内容迁移到另外一个服务器
需要2台机器进行模拟
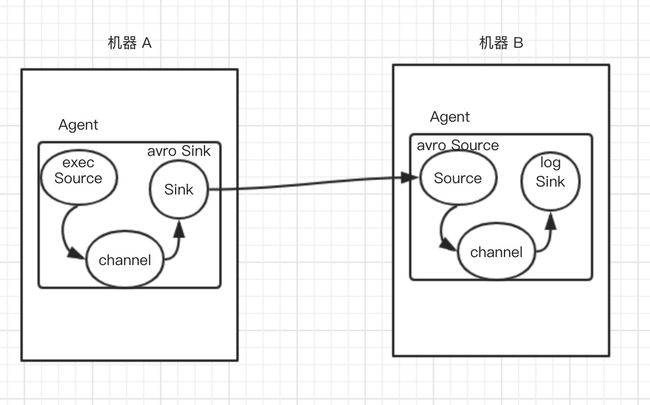

根据这个示意图,我们开始编写配置文件
############ exec-mem-avro.conf ############
# Base
exec-mem-avro.sources = exec-source
exec-mem-avro.sinks = avro-sink
exec-mem-avro.channels = mem-channel
# Source
exec-mem-avro.sources.exec-source.type = exec
exec-mem-avro.sources.exec-source.command = tail -F /tmp/log/log.log
# Sink 这里修改为 avro Sink
exec-mem-avro.sinks.avro-sink.type = avro
exec-mem-avro.sinks.avro-sink.hostname = localhost
exec-mem-avro.sinks.avro-sink.port = 44444
# Channel
exec-mem-avro.channels.mem-channel.type = memory
# Link
exec-mem-avro.sources.exec-source.channels = mem-channel
exec-mem-avro.sinks.avro-sink.channel = mem-channel
############ avro-mem-log.conf ############
# Base
avro-mem-log.sources = avro-source
avro-mem-log.sinks = log-sink
avro-mem-log.channels = mem-channel
# Source
avro-mem-log.sources.avro-source.type = avro
avro-mem-log.sources.avro-source.bind = localhost
avro-mem-log.sources.avro-source.port = 44444
# Sink
avro-mem-log.sinks.log-sink.type = logger
# Channel
avro-mem-log.channels.mem-channel.type = memory
# Link
avro-mem-log.sources.avro-source.channels = mem-channel
avro-mem-log.sinks.log-sink.channel = mem-channel
需要先在第二机器上启动 avro-mem-log.conf
然后在第一个机器上启动 exec-mem-avro.conf
#第二个机器运行
$ bin/flume-ng agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-mem-log.conf \
--name avro-mem-log \
-Dflume.root.logger=DEBUG,console
-Dorg.apache.flume.log.printconfig=true
-Dorg.apache.flume.log.rawdata=true
#第一个机器运行
$ bin/flume-ng agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-mem-avro.conf \
--name exec-mem-avro \
-Dflume.root.logger=DEBUG,console
-Dorg.apache.flume.log.printconfig=true
-Dorg.apache.flume.log.rawdata=true
在第一个机器输入日志到/tmp/log/log.log 在第二个机器就会收集到,到此,我们的 Flume 的基本入门告一段落