
论文地址:https://arxiv.org/abs/1706.06978
官方代码:https://github.com/zhougr1993/DeepInterestNetwork
一 为什么读这篇
几乎是在公司看到出现频率最高的工作,到处都有提及,各个业务方向都有研究,可见是有真正影响力的。通过从原文出发,看看到底应该怎么玩DIN。本篇也是读的第一篇集团的工作。
二 截止阅读时这篇论文的引用次数
2019.7.28 79次。2年的时间,在推荐系统里算是不错的水平了。
三 相关背景介绍
17年6月挂到arXiv上,和Transformer是同年同月的工作,中了18年的KDD。出自阿里妈妈。总共10个作者,大老板盖坤在最后一位,一作周国睿是93年的,已经是高级算法专家了。。三作朱小强是一作老板,在业界还是有名气的,知乎上也有很多小强本人的回答。
四 关键词
CTR
DIN
五 论文的主要贡献
1 提出DIN,核心就是通过用户行为序列与目标item做交互,自适应地学习用户兴趣表示
2 提出mini-batch aware正则化方法
3 提出数据自适应激活函数
4 工业界中如何评估模型效果的示范
六 详细解读
0 摘要
在传统的Embedding&MLP范式中,用户特征均被压缩为固定长度的表示向量,而没有考虑候选广告是什么。这种固定向量长度的使用方式会是一个瓶颈,因为它很难有效地捕获用户多样的兴趣。本文提出的深度兴趣网络(DIN)旨在解决这个问题,通过设计一个局部激活单元来实现。该结构协同确定的广告从用户历史行为中自适应地学习用户兴趣表示。这种表示向量随着广告的不同而不同,极大的提高了模型的表达能力。此外,本文开发了两项技术:mini-batch aware regularization和数据自适应激活函数用于训练工业级上亿万参数的模型。
1 介绍
相关广告术语
CPC(Cost Per Click):按点击计费(平均点击价格)
CPM(Cost Per Mille):按千次展现计费(千次展现价格)
eCPM(effective Cost Per Mille) = bid * CTR
CTR方法多是采用类似Embedding&MLP的范式。然而在表达用户多样的兴趣时限定维度的用户向量表示将会是一种瓶颈。以电商为例,用户可能在访问网站的时候同时对多个种类的商品感兴趣,即用户的兴趣是多样的。这种多样的兴趣被压缩在固定长度的向量中限制了Embedding&MLP方法的表达能力。但也不能简单的直接增大维度大小,这样在有限的数据上会带来过拟合的风险,也会产生计算和存储的负担。
从另一方面来说,当预测广告候选时也无需将用户多样的兴趣压缩为同一个向量,因为仅有用户的部分兴趣会影响他的行为(点或不点)。基于这个启发,本文提出了DIN,它可以通过在给定候选广告时考虑历史行为的相关性来自适应的计算用户兴趣的向量表示。与候选广告有更高相关性的行为有更高的激活权重并占据用户兴趣表示的主导。用这种方式,提升了模型在限制维度下的表示能力,同时能使DIN能够更好地捕获多样的兴趣。
当模型大小到达十亿级别时传统的计算L2正则方法计算量上不可接受(需要计算所有的参数)。本文提出的mini-batch aware regularization仅仅计算mini-batch中非零特征的参数来计算L2正则,这样使得计算量可控。同时本文设计了一个数据自适应激活函数,它派生自PReLU,通过输入的分布来自适应的调整校正点。
2 相关工作
学习每个词分布式表示的NNLM开启了embedding。LS-PLM和FM可以视为只有一个隐层的神经网络。Deep Crossing,Wide&Deep,YouTube推荐CTR模型通过复杂的MLP扩展了LS-PLM和FM。PNN,DeepFM。
3 背景
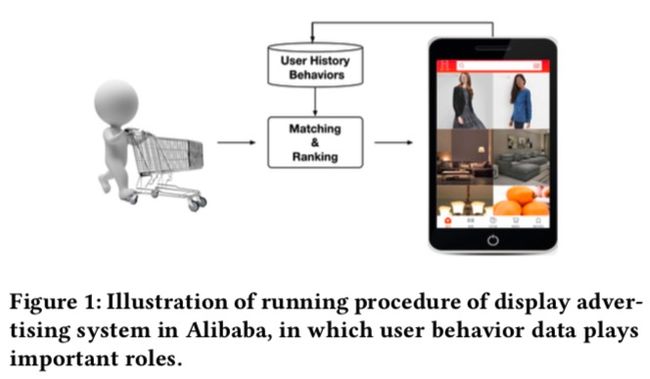
拥有丰富行为的用户兴趣是多样的,同时基于给定的广告是局部激活的。
4 深度兴趣网络
4.1 特征表示
形如[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]的数据通常通过编码转换为高维稀疏二值特征。编码后的特征如下图所示

本文所用特征如表1所示,由4个类别组成。另外本文没有使用组合特征,通过DNN来捕获特征交叉。

4.2 基础模型(Embedding&MLP)
基础模型如图2左边所示,通常由Embedding层,Pooling层和Cocat层,MLP,Loss共同组成。

Embedding层
Embedding运算遵循表查找机制。
Pooling层和Concat层
不同用户有不同个数的行为。全连接层通常要求处理固定长度的输入,因此实践上经常将Embedding向量列表通过pooling层变换为固定长度的向量。pooling层通常有sum pooling和average pooling。
MLP
Wide&Deep,PNN,DeepFM都是聚焦于设计MLP结构来更好的提取信息。
Loss
4.3 DIN结构
通过pooling得到的表示向量对于给定用户都是相同的,而没有考虑候选广告是什么。这种情况下,有限维度的用户表示向量将成为表达用户多样兴趣的瓶颈。也不能简单的直接扩展维度,这样会带来过拟合及计算资源的消耗。
DIN通过考虑候选广告和历史行为的相关性来自适应的计算用户兴趣的表示向量。DIN结构如图2右边所示。除了引入新设计的局部激活单元外,和基础模型结构几乎一致。如等式3所示,根据给定的候选广告,通过有权重的sum pooling来自适应的计算用户表示
其中是长度为的用户的行为Embedding向量列表,是广告的Embedding向量。是前向网络,它的输出作为激活权重。除了两个输入Embedding向量,还增加了它们俩的外积来输入之后的网络,这是一种显式的知识用于相关性建模。
局部激活单元与NMT里的Attention方法类似,不同的是没有严格限制,目的是保留用户兴趣的强度。也就是说没有对的输出执行softmax进行归一化。
5 训练技巧
5.1 Mini-batch Aware Regularization
如图4所示,如果没有正则化的话,训练一个epoch后就会出现过拟合。所以得加上,但传统的L1正则和L2正则又是在每个batch中对所有的参数进行计算,这带来了相当大的计算量。本文提出了一种有效的mini-batch aware regularizer,仅计算每个batch中出现了稀疏特征的参数的L2范数。
5.2 数据自适应激活函数
PReLU公式如下
这里将定义为控制函数。如图3左边绘制了PReLU的控制函数。

如图所示,PReLU采用值为0的硬纠正点,这可能当每层的输入跟着不同的分布时是不合适的。基于此,本文设计了新的数据自适应激活函数,命名为Dice,公式如下:
它的控制函数如图3右边所示。在训练阶段,E[s]和Var[s]是每个mini-batch中输入的均值和方差,在测试阶段,E[s]和Var[s]是整个数据上的滑动平均。
Dice可以视为PReLu的正则化版本。关键理念是根据输入数据的分布自适应的调整校正点。此外,Dice更平滑的控制两个通道之间的切换。当,,Dice退化为PReLU。
6 实验
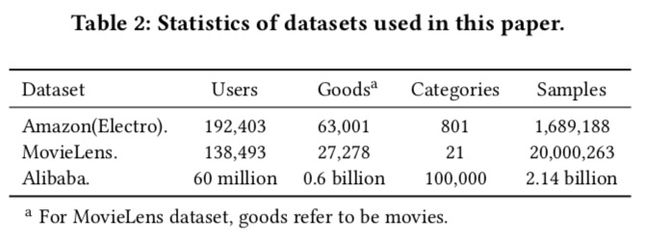
6.1 数据集和实验设置
6.2 比较方法
LR,Base Model,Wide&Deep,PNN,DeepFM
6.3 指标
用《Optimized Cost per Click in Taobao Display Advertising》和《Ups and Downs: Modeling the Vi- sual Evolution of Fashion Trends with One-Class Collaborative Filtering》中提到的用户加权的AUC来衡量效果,因为它和线上效果最相关,公式如下:
n表示用户个数,,分别表示对应第i个用户的曝光次数和AUC。
用这个公式来衡量模型的提升程度:
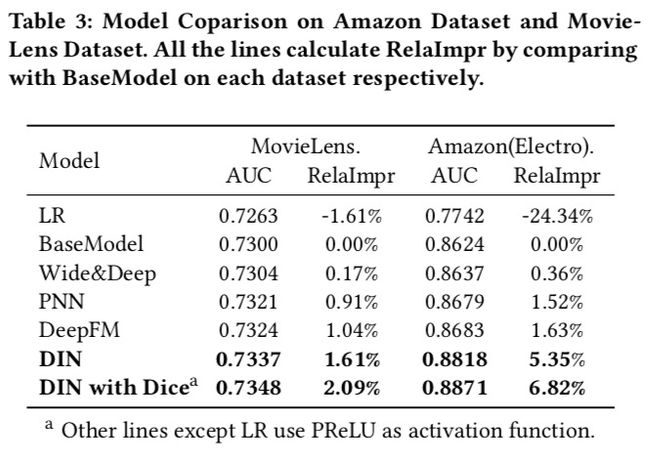
6.4 Amazon和MovieLens数据集上的模型比较结果
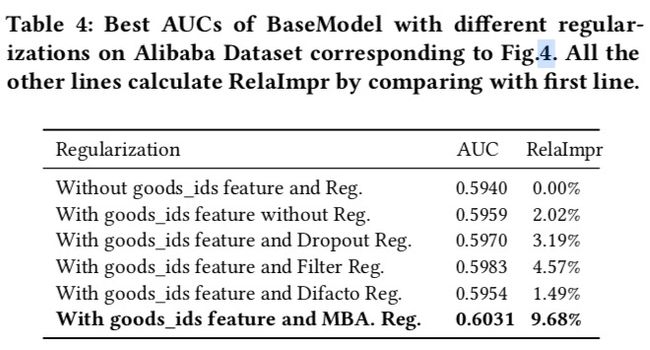
6.5 正则化效果
商品id类特征必须用,同时得配上正则化,不同正则化方法效果也稍微有些不同。

6.6 Alibaba数据集上的模型比较结果

6.7 在线A/B测试结果
为了处理这么大规模的在线服务,这一小节也介绍了一些工程上的优化技巧。
6.8 可视化DIN


七 小结
看了实验部分之后,对线上可以达到什么样的效果有了更好的理解。之前不知道AUC多好算好,这篇文章提供了一个参考,其实能有千分位的提升也是不容易的。另外,AUC没有想象中那么高,阿里巴巴数据集上也就是0.6的水平,不过这个AUC不是原始AUC,而是用户加权AUC。
素质四连
要解决什么问题
多样的用户兴趣与候选广告的相关性
用了什么方法解决
提出DIN网络,核心是用户行为序列与候选item做Attention
效果如何
用户加权AUC和线上效果均有提升,但绝对数值上没有那么大
还存在什么问题
因为每个候选item都要与行为序列上的所有item做Attention,当候选item量级很大时计算量上有点不可控,比方说不能用于召回层
算法背后的模式和原理
Attention思路的延续和应用
八 补充
王喆的机器学习笔记:推荐系统中的注意力机制——阿里深度兴趣网络(DIN)https://zhuanlan.zhihu.com/p/51623339