0、分类器热身,NextStep比较懒,直接看图

分类分类,先分解再分类,比如,疾病分类模型先将病情的表现信息进行分解成,体温信息,X光检查信息,运动习惯信息等分解,放入模型后,可以得出是健康、感冒、肺炎。
比较对下面简单句子分解分类:
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
docs = np.array(['How are you?', 'Fine, thank you.','And you?'])
print(count.fit_transform(docs))
bag = count.fit_transform(docs)
print(count.vocabulary_)
print(bag.toarray())
bag = count.fit_transform(docs)
print(count.vocabulary_)
{'how': 3, 'are': 1, 'you': 5, 'fine': 2, 'thank': 4, 'and': 0}
这三句话,出现了6个词语,按照字符先后编号 0到6

#对单词进行向量表示( 词频-逆向文件频率)
from sklearn.feature_extraction.text import TfidfTransformer
ftidf = TfidfTransformer()
print(ftidf.fit_transform(count.fit_transform(docs)).toarray())



来上代码 正式开始了
1、 数据准备
import pandas as pd
import numpy as np
df = pd.read_csv('movie_data.csv')

2、清理数据(H5多余标签清除,符号清除)
2.1导入数据后,这个时候发现我们可能发现数据不是很干净,有很多多余的H5标签,问号等标点符号,那这个时候我们需要多数据进行清理。
import re as pre #re是正则表达包
#正则表达式 过滤
def preprocessor(text):
text = pre.sub('<[^>]*>', '', text)
emotions = pre.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)', text)
text = pre.sub('[\W]+',' ', text.lower()) + ''.join(emotions).replace('-','')
return text
preprocessor(df.loc[0,'review'][-50:]
df['review'] = df['review'].apply(preprocessor)
3、拆解语汇(拆解语汇可以发现有多少正面的词汇和反面的词汇、并恢复自然状态)
#拆解字汇
def tokenizer(text):
return text.split()
tokenizer('Singer like singing and thus they sing')
#恢复单词自然状态
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
def tokenizer_porter(text):
return [porter.stem(word) for word in text.split()]
tokenizer_porter('Singer like singing and thus they sing')
举例:

4、去除停用语(the a 等一些无意义的词语)
#去除停用语
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop = stopwords.words('english')
#去掉无意义的垃圾词语 a and
pstr = [w for w in tokenizer_porter('Singer like singing and thus they sing') if w not in stop]

5、建构情感分析模型
5.1、先对数据进行分割(训练组、测试组)
#数据分割
X_train = df.loc[:25000,'review'].values
y_train = df.loc[:25000,'sentiment'].values
X_test = df.loc[25000:,'review'].values
y_test = df.loc[25000:,'sentiment'].values
5.2、网格搜索
#网格搜索 类似excel 数据一格一格,
from sklearn.grid_search import GridSearchCV
#把网格 做流水线的处理
#工具类导包
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(strip_accents = None, lowercase = False,preprocessor = None)
#设置网格参数 (会用到上面举例的方法)
param_grid = [{'vect__ngram_range': [(1,1)], #一个格子一个格子的爬
'vect__stop_words': [stop, None],#遇到stop_words 去掉
'vect__tokenizer': [tokenizer,tokenizer_porter],#拆解词汇 分解到自然状态
'clf__penalty': ['l1', 'l2'],#一口气 爬多少数据
'clf__C': [1.0, 10.0, 100.0]},
{'vect__ngram_range': [(1, 1)],
'vect__stop_words': [stop, None],
'vect__tokenizer': [tokenizer, tokenizer_porter],
'vect__use_idf': [False],#遇到专有词汇不用管
'vect__norm': [None],#遇到自然词汇不用管
'clf__penalty': ['l1', 'l2'],'clf__C': [1.0, 10.0, 100.0]}
]
lr_tfidf = Pipeline([('vect', tfidf),
('clf',LogisticRegression(random_state=0))])#在流水线 好好怕不用跳
gs_lr_tfidf = GridSearchCV(lr_tfidf, param_grid,
scoring='accuracy',#精确度
cv=5, verbose=1,
n_jobs=-1)#从开头到最后
#时间很长
gs_lr_tfidf.fit(X_train, y_train) #模型喂养
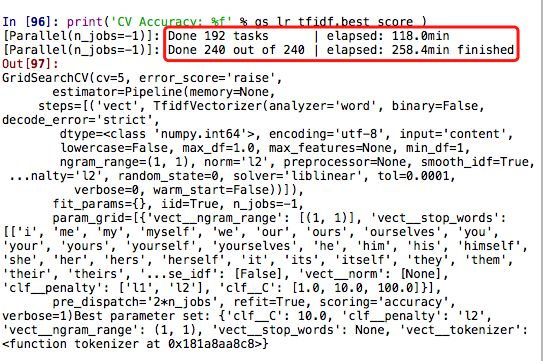
print('Best parameter set: %s' % gs_lr_tfidf.best_params_)
print('CV Accuracy: %f' % gs_lr_tfidf.best_score_)
model = gs_lr_tfidf.best_estimator_ #最佳模型跑一下 测试数据
print('Test Accuacy: %f' % model.score(X_test, y_test))
结果: