perf
perf 的功能
- perf 可以用来分析 CPU cache、CPU 迁移、分支预测、指令周期等各种硬件事件;
- perf 也可以只对感兴趣的事件进行动态追踪
- 先对事件进行采样,然后再根据采样数,评估各个函数的调用频率
perf例子
1.内核函数 do_sys_open 的例子
很多人只看到了 strace 简单易用的好处,却忽略了它对进程性能带来的影响。
从原理上来说,strace 基于系统调用 ptrace 实现,这就带来了两个问题:
- 由于 ptrace 是系统调用,就需要在内核态和用户态切换。当事件数量比较多时,繁忙的切换必然会影响原有服务的性能;
- ptrace 需要借助 SIGSTOP 信号挂起目标进程。这种信号控制和进程挂起,会影响目标进程的行为。
在性能敏感的应用(比如数据库)中,我并不推荐你用 strace (或者其他基于 ptrace 的性能工具)去排查和调试。
在 strace 的启发下,结合内核中的 utrace 机制, perf 也提供了一个 trace 子命令,是取代 strace 的首选工具。
相对于 ptrace 机制来说,perf trace 基于内核事件,自然要比进程跟踪的性能好很多。
第二个 perf 的例子是用户空间的库函数
# 为/bin/bash添加readline探针 $ perf probe -x /bin/bash 'readline%return +0($retval):string’ # 采样记录 $ perf record -e probe_bash:readline__return -aR sleep 5 # 查看结果 $ perf script bash 13348 [000] 93939.142576: probe_bash:readline__return: (5626ffac1610 <- 5626ffa46739) arg1="ls" # 跟踪完成后删除探针 $ perf probe --del probe_bash:readline__return
eBPF 和 BCC
eBPF 就是 Linux 版的 DTrace,可以通过 C 语言自由扩展(这些扩展通过 LLVM 转换为 BPF 字节码后,加载到内核中执行)。
下面这张图,就表示了 eBPF 追踪的工作原理:
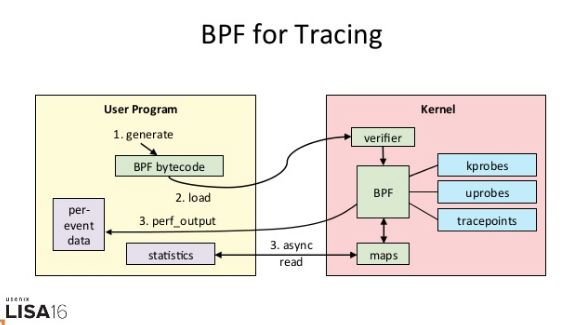
eBPF 的执行需要三步:
- 从用户跟踪程序生成 BPF 字节码;
- 加载到内核中运行;
- 向用户空间输出结果
SystemTap 和 sysdig
SystemTap 也是一种可以通过脚本进行自由扩展的动态追踪技术。
在 eBPF 出现之前,SystemTap 是 Linux 系统中,功能最接近 DTrace 的动态追踪机制。不过要注意,SystemTap 在很长时间以来都游离于内核之外(而 eBPF 自诞生以来,一直根植在内核中)。
所以,从稳定性上来说,SystemTap 只在 RHEL 系统中好用,在其他系统中则容易出现各种异常问题。
当然,反过来说,支持 3.x 等旧版本的内核,也是 SystemTap 相对于 eBPF 的一个巨大优势。s
ysdig 则是随着容器技术的普及而诞生的,主要用于容器的动态追踪。
sysdig 汇集了一些列性能工具的优势,可以说是集百家之所长。
这个公式来表示 sysdig 的特点: sysdig = strace + tcpdump + htop + iftop + lsof + docker inspect
如何选择追踪工具
- 在不需要很高灵活性的场景中,使用 perf 对性能事件进行采样,然后再配合火焰图辅助分析,就是最常用的一种方法;
- 而需要对事件或函数调用进行统计分析(比如观察不同大小的 I/O 分布)时,就要用 SystemTap 或者 eBPF,通过一些自定义的脚本来进行数据处理