| 这个作业属于哪个课程 | 2020春 W班 |
|---|---|
| 这个作业要求在哪里 | 2020软工实践寒假作业(2/2)————疫情统计 |
| 这个作业的目标 | 学习GitHub的使用、考察需求分析能力、实现疫情统计程序 |
| 作业正文 | 2020软工实践寒假作业二(疫情统计) |
| 其他参考文献 | GitHub教程、单元测试和回归测试、工程师的能力评估和发展··· |
一、我的GitHub仓库地址
疫情统计程序
二、阅读《构建之法》
第一章从软件开发的不同阶段为引子,引出什么是软件工程,并从软件的特殊性以及软件工程与其他计算机学科的联系点和侧重点讲起,介绍了软件工程的概论知识。
在第二章中,书本介绍了单元测试、回归测试与效能分析的相关知识,令人恍然大悟,原来之前使用程序时用语句输出变量的值来调试程序根本不是正确的程序测试方式,并且自己之前写程序也从没关注过效能分析的事。而接下来对个人开发流程的介绍也让我明白了什么是科学、正确的开发流程。
第三章写到软件工程师的技能与职业的成长,让我意识到自身离成为一名合格的软件工程师还有很长的路要走。并让我对自身未来的职业规划与学习路线有了更加清晰的认识。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 1180 | 1280 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 240 |
| Design Spec | 生成设计文档 | 40 | 60 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 360 | 600 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 300 | 180 |
| Reporting | 报告 | 240 | 230 |
| Test Report | 测试报告 | 180 | 150 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 1480 | 1550 |
三、解题思路
(题目请看页首作业正文)
(1)做前准备
软件工程实践每次的作业需求都很长,因此每次完成作业的首要任务就是反复看作业需求,看它个五六遍,再将作业的要求列出一个要求列表,最后再开始着手实现,切勿急急忙忙就上头打代码!
本次作业首先要阅读《构建之法》的前三章,要先对软件工程的相关概念、个人开发流程等相关知识有一定的认识和理解,之后才能合理运用到此次作业设计中。
此外,要学习此次作业涉及到的知识,包括Git&GitHub的使用、当下互联网大厂的主流代码规范、单元测试与回归测试的使用等知识,这些资料老师都很贴心地提供了,学习完这些再自己搜索阅读一些相关的资料足矣。
考虑到此次作业要用到Java语言,上一次写Java程序恐怕已是很久远的事了,因此有必要重新复习下Java的基础知识,特别是文件的读取、相关的数据结构以及正则表达式的使用等。
有了这些知识储备,现在到了真正运用到实践中的时候了。
(2)分析题目
此次作业的主题程序大概可概括成:通过控制台窗口输入命令执行程序,程序能够根据所输入命令的不同参数,对相关目录下的日志文件进行统计,并输出到所指定的输出文件中。故要求实现的功能主要可分为四步:
1. 处理命令行所输入的参数
2. 读入文件内容
3. 对内容进行相关处理
4. 输出内容到指定文件
四、设计实现过程
设计相关数据结构,采用面向对象的分析方法,可提取出五个对象:
1. CommandParser:解析命令行输入的命令
2.CommandRun:执行解析完的命令
3. FileInputUtils:读取文件内容
4.InfoParser:处理读取的文件内容
5.FileOutputUtils:输出文件内容
五个对象间的活动图如下:
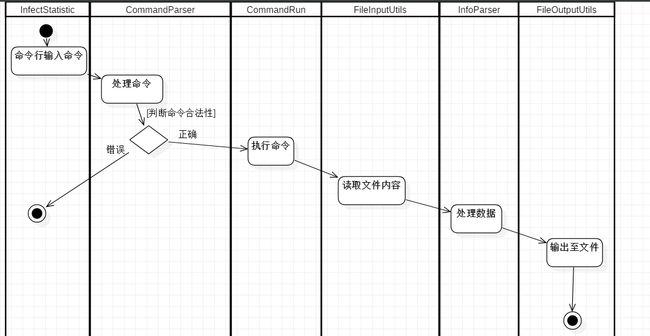
五、代码说明
存储各地区疫情信息的数据结构,用哈希表来存储
class InfectedArea{
public int infectedNum = 0;
public int potentialNum = 0;
public int curedNum = 0;
public int deadNum = 0;
}
class InfectedMap{
//Key存储感染地区的名字,Value存储感染地区的人数信息
HashMap map;
public InfectedMap() {
map = new HashMap();
String wholeCountry = "全国";
InfectedArea countryArea = new InfectedArea();
map.put(wholeCountry, countryArea);
} 主函数:cmParser解析命令,commandRun执行命令即结束。
public static void main(String[] args){
CommandParser cmParser = new CommandParser(args);
CommandRun commandRun = new CommandRun(cmParser);
commandRun.runCommand();
}
CommandRun的runCommand方法运行,先创建存储省份疫情信息的map表,再创建reader和writer文件读写工具,之后解析文件路径,对省份进行排序,写入文件。
public void runCommand() {
InfectedMap map = new InfectedMap();
FileInputUtils reader = new FileInputUtils();
FileOutputUtils writer = new FileOutputUtils();
try {
reader.parseFile(parser.srcPath, map, hasDate, parser.dateString);
map.sortByProvince();
writer.writeFile(parser.dstPath, map, hasType, parser.typeList, hasProvince, parser.provinceList);
} catch (IOException e) {
e.printStackTrace();
}
}CommandParser类数据结构如下,解析命令时进行遍历匹配
class CommandParser{
//存放-log
public String srcPath = "";
//存放-out
public String dstPath = "";
//存放-date
public String dateString = "";
//存放-type
public boolean hasType = false;
public List typeList = new ArrayList();
//存放-province
public boolean hasProvince = false;
public List provinceList = new ArrayList();
public CommandParser(String[] args) {
for (int i = 1; i < args.length; i++){
if ( args[i].equals("-log")) {
i++;
this.srcPath = args[i];
}else if (args[i].equals("-out")){
i++;
this.dstPath = args[i];
}else if (args[i].equals("-date")){
i++;
this.dateString = args[i];
} else if (args[i].equals("-type")){
i++;
this.hasType = true;
int index = i;
for (int j = 0; j < args.length - index ; j++) {
this.typeList.add(args[i]);
if (args[i].equals("-province")) {
i --;
break;
}
i++;
}
if (typeList.size() == 4) {
hasType = false;
}
} else if (args[i].equals("-province")){
//若含有province参数,则要对其后参数进行记录
this.hasProvince = true;
i++;
int index = i;
for (int j = 0; j < args.length - index; j++) {
this.provinceList.add(args[i]);
i++;
}
}
}
}
} 对文件夹下的文件进行处理,重写compare方法,并按照时间顺序进行排序。
判断给定日期是否超出最新文件日期,若超出则输出错误信息。
public void parseFile(String dirPath, InfectedMap map, boolean hasDate, String dateString) throws IOException{
//获取文件目录
File dirFile = new File(dirPath);
//获取目录下所有*.log.txt文件
File[] logFiles = dirFile.listFiles();
//存放所有的文件名
List filesName = new ArrayList();
List filesList = Arrays.asList(logFiles);
//对filesList根据文件名按照时间进行排序
//覆写compare方法
Collections.sort(filesList, new Comparator() {
@Override
public int compare(File o1, File o2) {
return o1.getName().compareTo(o2.getName());
}
});
for (int i = 0; i < filesList.size() ;i++) {
filesName.add(filesList.get(i).toString());
}
String srcPath = "";
//改成绝对路径
String absolutePath = "";
if (hasDate) {
absolutePath = dirPath + dateString + ".log.txt";
}
String lastFile = filesName.get(filesName.size() - 1);
int len = lastFile.length();
String lastDateString = lastFile.substring(len - 18, len -8 );
if (lastDateString.compareTo(dateString) < 0) {
System.out.println("!错误:输入date参数比最新log文件更新!");
}
for (int i = 0; i 0) {
break;
}
}
inputFile(srcPath, map);
}
} 按照给定省份表进行排序,也是覆写了compare方法
public void sortByProvince() {
List regulationOrder = Arrays.asList(
"全国", "安徽", "北京",
"重庆", "福建", "甘肃", "广东", "广西", "贵州",
"海南", "河北", "河南", "黑龙江","湖北", "湖南",
"吉林", "江苏", "江西", "辽宁", "内蒙古","宁夏",
"青海", "山东", "山西", "陕西", "上海", "四川",
"天津", "西藏", "新疆", "云南", "浙江" );
Set> set = map.entrySet();
List> list = new ArrayList<>();
//把set加到list中去
Iterator> it = set.iterator();
while(it.hasNext()) {
Entry entry = it.next();
list.add(entry);
}
Collections.sort(list, new Comparator>() {
@Override
public int compare(Entry o1, Entry o2) {
String value1 = o1.getKey();
String value2 = o2.getKey();
int index1 = regulationOrder.indexOf(value1);
int index2 = regulationOrder.indexOf(value2);
return index1-index2;
}
});
//对list排序完成后放入LinkedHashMap即可。
HashMap map2 = new LinkedHashMap<>();
for (Entry entry : list) {
map2.put(entry.getKey(), entry.getValue());
map = map2;
}
} 六、单元测试截图和描述
单元测试函数写了对主函数的测试以及一些关键方法的测试。
对命令解析的commandParser方法进行测试,通过设置带有不同参数的命令查看是否得到正确的解析结果



当-type后四个类型都在时,则当作不存在-type参数

测试对省份进行排序,通过指定输入序列和输出序列进行判断,可改变输入的省份来多次测试
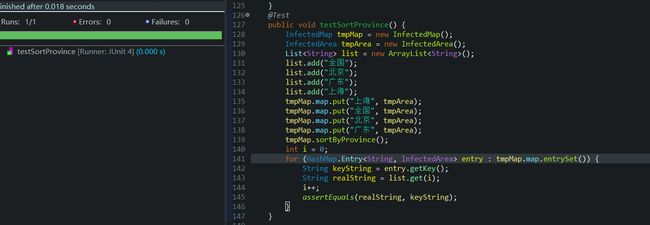
测试判断文件日期功能,当输入的日期超过最新文件时,输出错误信息


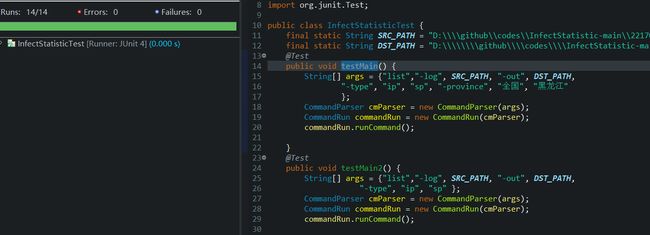
以及对主函数的一些测试,测试都以通过。
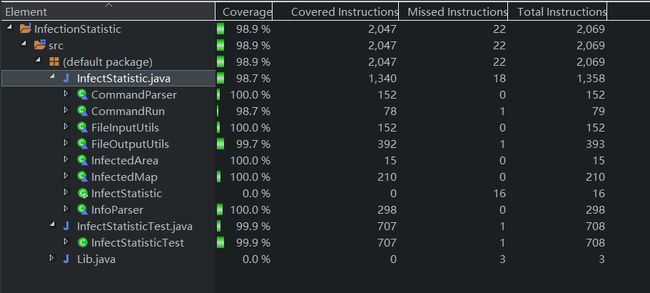
七、单元测试覆盖率优化和性能优化
单元测试覆盖率截图如下:未覆盖的为部分异常抛出部分错误信息输出代码
性能测试截图如下:
12:14分左右运行程序
暂未找到优化方法。。。对程序的优化设计这一能力实属欠缺,有待努力。
八、代码规范链接
Java代码规范(参考阿里巴巴Java编程规范)
九、心路历程和收获
本次实践作业令我收益匪浅。不仅学习了Git与GitHub的相关用法,第一次接触到团队代码管理的方法,也算是告别了以往用QQ传源文件给别人的陋习。通过阅读《构建之法》前三章的内容,我也对软件工程的相关概念有了一个大致的认识,第一次接触到PSP表格,算是科学地、有规划地进行软件项目开发与管理的第一步,也对怎样成为一名合格的软件工程师有了更深刻的认识。此次作业中还学习了单元测试、效能分析的相关知识,明白了正确的软件测试与调试方法。此外,还学习了互联网大厂的主流代码风格,发现了自身代码风格的不规范的问题。
虽然学习过程中遇到了很多的打击,经常无法透彻地理解相关资料所说的是什么意思,编程过程中也遇到了各种各样的bug,比如为什么在Eclipse能好好地输出但一到命令行就崩溃,为什么命令行输出中文总是乱码等等问题,不过还在老师的帮助和反复查找相关资料,总算是解决了问题。也为如何实现相关要求绞尽脑汁过,让我在内心感叹了无数遍 “我是什么垃圾我是什么垃圾” ,就经常特别没用成就感,全是挫败感。但是,不管怎么说还是比做作业之前的自己有一点点进步,有进步就是好事,回头看看这次作业的收获还是很大的,那就要再接再励。
十、技术路线图相关的5个仓库
| 名称&链接 | 简介 |
|---|---|
| EasyHadoop | 类似【一键OpenStack】,介绍个好的快速部署Hadoop工具:能够在一个网页上对Hadoop集群进行安装,重启,修改配置文件,查看log等功能。,由前暴风影音数据团队修湘调研,向磊编写。 |
| Apache Spark | Apache Spark是一个为实时大数据分析所设计的开源数据处理引擎。目前Spark的大用户有雅虎、腾讯和百度,使用Spark处理的数据在PB级别,集群节点数目也超过8000。Apache Spark是GitHub上最大的数据处理项目之一,有超过750名开发人员都曾对项目做出过贡献。 |
| Apache Storm | Apache Storm的设计针对的是流式数据,不过对于大数据的实时分析它也是很可靠的计算系统。它同样是一个开源项目而且开发人员可以使用所有的主流高级语言。Apache Storm主要用于以下应用:在线机器学习、连续计算、实时分析、ETL、分布式RPC。Apache Storm有配置方便、可用性高、容错性好及扩展性好等诸多优点,处理速度也极快,每个节点每秒可以处理数百万个tuple。 |
| Apache Mahout | 我们可以使用Apache Mahout来快速创建高效扩展性又好的机器学习应用。Mahout结合了诸如H2O算法、Scala、Spark和Hadoop MapReduce等模块,为开发人员提供了一个构建可扩展算法的环境。 |
| Hive | Hive是基于hadoop的一个数据仓库工具,可以将结构化数据文件映射为一张数据库表,并提供类SQL查询功能. |