一、总览和相关链接
| 这个作业属于哪个课程 | 2020春|W班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2)要求 |
| 这个作业的目标 | 学习GitHub的使用,能够对程序进行合理的测试, 使用PSP表格协助个人开发 |
| 作业正文 | 我的第02次作业 |
| 其他参考文献 |
本次任务相关链接
- 作业的主仓库 疫情统计-主仓库
- 我的作业仓库 SilverBay的主仓库
- 编程规范 SilverBay的编程规范
特别说明
一开始不太熟悉GitHub的分支使用方法,原先将助教仓库fork到个人仓库后直接在main分支进行相关操作。当程序基本完善后,后面发觉不太合适就直接删除了个人仓库(现在就是后悔,十分后悔!)并重新fork了助教的仓库,创建了新的分支myProgram。因此如果发现我一天之内就进行了所有的commit不要惊讶,我已经尽力地拿着最终版程序还原我从零开始开发过程,因此commit内容会不够细致,造成的不便我感到肥肠抱歉!!!
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 60 |
| Estimate | 估计这个任务需要多少时间 | 45 | 60 |
| Development | 开发 | 1565 | 1705 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 240 |
| Design Spec | 生成设计文档 | 45 | 70 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| Design | 具体设计 | 150 | 150 |
| Coding | 具体编码 | 720 | 750 |
| Code Review | 代码复审 | 120 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 240 | 360 |
| Reporting | 报告 | 350 | 400 |
| Test Report | 测试报告 | 30 | 60 |
| Size Measurement | 计算工作量 | 20 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 300 | 330 |
| 合计 | 1960 | 2165 |
整个任务完成后,发现对新知识的应用能力和程序的纠错能力较差,虽然学习新知识耗时和预期差不多,但是到了设计文档的时候需要用到新知识地方,比如设计模式,不能很快的把他们具体为和本任务相关的类和方法。虽然单元测试和编码同步进行,但是我修改还是花了大概6个小时的时间,超出了预期的一半时间,说明我的debug能力还有待提高。
三、解题思路
涉及内容小结
- 数据源为日志文件,根据文本内容处理数据并生成结果日志,涉及文件读写操作、字符串处理操作
- 参数配置由命令行指定,涉及程序运行的命令行字符串数组的处理
- 日志文件要有序、省份输出要按照拼音顺序,涉及到排序的实现
- 有省份、患者、命令、命令的选项和参数等实体,涉及实体类及其属性和方法的表示
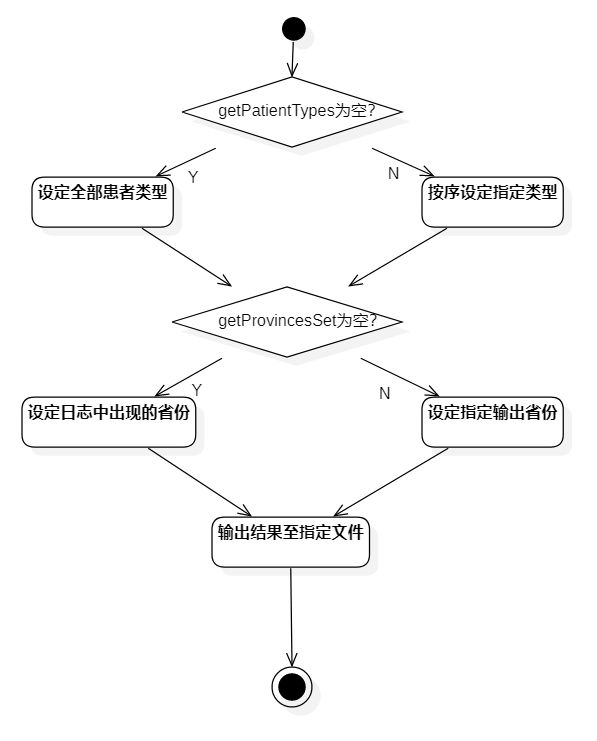
程序运行流程

处理命令
任务要求的命令格式如下
- list命令
- -log [必须] 指定一个参数,参数为源日志文件所在文件夹路径
- -out [必须] 指定一个参数,参数为运行结果的输出文件路径
- -date [可选] 指定一个参数,参数为统计的截止日期,不指定则默认为所提供日志最新的一天
- -type [可选] 指定至多4个参数,可指定的参数如下,空格分割,不指定该项默认会列出所有情况
- ip 输出感染患者
- sp 输出疑似患者
- cure 输出被治愈患者
- dead 输出死亡患者
- -province [可选] 指定多个参数,空格分割,每个参数为要输出的省份名称,不指定则只输出全国和日志中出现的省份信息
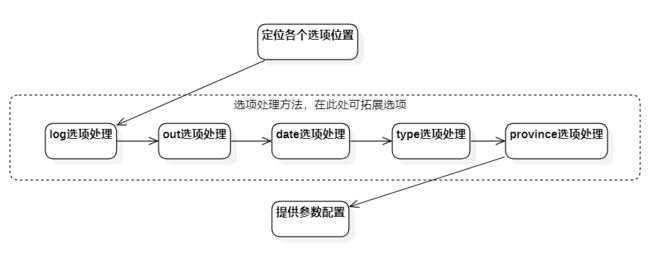
命令行参数的处理按照以下步骤实现
- 首先扫描一次所有命令行参数,记录每个选项在数组中的索引并保存在数组中
- 依次执行log、out、date、type、province的处理方法,并保存结果
- 将命令行处理后的所有数据提供给需要获得配置数据的类
扫描文件
- 从命令行参数处理类获取源文件文件夹,要求日期等数据
- 根据输入的日期参数筛选源文件夹下所需处理的文件
处理数据
- 生成文本处理的责任链处理类
- 读取源文件夹,将每行文本递交给责任链类处理
- 责任链类处理单行文本,处理患者变化情况写入省份实体类
输出结果
- 从命令参数处理类获取目标文件路径、输出类型、省份列表
- 根据参数配置将数据格式化输出到目标路径
四、实现过程
患者类型和list命令选项枚举类型的引入,给数据表示和处理以及今后的拓展带来了极大的便利。例如,解析单行文本完成要处理数据之后,只需将正则表达式匹配出的患者类型和人数传入即可实现数据修改,无需分支语句判断,需要拓展时,只需要在枚举类中新增属性,并修改单行文本处理规则即可,该方法示例如下
//某地人数发生变化时,全国人数也要进行同步变化
public void alterLocalNum(PatientType patientType, int changedNum) {
localNumbers[patientType.ordinal()] += changedNum;
nationalNumbers[patientType.ordinal()] += changedNum;
}程序类图
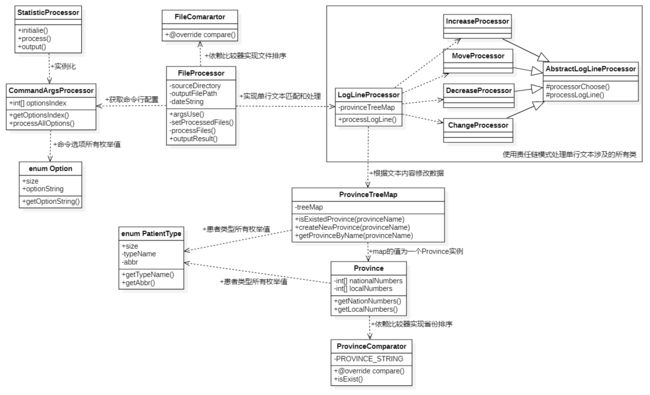
命令行参数处理
按照之前提到的程序运行流程实现的命令行参数处理,如下图
![]()
扫描文件
首先使用CommandArgsProcessor的Getter获得源文件夹路径、目标文件路径以及日期字符串,先获得所有文件,再根据日期串筛选掉不满足要求的文件。将满足要求的文件添入fileTreeSet中,给下一步处理文件使用。流程图如下:
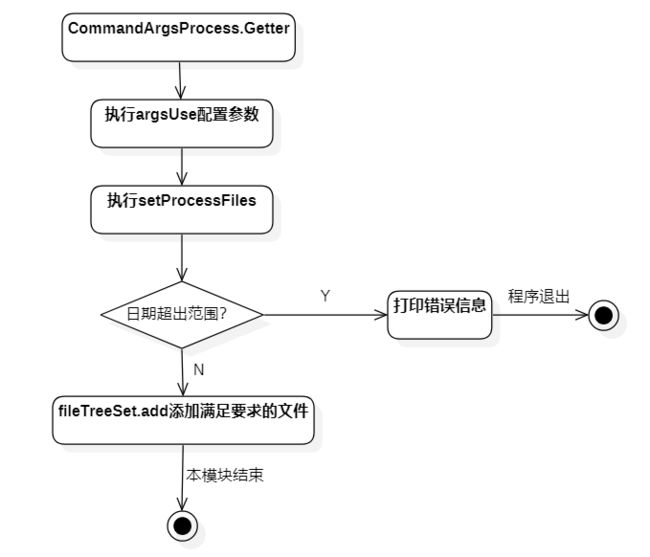
处理文件
将文本按行读入,交给logLineProcessor责任链处理
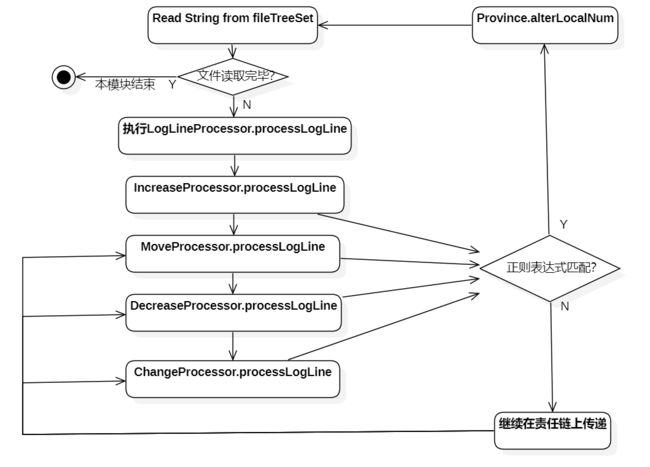
输出结果
-type若指定,则患者类型列表List
五、代码说明
枚举类型
患者类型和list命令选项的枚举类型定义如下,可以很方便的通过Getter获得名称,枚举类型声明是顺序就决定了其的序号位次,可以利用这一特性很方便的存储和修改对应的数据。例如通过localNumbers[PatientType.CURE.ordinal()] += num;来实现修改
enum PatientType {
INFECTION("感染患者","ip"),
SUSPECTED("疑似患者","sp"),
CURE("治愈","cure"),
DEAD("死亡", "dead");
public static final int size = PatientType.values().length;
private String typeName;
private String abbr;
...
PatientType(String typename, String abbr) {...}
public String getTypeName() {...}
public String getAbbr() {...}
public static PatientType getTypeByAbbr(String abbr) {...}
}enum Option {
LOG("-log"), OUT("-out"),
DATE("-date"), TPYE("-type"),
PROVINCE("-province");
private String optionString;
public static final int size = Option.values().length;
Option(String optionString) {...}
public String getOptionString() {...}
public static Option getOptionByString(...) {...}
}比较器
本次任务对源文件顺序和省份信息输出顺序有严格的要求,因此实现比较器来对它们进行排序
class ProvinceComparator implements Comparator {
private static final String PROVINCE_STRING = "全国 安徽 北京 重庆 福建 "
+ "甘肃 广东 广西 贵州 海南 河北 河南 黑龙江 湖北 湖南 吉林 江苏 江西 "
+ "辽宁 内蒙古 宁夏 青海 山东 山西 陕西 上海 四川 天津 西藏 新疆 云南 浙江";
@Override
public int compare(String s1, String s2) {
return PROVINCE_STRING.indexOf(s1) - PROVINCE_STRING.indexOf(s2);
}
} class FileComparator implements Comparator {
@Override
public int compare(File file1, File file2) {
return file1.getName().compareTo(file2.getName());
}
} 命令行处理
选项定位
充分利用枚举类型特性减少编码复杂性
private void getOptionIndex() {
Option option;
for (int i = 0; i < args.length; i++) {
if( (option = Option.getOptionByString(args[i])) != null) {
optionsIndex[option.ordinal()] = i;
}
}
}选项处理,以-type选项处理为例
利用定位信息,向patientTypes中填充数据
private void typeOptionProcess() {
patientTypes = new LinkedList<>();
int index = optionsIndex[Option.TPYE.ordinal()];
//-tpye参数中指令的类型按照枚举变量的声明顺序存入types数组中,未指定的类型则为null
if(index != 0) {
PatientType patientType;
for(int i = index + 1; i < args.length; i++) {
if((patientType = PatientType.getTypeByAbbr(args[i])) != null) {
patientTypes.add(patientType);
}
else {
break;
}
}
}
//未指定-type命令,则获得所有种类
else {
patientTypes = Arrays.asList(PatientType.values());
}
}文件处理
文件过滤
主要通过文件名字符顺序判断日期是否超出范围;本次任务错误处理不是重点,因此没有自定义异常类,使用异常抛出捕获的方式结束程序
private void setProcessedFiles() {
if(dateString == null) {
fileTreeSet.addAll(Arrays.asList(sourceDirectory.listFiles()));
}
else {
for(File file : sourceDirectory.listFiles()) {
if(file.getName().compareTo(dateString + SUFFIX) <= 0)
fileTreeSet.add(file);
}
if(fileTreeSet.size() == sourceDirectory.listFiles().length &&
fileTreeSet.last().getName().compareTo(dateString + SUFFIX) < 0) {
System.out.println("日期超出范围");
System.exit(1);
}
}
}文本处理
使用责任链模式进行处理。首先是抽象类AbstractLogLineProcessor,每个类通过继承此类实现一种情况的处理方法。该类被IncreaseProcessor、MoveProcessor、DecreaseProcessor和ChangeProcessor继承,他们的对应处理情况如下:
- IncreaseProcessor 处理新增患者情况
- MoveProcessor 处理患者流动情况
- DecreaseProcessor 处理患者人数减少(被治愈或不幸死亡)情况
- ChangeProcessor 处理患者类型变化(疑似患者确诊或者被排除)情况
抽象基类
abstract class AbstractLogLineProcessor {
public static String INCREASE = "新增.*人";
public static String MOVE = "流入.*人";
public static String DECREASE = "[死亡|治愈].*人";
public static String CHANGE = "[确诊|排除].*人";
protected static ProvinceTreeMap provinceTreeMap;
protected Pattern pattern;
protected AbstractLogLineProcessor nextProcessor;
public static void setProvinceTreeMap(ProvinceTreeMap provinceTreeMap) {
AbstractLogLineProcessor.provinceTreeMap = provinceTreeMap;
}
//将继承本抽象类的所有处理类链接成责任链
public void setNextProcessor(AbstractLogLineProcessor nextProcessor) {
this.nextProcessor = nextProcessor;
}
abstract protected void processLogLine(String logLine);
//需求在责任链上的选择和传递
public void processorChoose(String logLine) {
if(pattern.matcher(logLine).find()) {
processLogLine(logLine);
}
else if(nextProcessor != null) {
nextProcessor.processorChoose(logLine);
}
}
}子类,仅展示ChangeProcessor
class ChangeProcessor extends AbstractLogLineProcessor {
ChangeProcessor(String regex) {
pattern = Pattern.compile(regex);
}
@Override
protected void processLogLine(String logLine) {
boolean isConfirmed = logLine.contains("确诊");
String[] lineStrings = logLine.split(" ");
String provinceName = lineStrings[0];
int changedNum = Integer.parseInt( lineStrings[3].replace("人", "") );
if(!provinceTreeMap.isExistedProvince(provinceName)) {
provinceTreeMap.createNewProvince(provinceName);
}
Province province = provinceTreeMap.getProvinceByName(provinceName);
province.alterLocalNum(PatientType.SUSPECTED, (-1) * changedNum);
if(isConfirmed) {
province.alterLocalNum(PatientType.INFECTION, changedNum);
}
}
}输入输出
本次任务要求编码UTF-8,为了避免编码问题带来的意外情况,将读写流编码设置为UTF-8,而不再是依赖环境选择编码。根据patientTypes表和provinceSet进行相应格式的输出。以下仅展示输出模块的代码
public void outputResult() {
fileOutputStream = new FileOutputStream(commandArgsProcessor.getOutputFilePath());
bufferedWriter = new BufferedWriter(new OutputStreamWriter(fileOutputStream,StandardCharsets.UTF_8));
outputNationData();//先输出全国数据
Iterator iterator = provinceSet.iterator();
try {
while (iterator.hasNext()) {
String provinceName = iterator.next();
Province province = provinceTreeMap.getProvinceByName(provinceName);
bufferedWriter.write(provinceName);
for (PatientType patientType : patientTypes) {
bufferedWriter.write(" " + patientType.getTypeName());
bufferedWriter.write(province.getLocalNumbers()[patientType.ordinal()] + "人");
}
bufferedWriter.newLine();
}
bufferedWriter.write("// 该文档并非真实数据,仅供测试使用\n");
bufferedWriter.close();
fileOutputStream.close();
}
catch (IOException exc) {
System.out.println(Arrays.toString(exc.getStackTrace()));
System.exit(1);
}
} 六、优化及性能测试
测试工具
Junit、Intellij IDEA
优化
Make it run, make it right, make it fast. 在开发的初期,为了先实现基本功能使得程序能够正常运行并得出正确结果,我的字符串处理并没有使用责任链模式,而是冗长的if-else语句块,字符处理类设计的不够合理。我之前实现的LogLineProcessor如下:
class LogLineProcessor {
private static String INCREASE = "新增.*人";
private static String MOVE = "流入.*人";
private static String DECREASE = "[死亡|治愈].*人";
private static String CHANGE = "[确诊|排除].*人";
private ProvinceTreeMap provinceTreeMap;
private Pattern increasePattern = Pattern.compile(INCREASE);
private Pattern movePattern = Pattern.compile(MOVE);
private Pattern decreasePattern = Pattern.compile(DECREASE);
private Pattern changePattern = Pattern.compile(CHANGE);
LogLineProcessor(ProvinceTreeMap provinceTreeMap) {
this.provinceTreeMap = provinceTreeMap;
}
public void processLogLine(String logLine) {
if(increasePattern.matcher(logLine).find())
increaseProcess(logLine);
else if(movePattern.matcher(logLine).find())
moveProcess(logLine);
else if(decreasePattern.matcher(logLine).find())
decreaseProcess(logLine);
else if(changePattern.matcher(logLine).find())
changeProcess(logLine);
}
private void increaseProcess(String logLine) {...}
private void moveProcess(String logLine) {...}
private void decreaseProcess(String logLine) {...}
private void changeProcess(String logLine) {...}
}测试函数
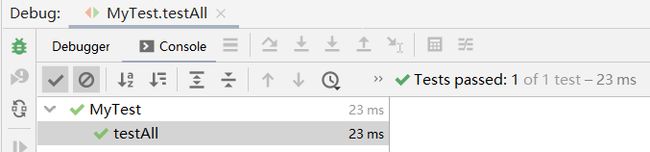
@Test
public void testAll() {
String[] args = {"list", "-out", "C:/Java/testOutPut01.txt",
"-log", "C:\\Users\\123\\IdeaProjects\\InfectStatistic-main-master\\example\\log",
};
StatisticProcessor sp = new StatisticProceesor(args);
sp.initialize();
sp.process();
sp.output();
}优化前测试结果
优化后的代码见上述代码说明,优化后的测试结果如下

可见在分支很多的情况下,不宜用if-else或者switch来编写处理模块,这样不仅代码结构冗长,可读性差,也缺乏可拓展性,效率还不高。设计模式对于开发的重要性便可见一斑。在此之前,我都没有设计模式的概念,只是有一些编程思维而已,技术积累还是太少。
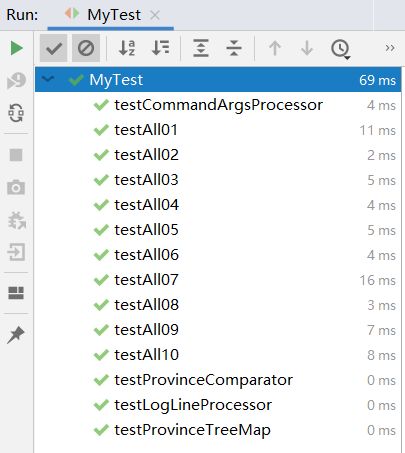
性能测试
对主要类进行单元测试、基本完成后对程序进行全面测试,测试结果如下
覆盖率测试,Lib内容为空所以覆盖率是0
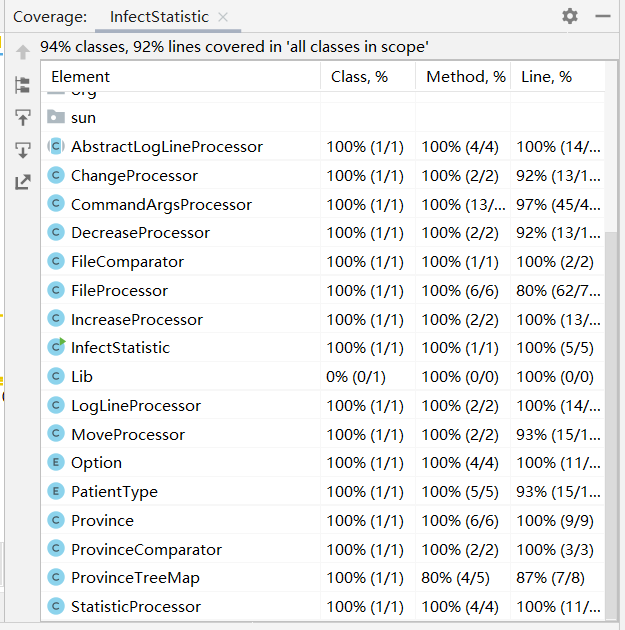
FileProcessor覆盖率低是一个是因为没有进入日期超出范围代码块分支,还有一个是字符流的异常处理代码块没有被执行。
七、心路历程和收获
第一次看到作业要求,束手无策,感觉不知从何下手,作业刚布置的几天一直没有去做,只是在碎片化的学习相关技术。作业指导发布后,才开始正式进入状态,跟随着引导思路逐渐清晰起来。这暴露了我对陌生的技术和新问题的分析处理能力不够强的缺点。先画出大概类图和程序执行流程图后,我明确了编码的方向,也确定了数据结构的选用。今后会注重培养遇到问题的分析解决能力,学习更多的技术。
令我没有想到的是,在有了类图和流程图的指导后,我的编码过程目的十分明确,没有出现编写好一大段代码后又觉得设计不合理全部删掉重新的情况。之前我的编码都是小项目、小程序,在正式编码之前也懒得去画类图流程图等,都是直接上手敲代码,想到什么就实现什么,所以经常会出现推翻又重写的情况,编码效率不高。之前也从未使用过PSP进行任务开发的估计和规划,本次任务完成下来,暴露出了我修改代码能力和文档编写能力的欠缺,这两个都比预计的超出了许多时间。

Git及GitHub的学习和使用让我了解程序项目的管理知识。之前从未有过版本控制的概念,都是改完直接保存,备份就更谈不上。我对接下来GitHub团队使用的课程十分期待,这样我们能一改往前的低效合作、解决代码管理的困难,更加有利于团队合作和中大型项目的开发。
八、技术仓库
1. Spring Framework
https://github.com/wdrt68/spring-framework
Spring框架的官方仓库,涵盖了Spring框架的所有历史版本,开源项目所有代码完全公开,实时更新说明文档和使用手册。
2. Spring Boot
https://github.com/wdrt68/spring-boot
Spring Boot的官方仓库,有详细的指导文档和全套的Spring Boot解决方案,提供Spring Framework的相关配置策略。
3. Mall
https://github.com/wdrt68/mall
Mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现,采用Docker容器化部署。
4. Halo
https://github.com/wdrt68/halo
使用 Spring Boot 框架,完成的现代化的个人独立博客系统。具有完备的 Markdown 编辑器以及文章/页面系统,包含分类,附件管理,评论系统,系统设置等功能。
5. 微人事
https://github.com/wdrt68/vhr
微人事是一个前后端分离的人力资源管理系统,项目采用 SpringBoot + Vue 开发。可以管理角色和用户、角色和资源的关系。