| 这个作业属于哪个课程 | 2020春s班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | github初使用,代码规范制定,疫情统计程序的需求文档 |
| 作业正文 | 正文 |
| 其他参考文献 | 百度,博客园 |
一、Github仓库地址
点击进入Github仓库
二、《构建之法》与PSP
2.1 阅读《构建之法》心得
2.2 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 1*60 | 1*60 |
| Estimate | 估计这个任务需要多少时间 | 1*60 | 1*60 |
| Development | 开发 | 22.5*60 | 32.5*60 |
| Analysis | 需求分析(包括学习新技术) | 3*30 | 3*60 |
| Design Spec | 生成设计文档 | 1*60 | 2*60 |
| Design Review | 设计复审 | 1*60 | 1.5*60 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 1.5*60 | 2.5*60 |
| Design | 具体设计 | 2*60 | 2*60 |
| Coding | 具体编码 | 10*60 | 17*60 |
| Code Review | 代码复审 | 1*60 | 1.5*60 |
| Test | 测试(自我测试,修改代码,提交修改) | 3*60 | 3*60 |
| Reporting | 报告 | 7.5*60 | 10*60 |
| Test Report | 测试报告 | 2*60 | 2*60 |
| Size Measurement | 计算工作量 | 0.5*60 | 1*60 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5*60 | 7*60 |
| Total | 合计 | 32*60 | 44.5*60 |
三、解题思路
Git与Github Desktop
- 下载git与Github Desktop,fork主仓库到自己的仓库
- 学习git命令和Github Desktop基本操作,了解commit,.gitignore,push,pr等
需求整理
- 题目要求:通过cmd运行,读取传入的log目录下的所有日志,列出全国和各省在某日的感染情况
日志分析:日志文件记录国内各省前一天的感染情况,由省份与患者类型数据组成
日志文件中所有情况有8种且格式固定,于是想到正则表达式将这8种情况一一匹配。通过分析提供的.log.txt文件可得出,患者cure、dead时,ip人数应减少;各省之间人口流动时,-type人数应增减等计算规则。当各省份人数变换时,全国-type人数也应同时变化。
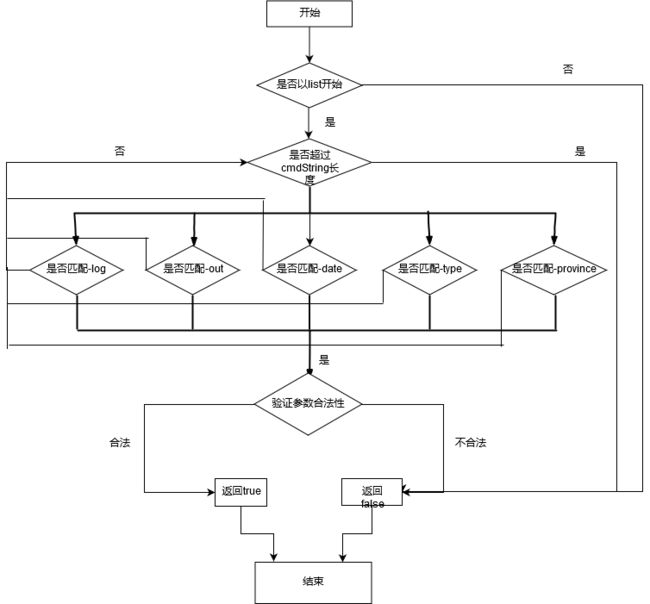
命令行:list命令由-log、-out(必须)、-type、-date、-province(可选)组成
命令行以前只运行过不需要传参的程序,于是查找了关于main函数参数的知识。了解到输入的命令其实就存在main(String[] arg)的arg[]数组里。程序所需要查询的日期、省份、文件路径和类型命令值都和命令类型都从arg[]提取出来。
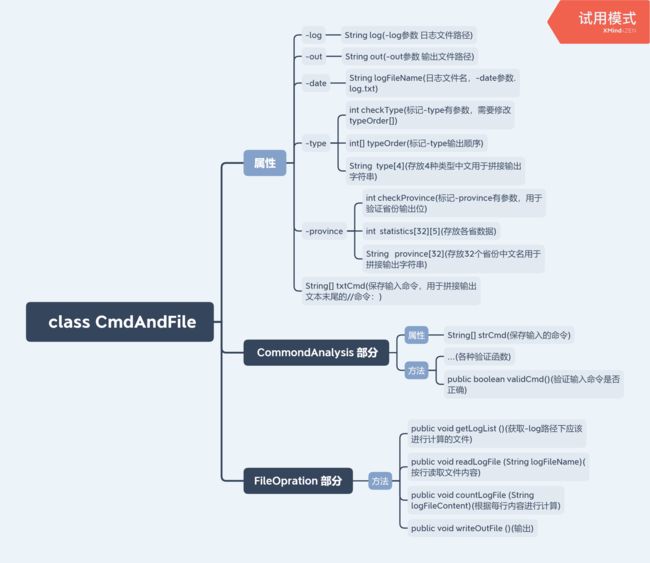
因此想要进行人数统计,首先要进行命令的解析和匹配。所以将整个class CmdAndFile分成两大部分,一部分用于命令的解析,一部分用于文件的读写。
CommondAnalysis 部分
用于命令的拆解、分析和验证有效性
涉及计算较少,主要涉及-date参数日期格式、范围的合法性验证;-province参数是否在32个选项里;-type中几个参数的输出顺序排序。
FileOpration
用于日志文件的读取、计算和输出
读取文件时按行读取,获取每行中涉及到的省份和人数;计算部分只需要根据和日志文件8种格式进行匹配,从而确定计算方式;输出文件时遍历[32][4]的数组,实现省份的按拼音排序,然后根据class CommondAnalysis中已经确定-type的几个参数的顺序输出,拼装输出字符串。(后来数组改成[32][5],多了一位来判断该省份是否需要输出)。
思路流程图

四、设计实现过程
代码结构
CommondAnalysis
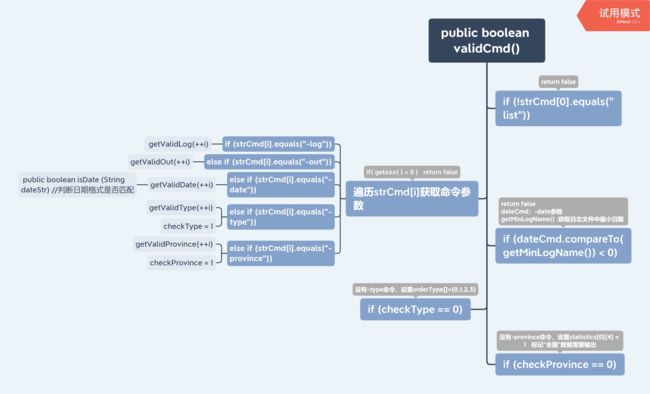
public boolean validCmd() 函数实现
此函数解析、拆取输入命令,读取存储命令数组strCmd[],与-log,-out,-list,-type,-date这几个命令匹配,并且验证参数的合法性。确定从哪里读取日志文件,结果输出到哪里等等必要条件,为统计疫情结果做准备。
FileOpration
public void getLogList () 函数实现
此函数从-log指定文件夹中,与-date参数比较,判断当前在循环中的日志文件是否需要进行读取与计算处理。

public void readLogFile (String logFileName) 函数实现
此函数读取需要计算的文件,将除了//开头以外的其他内容按行读取,读取的字符串传入countLogFile (String logFileContent)进行计算。
public void countLogFile (String logFileContent) 函数实现
此函数按照题目给出的8种情况进行字符串匹配,按照匹配情况计算统计结果。
public void writeOutFile () 函数实现
此函数用于输出。通过循环statistics[32][5]二维数组,拼接输出字符串。
五、代码说明
CommondAnalysis
public int getValidDate(int itemDate)
传入参数itemDate为表示"-date"参数的strCmd[]的下标。
if (isDate(dateStr))判断输入日期是否符合日期格式。查询成功时将class InfectStatistic中logFileName文件名设置为"日期+.log.txt".public int getValidDate(int itemDate) { String dateStr = strCmd[itemDate]; if (isDate(dateStr)) { if (dateStr.compareTo(date) <= 0) //查询日期 <= 当前日期,查询有效 { logFileName = dateStr+".log.txt"; return itemDate; } else return -1; } else return -1; }public boolean validCmd() 验证输入命令是否有效
和日期查询的套路一样,每当匹配到一个命令,调用
getValidXXX(int itemXXX)函数来判断输入的参数是否有效。成功时返回参数下标;失败时则返回-1。没有匹配时:- -date参数默设置认为当前日期
- checkType == 0,设置控制类型输出顺序的数组int typeOrder[] = {0,1,2,3};索引值表示输出顺序,数组值代表输出的类型(0:sp; 1:ip; 2:cure; 3:dead)
- checkProvince == 0,设置存放统计结果的数组statistics[0][4] = 1(statistics[0][]:全国; statistics[][4]:设置省份是否输出)
public boolean validCmd() //validCmd:输入命令有效 { int i; String dateCmd = date; if (!strCmd[0].equals("list")) { System.out.println("命令应以'list'开始!请重新输入!"); return false; } for (i = 1; i < strCmd.length; i++) { if (strCmd[i].equals("-log")) { i = getValidLog(++i); if (i == -1) { System.out.println("日志文件夹路径无效!请重新输入!"); return false; } } else if (strCmd[i].equals("-out")) { i = getValidOut(++i); if (i < 0) { System.out.println("输出文件路径无效!请重新输入!"); return false; } } else if (strCmd[i].equals("-date")) { dateCmd = strCmd[i+1]+".log.txt"; i = getValidDate(++i); if (i < 0) { System.out.println("查询日期无效!请重新输入!"); return false; } } else if (strCmd[i].equals("-type")) { checkType = 1; i = getValidType(++i); if (i < 0) { System.out.println("查询类型无效!请重新输入!"); return false; } } else if (strCmd[i].equals("-province")) { checkProvince = 1; i = getValidProvince(++i); if (i < 0) { System.out.println("查询省份无效!请重新输入!"); return false; } } else { System.out.println("命令错误!请重新输入!"); return false; } } if (dateCmd.compareTo(getMinLogName()) < 0) { System.out.println("该日暂无记录!请重新输入!"); return false; } if (checkType == 0) { for (int j=0; j < 4 ;j++) typeOrder[j] = j; } if (checkProvince == 0) { statistics[0][4] = 1; } return true; } }
FileOpration
public void statistics()根据不同的匹配情况选择计算的方式。
0:sp; 1:ip; 2:cure; 3:dead; 4:checkPrintProvince
public void statistics(int itemProvince, int itemType, int count)传入省份索引值,类型索引值和人数。用于处理只涉及到1个省份,1种类型的情况,即"新增 感染患者"、"新增 疑似患者","排除 疑似患者"。如"xxx省新增感染患者xxx人"时调用statistics(itemProvince, 0, count)。"xxx省排除疑似患者xxx人"时调用statistics(itemProvince, 1, -count)(由于排除疑似患者时数量减少,所以传入的count要改为负数)。
public void statistics(int itemProvince1, int itemProvince2, int itemType, int count)传入两个省份索引值、类型索引值和人数。用于处理涉及到2个省份,1种类型的情况,即"感染患者流入"、"疑似患者流入"。如"xxx省感染患者流入xxx省xxx人"时调用statistics(itemProvince1,itemProvince2,0,count)
public void statistics(int itemProvince1, int itemType1, int itemType2, String count)省份索引值、类型索引值和人数。当count类型为int时,传入参数都为int类型和上一种情况冲突,程序不知调用哪个函数,因此将人数从int转为String。用于处理涉及到1个省份,2种类型的情况,即"死亡"、"治愈"、"疑似患者 确诊感染"。如"xxx省死亡xxx人"时调用statistics(itemProvince1,0,3,count)
public void statistics(int itemProvince, int itemType, int count) { statistics[0][itemType] += count; statistics[itemProvince][itemType] += count; } public void statistics(int itemProvince1, int itemProvince2, int itemType, int count) { statistics[itemProvince1][itemType] -= count; statistics[itemProvince2][itemType] += count; } public void statistics(int itemProvince1, int itemType1, int itemType2, String count) { int intCount = Integer.valueOf(count); statistics[0][itemType1] -= intCount; statistics[0][itemType2] += intCount; statistics[itemProvince1][itemType1] -= intCount; statistics[itemProvince1][itemType2] += intCount; }public void countLogFile (String logFileContent) 读取文件内容进行计算
String logFileContent为传入的每行文档内容。文档内容8种类型分别对应ipIncrease,spIncrease,ipInflow,spInflow,ipDead,ipCure,spChecked,spRemove匹配格式,根据不同的匹配格式选择含参不同的函数public void statistics()进行计算。通过调用getItemProvince(String provinceName)获得省份索引值itemProvince;调用logFileContentArray[].replace("人", ""));将人替换为""获取人数count。
每当匹配到一个省份且checkProvince==0时(表示没有检测到-province这一命令),就将statistics[itemProvince1][4]置为1,用于确认该省份是否需要输出。
public void countLogFile (String logFileContent) { int itemProvince1; int itemProvince2; int count; Matcher ipIncrease = Pattern.compile("\\W+ 新增 感染患者 \\d+人").matcher(logFileContent); Matcher spIncrease = Pattern.compile("\\W+ 新增 疑似患者 \\d+人").matcher(logFileContent); Matcher ipInflow = Pattern.compile("\\W+ 感染患者 流入 \\W+ \\d+人").matcher(logFileContent); Matcher spInflow = Pattern.compile("\\W+ 疑似患者 流入 \\W+ \\d+人").matcher(logFileContent); Matcher ipDead = Pattern.compile("\\W+ 死亡 \\d+人").matcher(logFileContent); Matcher ipCure = Pattern.compile("\\W+ 治愈 \\d+人").matcher(logFileContent); Matcher spChecked = Pattern.compile("\\W+ 疑似患者 确诊感染 \\d+人").matcher(logFileContent); Matcher spRemove = Pattern.compile("\\W+ 排除 疑似患者 \\d+人").matcher(logFileContent); String[] logFileContentArray= logFileContent.split(" "); if (ipIncrease.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); if (checkProvince == 0) { statistics[itemProvince1][4] = 1; } count = Integer.valueOf(logFileContentArray[3].replace("人", "")); statistics(itemProvince1,0,count); } else if (spIncrease.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); if (checkProvince == 0 ) { statistics[itemProvince1][4] = 1; } count = Integer.valueOf(logFileContentArray[3].replace("人", "")); statistics(itemProvince1,1,count); } else if (ipInflow.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); itemProvince2 = getItemProvince(logFileContentArray[3]); if (checkProvince == 0) { statistics[itemProvince1][4] = 1; statistics[itemProvince2][4] = 1; } count = Integer.valueOf(logFileContentArray[4].replace("人", "")); statistics(itemProvince1, itemProvince2, 0, count); } else if (spInflow.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); itemProvince2 = getItemProvince(logFileContentArray[3]); if (checkProvince == 0) { statistics[itemProvince1][4] = 1; statistics[itemProvince2][4] = 1; } count = Integer.valueOf(logFileContentArray[4].replace("人", "")); statistics(itemProvince1, itemProvince2, 1, count); } else if (ipDead.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); if (checkProvince == 0) { statistics[itemProvince1][4] = 1; } String scount = logFileContentArray[2].replace("人", ""); statistics(itemProvince1, 0, 3, scount); } else if (ipCure.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); if (checkProvince == 0) { statistics[itemProvince1][4] = 1; } String scount = logFileContentArray[2].replace("人", ""); statistics(itemProvince1, 0, 2, scount); } else if (spChecked.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); if (checkProvince == 0) { statistics[itemProvince1][4] = 1; } String scount = logFileContentArray[3].replace("人", ""); statistics(itemProvince1, 1, 0, scount); } else if (spRemove.find()) { itemProvince1 = getItemProvince(logFileContentArray[0]); if (checkProvince == 0) { statistics[itemProvince1][4] = 1; } count = Integer.valueOf(logFileContentArray[3].replace("人", "")); count = -count; statistics(itemProvince1,1,count); } }
六、单元测试与测试用例
单元测试
getValidXXX()函数 获取对应下标值的参数值并验证有效性

getMinLogName()函数 获取-log文件夹路径找到最小日期文件,用于判断日期有效性、进行计算的最早文件
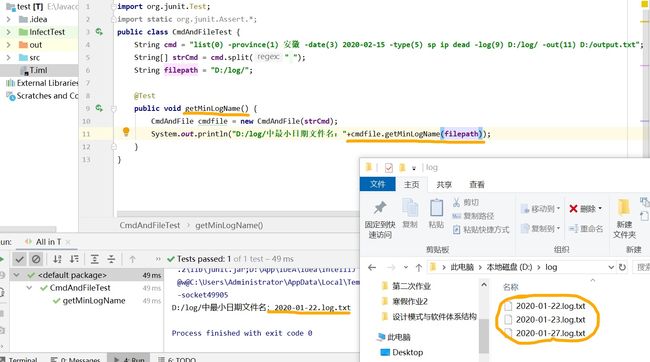
countLogFile(String content)函数 对日志文本进行计算
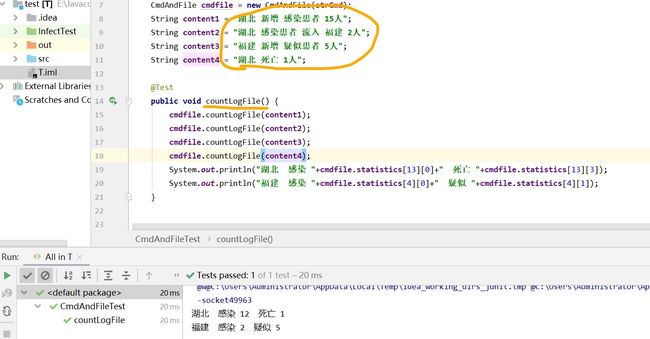
writeOutFile()函数 输出最终结果到指定文件位置
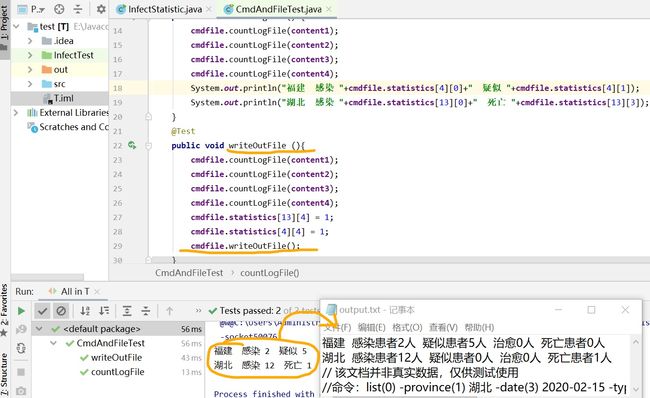
还有其余的单元测试就不展示了
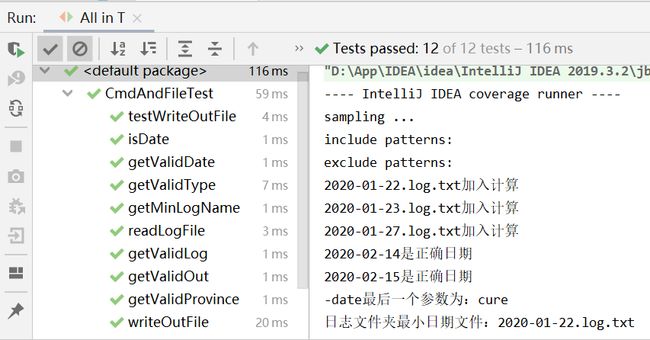
由图可知所有单元测试均正确通过
测试用例
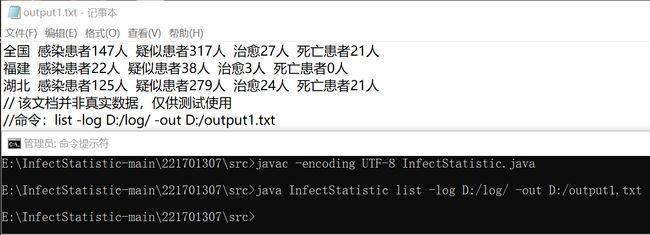
1 只有 -log 与 -out
2.1 只有-date且大于当前日期

2.2 只有-date且小于日志文件最小日期

3 只有-province 且参数多个,并出现日志文件中没有的省份
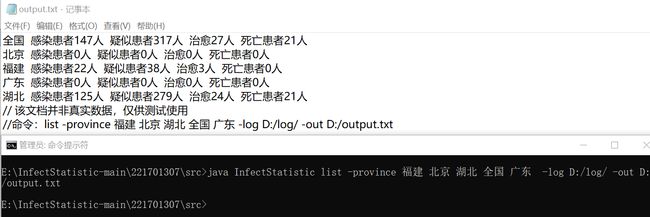
4 只有-type 且参数多个,并且出现顺序打乱
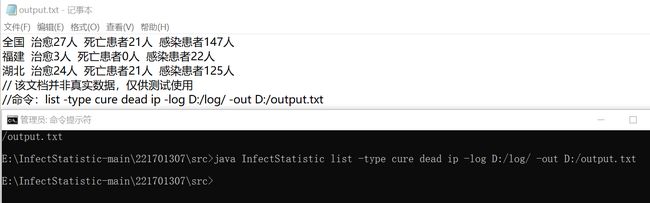
5.1 组合查询 -date -type
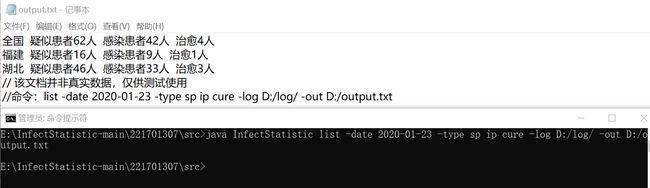
5.2 组合查询 -date -province
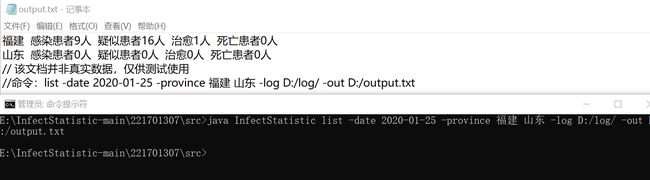
5.3 组合查询 -province -type
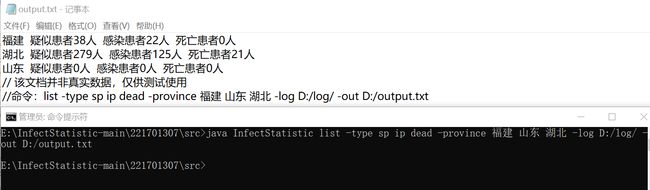
5.4 组合查询 -date -province -type
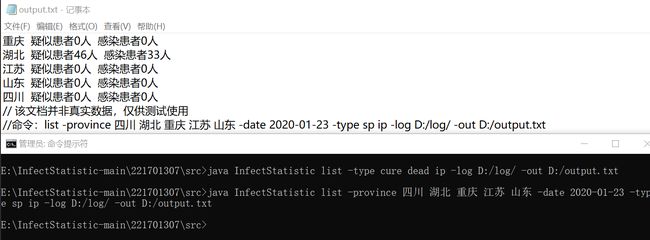
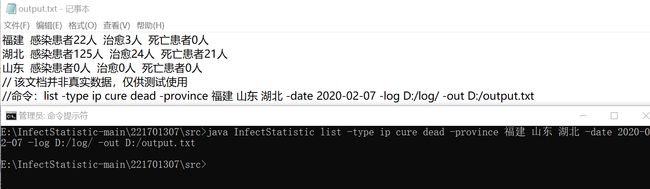
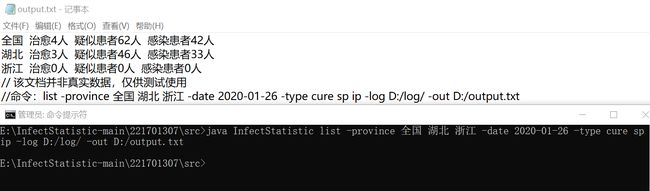
七、盖率优化和性能测试
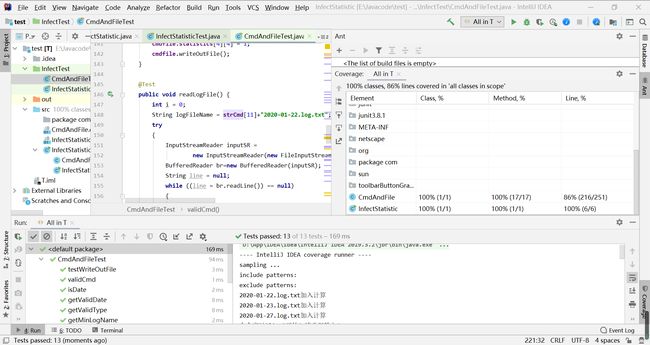
单元测试覆盖率
行数覆盖率只有86%,在查看源码后,发现没有覆盖到的行数均为验证。

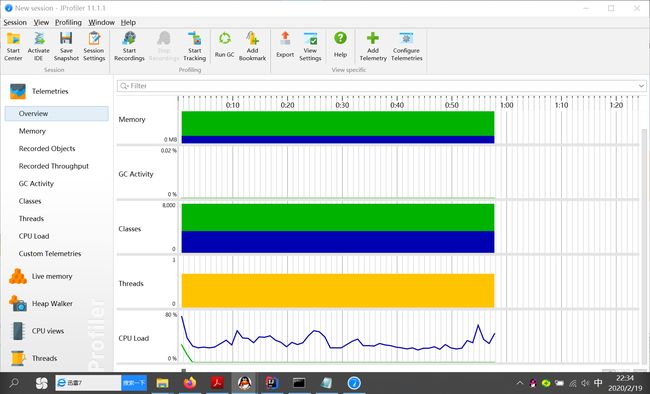
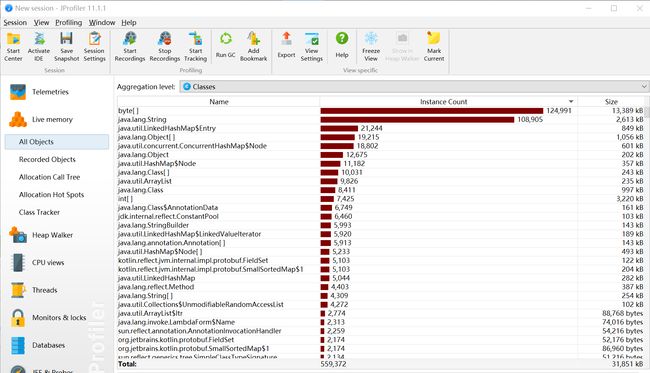
性能测试
八、代码规范
代码规范
九、心路历程与收获
在开始这个作业的时候,其实特别懵。作业要求一下子多了起来,往下一拉一片都是作业要求。gitbash、githubdesktop什么用的,是用于github吧?看《构建之法》学习了解?输入的命令java InfectStatistic list XXXXXXX的命令怎么搞进去的?统计数据计算怎么得到的?都是认识的字合起来一句也没看懂233333。一头雾水的时候,了解完githubdesktop我决定先开始从代码规范要求和《构建之法》做起。看到PSP表格后,开始着手了解作业需求。那个要求我真的看了很多遍很多遍当然每次都没看懂。拿了小本本看懂一个删一个.......查找完main函数参数的时候是晚上11点多,那个时候突然get了整个代码大概要做什么,于是隔天开始动手。
一开始想法很简单,也没有再对类进行划分,所有东西一股脑全被我塞进了一个类里......打到一半我就后悔了,但是整个思路已经有了,于是就没有再改。
懵逼是懵逼,但是收获也还是有的。在完成作业的过程中,问题也不少,暴躁也不少(bushi),遇到了问题就一个个解决,遇到瓶颈就去吃吃东西(?????)到最后收获还是挺多的,触及知识盲区之后总会有收获的东西。
"软件=程序+软件工程"。
这是我读完前三章后感触最深的一句话。
作为一名软件工程专业的学生,我在专业课上学习了很多专业课程,能够编写程序,实现某些具体的功能,但这些都偏向于“软件”,而非“工程”。在阅读这本书之前我也只知道分析这个程序应该实现哪些功能、可以拆分成哪些模块、每个人可以分配哪些任务。而在阅读了《构建之法》后,我才发现真正的团队开发,真正的软件工程是有很多流程规范的。
就比如说最开始的选题和需求分析阶段,我们以往的理解就是想想要实现什么功能,决定好了就可以开始写代码了。《构建之法》却告诉我们,需求分析没有这么简单,开发者要能发现目标用户的需求,要区分需求的优先级,要编写出明确的规格说明来指导开发,编写代码前还要对软件结构进行分析设计。在软件开发的过程中,分析、设计、管理这些理论工作的重要性,不比写代码的重要性低。
完整、良好的需求分析能够为后续开发、测试、维护、扩充等等打下坚实的基础,能够为实现我们的目标即软件工程的目标——创造“足够好”的软件。
而如何实现“足够好”这一需求呢?我认为实现代码完成任务只是开始。在完成代码后,我们需要做的便是测试。单元测试能帮助程序员记录这个模块的历史和设计变更的理由。“100%的代码覆盖率并不等同于100%的正确性”。单元测试应该集成到自动测试的框架中。另一个重要的措施是要把单元测试自动化,这样每个人都能随时、随地运行单元测试。
总之,朝着自己想要的方向努力吧~
十、相关仓库
Java-WebSocket
链接:Java-WebSocket
简介:Java编写的基本WebSocket服务器和客户机实现。底层类是java.nio实现的,允许非阻塞事件驱动模型(类似于web浏览器的WebSocket API)。
web socket server抽象类实现了web socket协议的服务器端。WebSocket服务器本身除了通过HTTP建立套接字连接之外什么也不做。在那之后,由子类来添加目的。
spring boot demo
链接:spring boot demo
简介:spring boot demo 是一个用来深度学习并实战 spring boot 的项目。该项目已成功集成 actuator(监控)、admin(可视化监控)、logback(日志)、aopLog(通过AOP记录web请求日志)、统一异常处理(json级别和页面级别)、freemarker(模板引擎)、thymeleaf(模板引擎)等。
JavaGuide
链接:JavaGuide
简介:一些Java基础知识合集,如线程、容器、框架等。
spring-boot
链接:spring-boot
简介:可以使用SpringBoot创建独立的Java应用程序,这些应用程序可以使用Java-jar或更传统的WAR部署启动,还提供了一个运行spring脚本的命令行工具。
java-design-patterns
链接:java-design-patterns
简介:展示了Java设计模式,这些模式可以通过它们的高级描述或查看它们的源代码来浏览。