- 1.本系列基于新生大学课程《Python编程&数据科学入门》和公开的参考资料;
- 2.文章例子基于python3.6,使用Windows系统(除了安装,其余基本没有影响);
- 3.我是纯小白,所以,错误在所难免,体系会逐渐成熟,我会经常进行更新;如果您发现了错误,也烦请帮我指出来,在此先谢过了。
这次课主要有下面这些内容:
- 序列
- 字典
- 内置函数和自定义函数
- 条件语句
- 循环
一、序列
Python中的序列主要有三种:
- 字符串
- 元组
- 列表
(一)字符串
字符型就是用引号(单引号、双引号、三引号)引起来的内容。
这些括起来的内容,既可以是一个字符,也可以是很多的字符,因为python里没有字符的结构,这两者统称为字符串。
有一些要点需要注意:
1.三个引号的区别
- 单引号和双引号没有区别。但是,如果想要把引号本身作为内容,就需要两种引号配合使用。
比如:
"I'm bussy now."
单引号就是内容,而不是一个引用。
- 三引号('''或者""")可用于带有换行符(多行)的内容。
a = 'one goo'
b = "another book"
c = '''
This is a very
intersting book!
'''
2.字符串其实是一个字符的序列
它可以和列表、元组等进行转换。
s = 'summer'
list(s)
输出的结果是:
['s', 'u', 'm', 'm', 'e', 'r']
- 字符串可以+相加或者用*复制
a = 'xyz'
b = 'qwe'
a+b
输出是:
'xyzqwe'
a = 'xyz'
b = 'xyz' * 3
b
输出的结果是:
'xyzxyzxyz'
3. 字符串格式化
用%可以输出格式化的字符串。以%开头且后面跟着一个或多个格式字符的字符串是需要输入值的目标,比如:
'Hi %s , your score is %d. %('Mary',59)
%代表的是输入的内容必须是字符串,%d代表输入的内容必须是整数。
还有很多的格式字符,具体见下表:
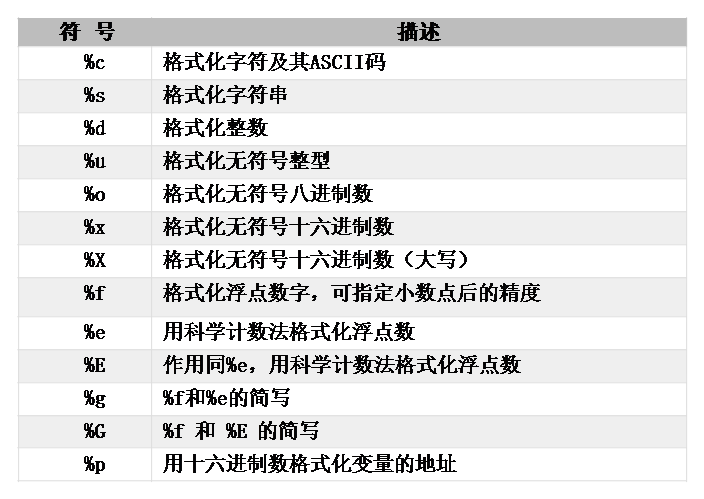
如果要表示“%”这个字符的话,就需要转义,用%%来表示一个“%”符号。
比如:
print('Growth rate is :%d %%' %7)
'Growth rate is : 7%
4. 字符串的索引和切片
索引就是找到字符串序列中的一个字符,切片就是将多个字符从字符串序列中取出来。
换句话说,索引是选取数据的一个元素,而切片是选取数据的子集。这在以后的数据结构中都是一样的。
- 索引的语法是:字符串[]
举个例子:
a = 'Welcome your coming!'
a[3]
a[-2]
上面的正数成为始索引,从字符串的左边第一位开始往右取,从0开始数;
而负数为终索引,从右边第一位往左取,数值为负,从-1开始数。
也就是说,各个字符在字符串中的索引位置如下:
a[0] = 'W'
a[1] = 'e'
a[2] = 'l'
……
a[-1] = '!'
a[-2] = 'g'
a[-3] = 'n'
……
- 切片的语法是:字符串[始索引:终索引]
有了上面的基础,切片就很好理解了,就是这两者之间的内容,但终索引是不包含其中的。比如:
a[3:-2]
a[3]是c,包含;而a[-2]是g,不包含。所以,输出的是:
'come your comin'
所以,始索引包含这个索引值,而终索引的索引值是不被包含的。这个要牢记。
除此之外,还有三点要注意:
1)切片的时候,也可以没有始索引或者终索引,比如:
a[0:]取的是从第一位开始的所有值:'Welcome your coming!'
a[:-5]取的是倒数第5位之前的值:'Welcome your co'
2)可以增加一个参数——步长索引。
比如:
a = 'Welcome your coming!'
a[3: -2: 2]
就表示切片的步长是2,隔一个取一个索引值。输出的结果是:
'cm orcmn'
而负数表示从后往前切片取值:
a = 'Welcome your coming!'
a[-3: 3: -2]
'nmcro m'
3)切片得到的是一个低等级的字符串,这在以后要学到的列表、元组、数组等的切片都是一样的,要牢记。
5. 转义字符与原始字符串
如果含有特殊字符,比如换行、既有单引号又有多引号等就需要转义。
比如,怎样表达I'm "Ok"!这个句子呢?
用单引号和双引号都不行,系统都会报错。用“\”来表示之后的字符是需要转义的。
'I\'m \"Ok\"!'
表达的内容就是
I'm "Ok"!
表达换行,用\n,类似于一个回车键的功能;\t表达制表符;而\就表示“\”。
如果不想转义,也可以强制使用r(R)键表达不转义直接输出的意思。
print('\\\n')
输出的是:
\
而如果加了r或者R之后,就不会转义:
print(r'\\\n')
结果是:
\\\n
(二)元组
用()界别,是一种一维的、定长的、不可变的一组python对象序列。比如:
seq1 = (11, 12, 13)
seq1
结果是:
(11, 12, 13)
- 通过调用tuple函数,可以把任何序列或迭代器转换成为元组。
tuple([3,4,5])
(3,4,5)
seq2 = tuple('good')
seq2
('g', 'o', 'o', 'd')
- 元组的索引和切片与字符串是一样的。
上面的seq1[0],就是11;seq2[-1]就是'd';seq1[1:2]就是(12,)。
注意,索引取的是单个的值,而切片切出来的仍然是一个元组。
如果切片的源是一个元组的组合,那么切出来的东西仍然是一个组合,即使它只有一个元组。
比如:
a = (('a','b','c'),('d','e','f'))
a[0:1][0]
打印出来的内容不是‘a',而是['a','b','c']。因为第一次切片的内容是一个元组组合,所以二次切片需要从组合中切出一个元组。如果要得到'a',需要再次切片:
a[0:1][0][0]
- 不可以修改元组里的对象,但是如果元组的元素有列表(参见下文),却可以向其中添加对象。比如:
seq3 = (1, '1', [4,5,6], True)
seq3[0] = 2
这样重新赋值会报错:
TypeError Traceback (most recent call last)
in ()----> 1 seq1[-1] = 12
TypeError: 'tuple' object does not support item assignment
seq3 = (1, '1', [4,5,6], True)
seq3[2].append(8)
seq3
(1, '2', [1, 2, 3, 8],True)
这样就没有问题。
- 元组可以通过+来连接,通过*来复制
(1, 2, 3) + ('1' + '2')
(1, 2, 3, '1', '2')
要注意的是:当列表只有一个元素时,需要在后面加一个逗号“,”,不然系统会报错
(4, None, 'goo')+(6,0) + ('33')
TypeError Traceback (most recent call last)
TypeError: can only concatenate tuple (not "str") to tuple
改成这样:
(4, None, 'goo')+(6,0) + ('33,')
(4, None, 'goo', 6, 0, '33')
就没有问题了
In [47]:
(三)列表
列表是用方括号[]括起来的一个序列,列表能够保留任意数目的对象。
1.创建一个列表
仍然是赋值就可以了,和变量是一样的。也可以通过格式转换,把字符串或元组变成一个列表。
list(‘foob’)
list((11, 12, 13))
输出的结果分别是:
[‘f’,'o','o','b']
[11,12,13]
2. 包含的元素类型
列表内的元素可以是任何类型,而且并不需要一致,甚至可以是列表本身。比如:
[1, 2, 'ab', [x,y,z],]
3. 索引和切片
这和字符串、元组是一样的,所有的序列类型都是一样的。就不举例了。
- 嵌套列表的取值(切片)
可以用两个方括号。比如:
list3 = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
type(list3)
这仍然是一个列表,如何取到9这个值呢?方法是用两个[]。
答案是:
list3[2][2]
4.修改列表中的元素
1)修改元素的值
这个很简单,直接赋值就可以了。以上面的list2为例子,如果想将5改为15。则这样写:
list2[-1] = 15
还可以同时修改多个元素,用上面提到的切片的方法:
list2[0:3] = [11, 12, 13]
list2
得到的结果就是:
[11, 12, 13, 4, 5]
还可以同时修改多个元素:
list3 = [11 ,12, 13, 14]
list3[0:2]=[21,22]
list3
[21, 22, 13, 14]
2)新增元素的值
可以通过append和insert方法在末尾和指定位置增加元素:
list3 = [11 ,12, 13, 14]
list3.append(15)
list3.insert(2,19)
list3
[11, 12, 19, 13, 14, 15]
这两者的区别在于:
- append()方法 只有一个参数,只能在列表的末尾添加一个元素
- insert()方法 有两个参数,可以在列表的任意位置添加一个元素。
3)删除元素的值
可以通过del ,pop和remove3种方法删除元素:
list4 = ['a', 'b', 'c']
list4.pop(2)
list4.remove('a')
list4
结果是:
['b']
- del语句可以删除任意位置的元素
list4 = ['a', 'b', 'c']
del list4[-1]
list4
['a','b']
pop是一种方法,有两种用法
第一,当不加参数时pop(),默认删除最后一个元素。pop的意思是弹出,就是最后一个进入的元素被弹出的意思。
第二,当添加参数的时候,可以删除任意位置的元素
使用pop()方法可以直接调用这个被删除的值。比如,
name1 = names.pop(2)
直接就调用了这个被删除的元素的值remove
可以精确匹配需要删除的值。
4.连接和复制一个列表
与字符串和元组一样,也是用+ 和*。比如:
list2 + [17,18]
list2 * 2
- 通过元素找到索引
通过index来实现。比如:
list2 = [11, 12 ,13]
list2.index(12)
输出的结果是:1
也就是第二个数值。
二、字典
字典是Python语言中唯一的映射类型。映射类型对象里哈希值(键,key)和指向的对象(值,value)是一对多的关系。
字典可以被理解为可变的哈希表(哈希表也叫散列表(Hash table),是根据键(Key)而直接访问在内存存储位置的数据结构。)
你可以简单的把字典理解为键(value)和值(value)之间的一系列对应关系。
比如:
dict1 = {'nam':'tom', 'gender':'m', 'age':21}
这就是一个简单的字典。
'nam'、'gender'、'age'是3个键的名字,'tom',、'm'、21是3个键的值。
(一)字典的赋值
第一种是直接写出字典全部的值,就像我们上面的例子。
第二种是依次写出字典的值。比如:
dict1['nam'] = 'tom'
dict1['gender'] = 'm'
- 第三种是通过dict函数。比如:
dict2 = dict((['x' , 1], ['y' , 2]))
dict2
{'x': 1, 'y': 2}
(二)字典的索引和取值
序列(字符串、列表、元组)都是由整数按照顺序作为索引,而字典则由key作为索引。
字典中的元素没有固定顺序,所以字典的索引是无序的。常用字符串类型做key。
通过列表取值的方法如下:
coutries = ['spain', france', 'china']
capitals = ['madrid', 'paris', 'beijing']
# 打印法国的首都
capitals[coutries.index('france')]
- 如果用字典可以直接通过索引方法来实现,就很简单了。
dict3 = {'spain':'madrid', 'france':'paris', 'china':'beijing'}
#通过字典keys获取values
dict3['france']
- 获取索引的方法
dict3.keys()
就获得了字典dict3的所以的索引值,这是一个元组:
dict_keys(['spain', 'france', 'china'])
同样的,获取字典的值也是类似的value
同时获得字典的各个元素的值items
dict3.values()
要想获得的键和值,可以通过items方法dict3.items()。也是一个列表,每一个元素都是元组:
dict_items([('spain', 'madrid'), ('france', 'paris'), ('china', 'beijing')])
- 还可以使用get的方法来获取字典的值
比如:
dict3.get('france')
'paris'
get还可以加一个参数,也就是如果没有找到索引的返回值,没有的话,默认的返回值是空值,也就是什么也不输出。
相对于索引函数,这样会相对比较友好。
比如:
dict3['Germany']
因为没有德国的数据,所以系统会报错:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
in ()
----> 1 dict3['Germany']
KeyError: 'Germany'
而如果使用get方法,则比较友好:
dict3.get('Germany')
dict3.get('Germany','unknown')
第一个不会有任何输出;而第二个则会输出'unkown'。
字典和list相比,它有两个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费较多。
所以,字典dict是一个以空间换时间的方法。
(三)字典的增删改
1.增加新的值,就是直接赋值。
dict3['britain'] = 'london'
2.删除的函数和方法
- 使用del函数
del(dict3['britain'])
或者 del dict3['britain'] - 使用pop方法
dict3.pop('britain')
这两者的区别是,后者会有一个返回值,也就是刚刚删除的那个值——‘london’。
3.修改的方法
也就是给原来的值附一个新的值。比如:
dict3['britain'] = 'London'
就把伦敦由小写改成了大写的。
三、内置函数和自定义函数
函数是一段可以重复调用的代码,往往是为了解决某个特定的任务。
我们可以把函数看成一个黑盒子,不用管细节,只要知道函数名就可以了。只要有输入,函数就会给出一个输出。
python中有两类函数:
- 内置函数
- 自定义函数
(一)内置函数
内置函数是python程序自带的函数,python内置函数非常实用而丰富,这也是Python的优势所在。
下面讲一些内置函数是如何运用的(如果觉得多,你可以跳过这一部分):
1.round
- 功能:四舍五入
例如:
round(2.7)
这个函数就输出了一个四舍五入的近似值:3。
- round还可以增加一个数字参数,取小数的近似值。比如,
round(3.22233, 2)
3.22
2.type
type可以查看变量的类型。
比如
type(3)
type('height')
type([1,3,5])
输出的分别是:
int
str
list
3.len
len函数获取列表元素的个数
len(‘length’)
答案是6.
再比如:
lis = [1,3,5,7]
len(lis)
答案自然是4
4.range
range函数是生成整数序列的函数。
range(a,b),a和b为整数,并且满足b>a,生成的列表就是[a,a+1,……,b-1]
取值方法和索引很类似。
range(2,9)
list(range(2,9)
输出的值就是:
[2, 3, 4, 5, 6, 7, 8]
5.max函数
- 求最大值
max(2,3,5)
max(rang(2,9))
max(lis)
答案分别是
5
8
7
6.input
这个函数是让用户自己输入,但它返回的是str(字符串),所以,如果要求输入数值型的值,必须进行转换。
比如:
a = input("Enter a number:")
if a > 0:
print('a是一个正数')
elif a<0:
print('a是一个负数')
else:
print('a为0')
程序就会报错:
TypeError Traceback (most recent call last)
in ()
1 a = input("Enter a number:")
----> 2 if a > 0:
3 print('a是一个正数')
4 elif a<0:
5 print('a是一个负数')
TypeError: '>' not supported between instances of 'str' and 'int'
将第一行改为
a = int(input("Enter a number:"))
就可以了。
内置函数还有很多,你可以在系统文档中查阅,记住一些常用的即可,需要的时候可以去查询。
一些小技巧
下面这个地址将所有的内建函数都列了出来,缺点是没有中文,凑合着用吧。https://docs.python.org/3/library/functions.html
有一些中文的,但大多是基于2.7版本:比如下面这两个:
- http://gohom.win/2015/10/19/pyBuildInMethod/
- http://python.usyiyi.cn/translate/python_278/library/functions.html
如果不知道一个函数怎么用,可以输入help()。括号内是函数的名字。
(二)自定义函数
1.定义
自定义函数顾名思义,就是自己定义的可以调用的函数。
自定义函数的好处主要有三点:
第一,函数可以实现独立的功能,在运行的时候调用,如果出现问题就可以分别调试,提高程序编写的效率。
第二,用自定义函数可以给主程序瘦身,增加可读性。
第三,自定义函数可以反复使用,需要这个功能直接调用就行了,不需要做重复性的劳动,极大的提高效率。
所以,多写自定义函数,具有复利价值,是一个非常优秀的习惯。
2.使用方法
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
def fun_name(x1,x2):
代码块
return(没有返回值也可以省略)
比如,我们自定义一个求圆的面积的my_circle函数为例:
def my_circle(x):
if type(x) == float or type(x)==int:
return 3.14 * x * x
else:
print('Please check your entery')
比如求半径为5的圆的面积:
my_circle(5)
输出答案:78.5
再举一个求两个值的最大公约数的例子:
def find_gcd(ni,n2):
gcd =1
k = 2
while k <=n1 and k<= n2:
if n1 % k == 0 and n2 % k == 0:
gcd = k
k += 1
return gcd
3.调用方法
如果把上面的自定义函数保存为caculate.py文件里了,就可以在该文件当前目录下启动python解释器,用from caculate import find_gcd来导入函数,注意caculate是文件名,而且不需要加.py扩展名。
启动python解释器,其实就是启动一个环境,操作层面来讲就是在指定的目录下启动python命令。jupyter notebook下的文件只要和py文件在一个目录下,也可采用同样方式导入。
(三)其他
1.函数与方法
函数和方法都能实现一定的功能,方法可以理解为函数的一种功能,用英文句号来标识。
比如,前面提到的删除:
- del(dict3['britain'])
- dict3.pop('britain')
del是一个函数,而pop就是一种方法。
2.函数的返回值
函数可以有一个或若干个返回值。而Python的函数返回多值其实就是返回一个tuple,但写起来更方便。
四、条件语句
我们都是通过各种条件进行逻辑判断和决策,计算机也是如此。
比如:
如果下雨,我就宅在家里不出去,如果不下雨,我就出门。而且,天气如果热的话,我就看电影,如果不热的话,去趟植物园。
用python程序怎么表达呢:
if 下雨:
宅在家里
elif 热:
去看电影
else:
去植物园
条件表达式有两种,一种是布尔表达式,一种是逻辑表达式。
前面已经讲过,布尔值是进行条件表达式的结果,这个条件表达式也可以称之为布尔表达式,也就是求真假。
常见的布尔表达式有:
- x==y (x是否等于y)
- x != y (x是否不等于y)
- x < y (x是否小于y)
- x > y (x是否大于y)
- x <= y (x是否小于等于y)
- x >= y (x是否大于等于y)
- x is y (x和y是否相同,而且类型也要一样)
- x is not y (x和y是否相同)
例如:
3 ==7
answer is:
False
7 <= 11
答案当然是对的
True
逻辑表达式
逻辑运算符:and(与)、or(或)、not(非)
1.and(与)
- True and True 返回 True
- True and False返回 False
- False and False 返回 False
比如:
x =10
x > 5 and x <0
输出False
2.or(或)
- True or True返回True
- True or False返回True
- False or False返回False
比如:
x =10
x>5 or x <0
True
3.not(非)
- not True 返回False
- not False返回True
比如:
x =10
not(x<100)
False
下面我们正式来看看都有哪些条件语句:
1.简单条件语句
如果要实现这样一个判断:
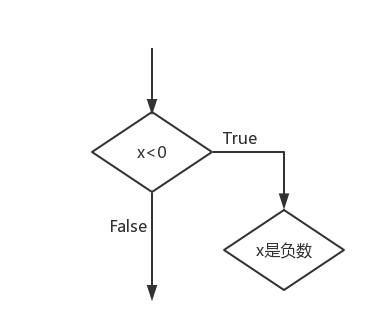
x = -1
if x <0:
print('x是负数')
注意:
- 1.条件判断后用冒号表示;
- 2.执行的语句用缩进表示,一般是4个空格,也可以是自己定义的空格数字,比如2个、3个、8个等等,但在同一段代码中一定要统一。
2.增加分支语句
比如下面的流程:
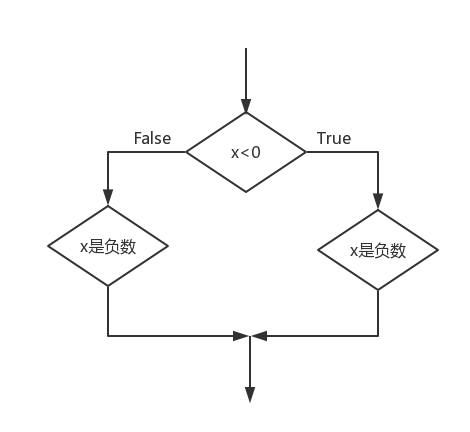
代码为:
x = 6
if x < 0:
print('x是负数')
else:
print('x是正数')
- 一个简化的分支条件表达式
结果1 if 条件 else 结果2
如果符合条件输出结果1,如果不符合输出结果2。比如:
x = 25
y = 36
a = x if x< y else y
a
因为25小于36,条件为真,所以输出:
25
3.链式语句
也就是一个条件有多个可能(超过2个),就可以用elif(就是else if的缩写)来表示。比如:
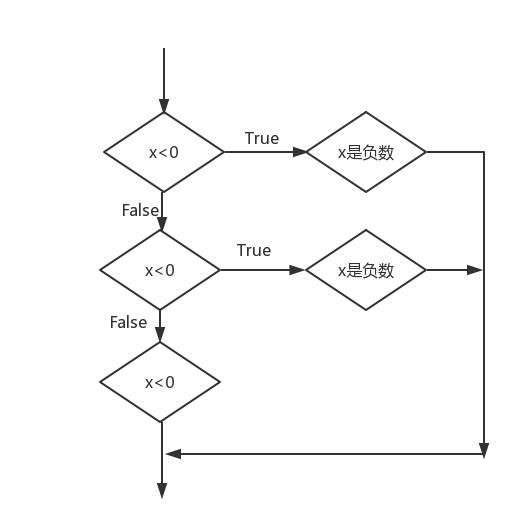
x = 6
if x < 0:
print('x是负数')
elif:
print('x是正数')
else:
print(x是0)
这样x的值就没有例外,也就不会有bug了。
例子:
条件表达式:布尔表达式、
条件执行if,分支执行if else,链式执行if elif else
不建议嵌套的层次太多。
五、for循环
循环能遍历序列中的每一个元素。主要的循环有两种方式:
- for循环
- while循环
(一)for循环
1.基本语法
for变量 in 序列(或迭代器):
执行的代码
例子:
for i in [1, 2, 3, 4, 5]:
print(i)
我们来走一遍程序:
给i赋值,i 等于列表第一个值——1,打印1
给i赋值,i 等于列表第二个值——2,打印2
给i赋值,i 等于列表第一个值——3,打印3
给i赋值,i 等于列表第一个值——4,打印4
给i赋值,i 等于列表第一个值——5,打印5
所以输出的结果是:
1
2
3
4
5
PS:使用print函数会默认打印出一个回车。
2.迭代序列
用于迭代的序列可以是多种类型:
1)可以用序列的3种类型来迭代
- 字符串
- 列表
- 元组
比如:
for i1 in 'goodboy':
print(i1)
for i2 in ['g', 'o', 'o', 'd']:
print(i2)
for i3 in ('b', 'o', 'y'):
print(i3)
2)可以用索引来迭代
比如:
num = [1,3,5]
for i in range(len(num)):
print(num[i])
3.可以用emunerate函数来迭代
name = ['a', 'b', 'c']
for i, j in enumerate(name):
print('序号:%d,姓名:%s' %(i+1, j))
enumerate有两个参数,将索引和元素的值分别迭代输出。
所以,输出的结果是:
序号:1,姓名:a
序号:2,姓名:b
序号:3,姓名:c
3.continue、break、pass语句
- continue
当遇到continue语句时,程序跳出当前循环,直接执行下一个循环。
- break
遇到该语句,立即退出循环。
- pass
这个语句的意思是不做任何事。
为什么要有这么一个语句呢?这个语句主要用在设计的时候, 比如先想了一个结构,还没有想好代码怎么写:
while true:
if x <0:
pass
else:
pass
所以,pass也称之为占位符。
(二)while循环
只要条件满足,就会一直循环下去。
- while循环和for循环最大的不同在于:while循环是条件性的,而for循环是迭代性的,会自动加1
比如:打印每一个名字:
Name = ['joky', 'jacky', 'jonas', 'jack']
i = 0
while i < 4:
print(Name[i])
i += 1
joky
jacky
jonas
jack
六、案例
1.统计词频
给定一段文本,找出其中出现最多的次数。
这就是我们经常见到的“单词云”,比如下面这个:

我们可以用for循环来实现。
在写代码之前,我们可以想一下,怎样来设计呢?
应该是这样的步骤:
- 从第一个字开始,把字和数量记下来
- 下一个字如果和前面的一样,就在那个字的数量上+1
- 重复若干次
- 统计输出不同的字和数量
# 第一步,先把文字赋值给text
text = '''Hackers blow off questions that are inappropriately targeted
inorder to try to protect their communications
channels from beingdrowned in irrelevance.
You don't want this to happen to you.'''
words = text.split() # split函数是把所有的单词取出来
print(words)
# 第二步,把所有不重复的单词取出来,赋值给unique_words
unique_words = list() # 将空列表赋值给unique_words,存储不重复的文字
for word in words:
if (word not in unique_words):
unique_words.append(word)
pritn(unique_words)
# 第三步,把单词的数量按照unique_words的顺序写入counts
counts = [0] * len(unique_word)
counts
for word in words:
index = unique_words.index(word)
counts[index] += 1
print(counts)
# 第四步,找出词频最高对应的单词
bigcount = None
bigword = None
for i in range(len(counts)):
if bigcount is None or counts[i] > bigcount:
bigword = unique_words[i]
bigcount = counts[i]
print(bigword,bigcount)
最后输出的结果是:
to 4
2.打印9*9乘法表
先给出函数,而后解释。
for i in range(1,10):
for j in range(1,10):
print(format(i*j,'4d'),end='')
print('\n')

知识本身不是力量,“知识+持续的行动”才是!
我是陶肚,每天陪你读点书。如果喜欢,请帮忙点赞或分享出去。

