效果图:

代码:
# -*- coding: utf-8 -*-
# Filename:print_text.py
# 输出网页上的文字
import re
import requests
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1)'
headers = {'User-Agent':user_agent}
url ='https://www.jianshu.com/p/713415f82576'
data = requests.get(url, headers=headers).content
texts = re.findall('(.*?)
' ,data ,re.S)
# 列表的最后一个元素不是我们要提取的目标内容
# 只输出文本做的最后 9 行,即列表的 -10 至 -2 元素
for text in texts[-10:-1]:
print text
知识点:
列表的索引和切片
上回说了列表的索引表示列表中元素的位置,如
list_1 = ['h','e','l','l','o','w','o','r','l','d']
列表第一个元素 h 的索引是0,第二个元素 e 的索引是1,以此类推
但索引也可以用负数表示,列表最后一个元素 d 的索引是 -1,倒数第二个元素 l 的索引是 -2,以此类推。
>>> list_1[0]
'h'
>>> list_1[-1]
'd'
列表的切片,是指在原列表中截取一些元素,组成子列表
>>> list_1[0:3]
['h', 'e', 'l']
list_1[0:3] 表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
list_1[-3:-1] 表示,从索引 -3 开始取,直到索引 -1 为止,但不包括索引 -1。
>>> list_1[-3:-1]
['r', 'l']
字符串也可以切片
>>> str_1 = 'hello,world!'
>>> str_1[0:3]
'hel'
正则表达式
正则表达式(regular expression)是一个特殊的字符序列,它的主要功能是从字符串(string)中通过特定的模式(pattern),搜索想要找到的内容。
Python 中要使用正则表达式需要先导入模块 import re
本例用到的是 findall 方法。
re.findall 方法:
根据正则表达式搜索字符串,将所有符合的子字符串放在一个表(list)中返回
语法:
re.findall(pattern, string, flags=0)
# pattern : 正则中的模式字符串
# string : 要被查找的原始字符串
# flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。通常为 re.S
使用 re.findall 的重点是根据网页源码确定 pattern。
本例中网页 https://www.jianshu.com/p/713415f82576 的源码
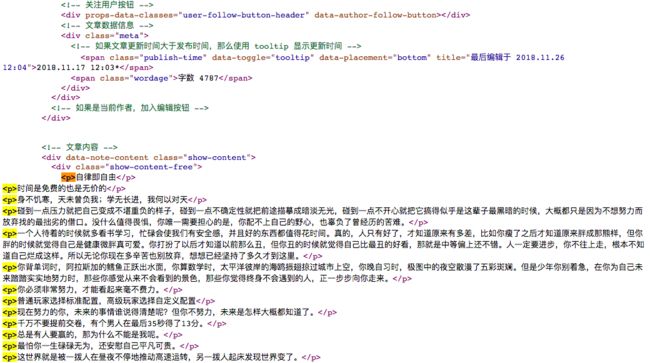
要提取的文本都包含在 和
目标内容
使用 (.+?) 来提取内容,示例:
# 示例1
import re
str = "a123b"
print re.findall("a(.+?)b",str)
#输出['123']
# 示例2
str = '自律即自由
'
print re.findall('(.+?)
', str)
# 输出 ['自律即自由']
texts = re.findall('(.*?)
' ,data ,re.S)
这行代码的意思是:
在变量 data 所代表的字符串中,提取出
和
之间的文本,并把文本放入一个列表中,赋值给变量 texts如果对正则表达式的讲解有点蒙也没关系,后面我们还会多次讲解。
正则表达式并不是Python独有。
学习正则表达式的关键是一次只学一点,只学满足需要的那部分内容。预先将他们全部记住是没必要的。
教程目录:
0.《简介及准备》
1.《爬单个图片》
2.《下载一组网页上的图片》
3.《输出一个网页上的文字》
4.《获取电影天堂最新电影名称》
5.《糗事百科爬虫》
20181128