可视分箱化设计的目的在于,帮助您在将现有变量的连续值进行分组的基础上,将新变量创建到数目有限的不同类别中。可以将可视分箱化用于:
从连续刻度变量创建分类变量。例如,您可以使用刻度收入变量创建包含收入范围的新的分类变量。
将大量有序类别拼并到一小组类别中。例如,您可以将具有 9 个级别的等级标度拼并为分别代表低、中、高的三个类别。
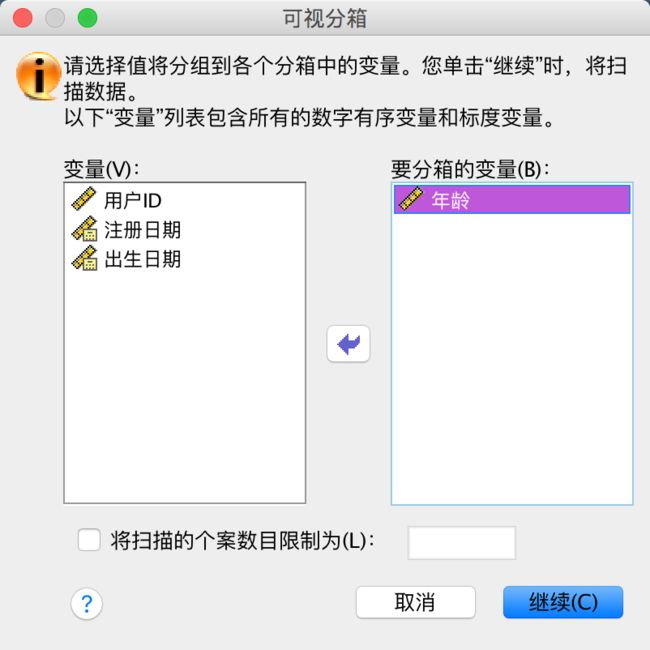
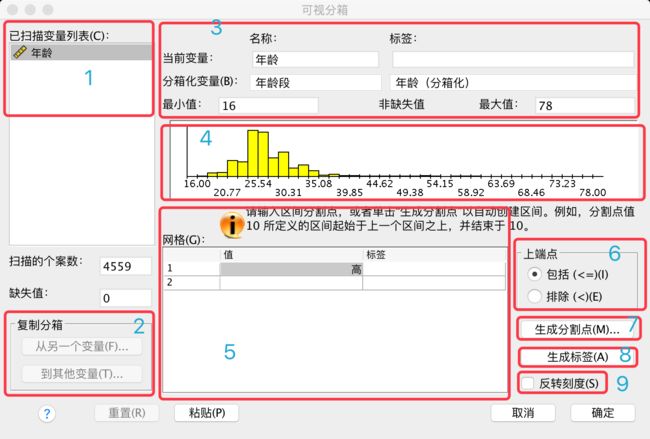
1)已扫描的变量列表
列出了在前一个对话框中所选择的所有变量
2)左下侧“复制块”框组
当选择了多个变量,并且其中部分变量已设定完可视分箱选项时,可以将设定好的属性“复制”到其他变量,也可以“从另一个变量”(已设定好的)读取相应的设定
3)上部变量属性
显示老变量的名称和标签,新变量的名车更是需要自定义的,否则将不会生成任何新变量
4)中部直方图
对原变量的取值情况做出显示,如果已设定了分割点,也会一并显示
5)下部数值标签网格
此处可以自定义分割点的数值和相应的标签
6)右下侧“上端点”框组
用于设定端点是都被包括在上册区间内
7)“生成分割点”按钮

数据的变量管理--可视分箱等宽度间隔。根据以下三条标准中的任意两条,生成等宽(例如 1 - 10、11 - 20 和 21 - 30)的分箱化类别:
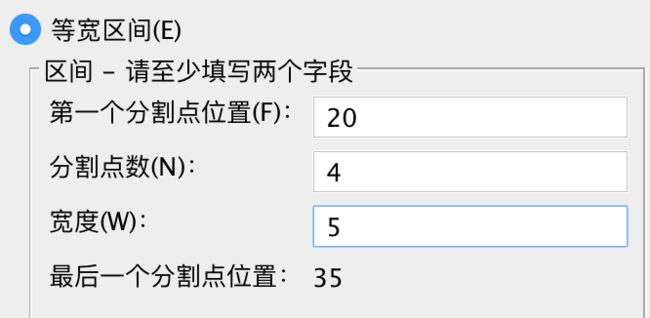
第一个分割点的位置。 定义最下面的分箱化类别的上端点的值(例如,值 10 表示包含所有不超过 10 的值的范围)。
分割点数量。 分箱化类别数是分割点数量加一。例如,9 个分割点会生成 10 个分箱化类别。
宽度。 每个区间的宽度。例如,值 10 会将年龄 分箱化为长度为 10 年的区间。
基于已扫描个案的等百分位。 基于以下标准之一,生成一些分箱化类别,使得每个分箱中的个案数相等(对于百分位,使用 Aempirical 算法):

分割点数量。 分箱化类别数是分割点数量加一。例如,三个分割点会生成四个百分位分箱(四分位数),每个分箱包含 25% 的个案。
宽度(%)。 每个区间的宽度,表示为个案总数的百分比。例如,值 33.3 将生成三个分箱化类别(两个分割点),每个类别包含 33.3% 的个案。
如果源变量包含的不同值相对较少,或者有大量个案具有相同的值,则获取的分箱数可能少于请求的分箱数。如果在分割点处有多个相同的值,则它们都将转到相同的区间;因此实际百分比并不总是完全相同的。

基于已扫描个案的平均和选定标准差处的分割点。 基于变量分布的平均值和标准差的值生成分箱化类别。
如果不选择任何标准差区间,则将使用平均值作为分割点来划分分箱,从而创建两个分箱化类别。
您可以基于一倍、两倍和/或三倍标准差选择标准差区间的任意组合。例如,选择所有三个标准差将生成八个分箱化类别 -- 每个标准差区间内两个分箱(三个区间共六个分箱),平均值上下超过三倍标准差的个案两个分箱。
8)“生成标签”按钮
在分割点设定完成之后,点击该按钮可以自动生成相应的值标签
9)“反向刻度”复选框
默认情况下,新的变量的值是从1到n的升序数列,勾选“反向刻度”会变成从n到1的降序整数。
例子:把年龄段进行分组。
打开某个数据文件,选择菜单【转换】--【可视分箱】,得到如下结果
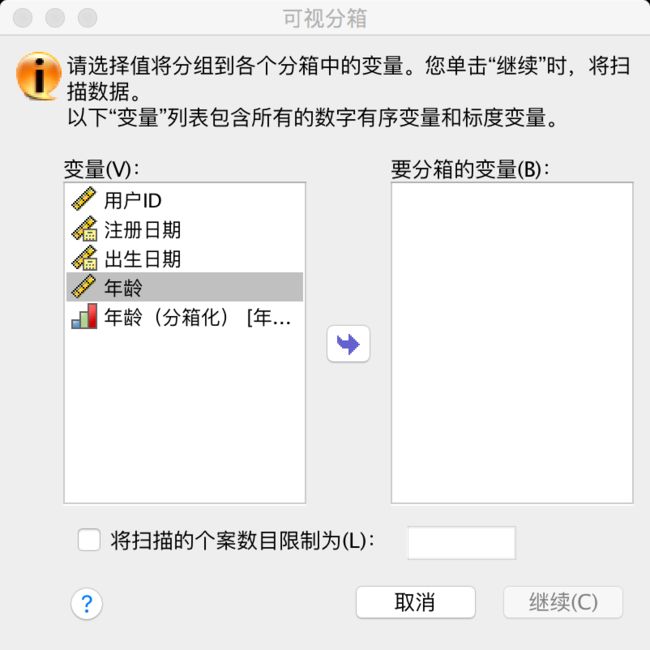
选择想要分组的变量,拖到右侧的框里
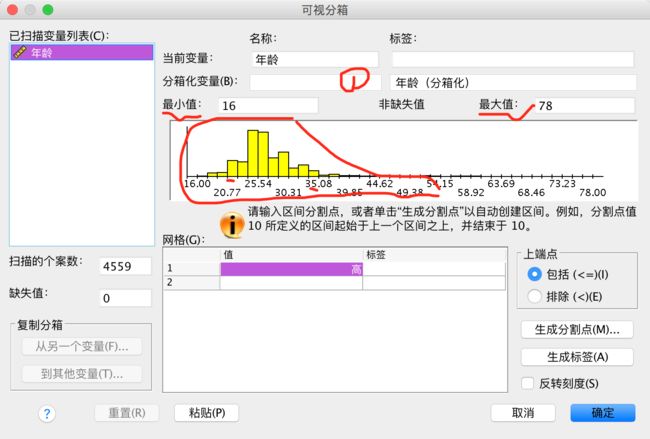
在第一区域可以自定义变量组的名称,比如“年龄段”。
从系统给出的柱状图中我们发现:
最小值为16,最大值为78,并且数据大多集中于20--35之间,因此我们可以如下分组:
<=20 / 21--25 / 26-30 / 31-35 / 36+
有两种方法:自动分组和手动分组
自动分组:中间区域只能等分,点击【生成分割点】
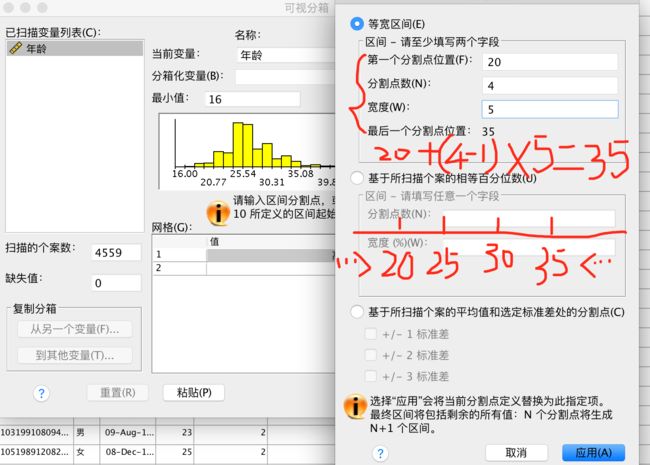
分成5个区间需要4个分割点,且中间的区域只能等分,计算规则如图所示
点击【应用】结果如下
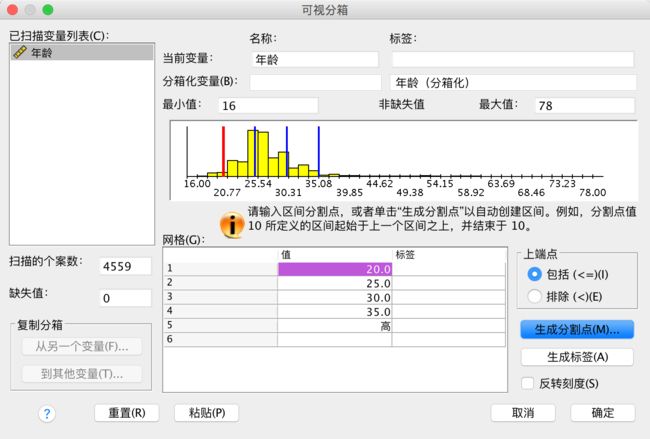
点击【生成标签】就可以得到如图所示的标签说明
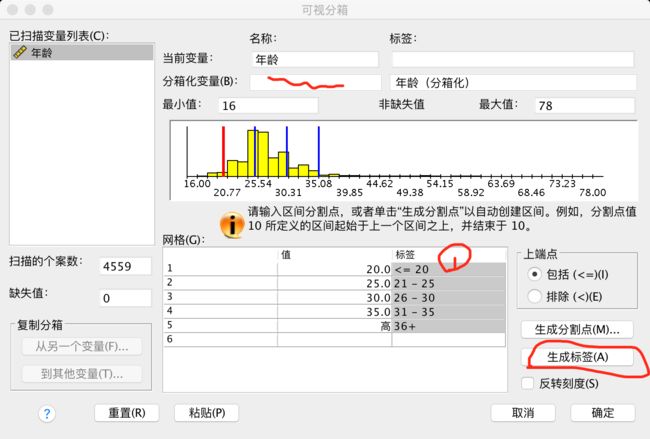
第二种方法是手动分组,非常灵活,可以不等分分组。
操作方法如下:
在第一区域输入要分组的节点值,然后点击【生成标签】即可
即输入20、25、30、35后点击【生成标签】得到如下结果:
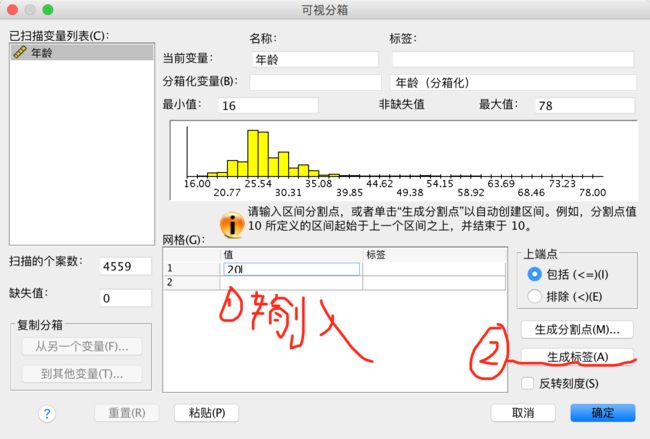
点击【确定】,数据表中新生成了一个变量”年龄段“
