0x00 写在前面
VMProtect虚拟机保护软件是业界公认的高强度软件保护工具。VMP除了具有常规的IAT保护、资源保护、反调试、完整性校验、运行时壳等保护手段以为,其最为人痛恨的是虚拟化保护。通过将原始的二进制汇编代码转化成语义等价的虚拟机字节码(也常称为PCODE,伪代码),并使用自定义虚拟机(或称字节码解释器)对字节码进行解释执行。想恢复原始的代码,必须分析虚拟机本身,大大提高了逆向分析的难度。
据笔者目前查到的资料,尚无公开的工具或方法可以进行VMP虚拟机字节码到原始二进制代码的还原。
个人觉得主要原因在于VMP虚拟机的RISC栈机体系结构与x86的CISC体系结构差异巨大。
如x86的一条指令如mov eax, [ebp+0x100],转化为VMP伪代码会变成类似如下的代码:
push ebppush 0x100addpop eflpop tmppush tmppop eax
(实际上ebp, efl, tmp, eax都会对应VMP的虚拟寄存器,这里为了方便表达暂时这么写)
一条CISC指令转化成RISC栈机指令时会发生巨大的指令膨胀。想将膨胀后的伪代码还原为一条CISC汇编指令是很困难的。
1. 如果单纯依靠模式规则的匹配,这么必须收集非常多的膨胀规则,需要付出巨大的人力代价,开发难度高,却不一定有好的效果。
2. 由于VMP的寄存器轮转问题,确定指令的真实寄存器是很困难的。(2009年中国软件安全峰值 Bughoho的PPT 《VMProtect的逆向分析与静态还原》中详细描述了寄存器轮转并提出了解决方案,但这种方案比较复杂,开发难度比较高。)
3. VMP版本更新,膨胀规则可能会稍有变化,工具通用性会非常差,必须持续跟踪不同版本。
对于CISC指令集虚拟机的还原难度会有一定的降低(但也很难),已有的工作可以参考DeathWay的Oreans
UnVirtualizerOD插件(http://bbs.pediy.com/thread-192434.htm),对早期Themida\Code
Virtualizer的CISC机可以做到很好的代码还原,还原出的指令基本和原始指令一致,非常优秀的工作!
对于VMP则还没有见到有公开的可用的,可以直接还原成原始代码的工具开放出来。但也有很多前辈的研究成果。部分如下:
FKVMP:nooby&fengyue大佬开发的插件,应该耳熟能详。nooby是很早研究VMP插件的前辈,FKVMP可以进行handler的识别得到伪指令序列,早期神器。
VMP分析插件v1.4:zdhysd大佬开发的(http://bbs.pediy.com/thread-154621.htm
)毫不过分的说这里目前市面的可以见到的最好用的VMP分析插件,没有之一。可以自行添加handler识别规则和化简规则。除了基础的识别handler之外,最酷的功能是表达式化简功能,可以将VMP伪代码转化成可读性更好的表达式,并进行了数据流分析进行表达式化简,内置近100条化简规则,化简后的表达式可以看到和原始代码相当接近的语义。非常强大!小问题是由于不是常见的汇编代码或C代码,阅读起来仍不是特别方便。
ZVM:zvrop
开发的工具,开放了源码(http://bbs.pediy.com/thread-155215.htm)根据文档说明该工具是可以直接将早期版本的VMP还原为汇编指令的,工作覆盖从handler认识到伪代码收缩转化,非常全面。系统非常复杂,6万行C++实现。不过我还没有编译运行过,不确定效果如何(有兴趣的同学可以试试,回帖说明,多谢)
其他还有Zeus、VMSweeper、OoWoodOne插件等等不多介绍。
国外的一些成果包括:
VMAttack: IDA VM分析插件, 2016 IDA插件第2名(https://github.com/anatolikalysch/VMAttack)
VirtualDeobfuscator:某年blackhat上的议题
(https://github.com/jnraber/VirtualDeobfuscator
Blackhat视频:https://www.youtube.com/watch?v=hoda99l5y_g )
这个工具是通过化简trace除去虚拟机的逻辑,然后留下指令的逻辑方便分析。思路很清奇。不过我测试对VMP效果一般。按文章描述对CISC指令集似乎效果会好一些。
0x01 基本思路
铺垫作完了,这里才是关键部分,介绍一下我想到一个进行代码还原的思路。
前面已经讨论过,将VMP伪代码直接还原成汇编代码难度非常大,除了需要人工分析大量的匹配规则,还必须解决寄存器轮转问题。
这里我们不考虑完全精准还原,对于逆向分析上,我觉得保证两点即可:1)逻辑正确,即还原出的代码与原始代码语义等价。2)可读性好、易理解。VMP伪代码之所以让人头疼的原因就在于难以阅读和理解,单条伪指令语义很简单,但成百上千条伪指令让人很难一眼看出其表达的算法含义,逐条分析会大大消耗分析人员的耐心,必须寻求自动化的方法。
好了,这就确定了我的目标:将VMP伪代码还原成语义等价易读的代码(如汇编或者C代码)。
同时因为自己代码能力有限且时间有限,在保证目标的前提下我希望尽量降低开发难度。
VMP分析插件v1.4中生成的表达式其实和我的想法已经十分接近,但由于不是汇编或者C,可读性还是稍差一点点。另一方面,为了化简表达式,插件中引入复杂的数据流分析,开发难度很大。
提到化简,很容易让人联想到编译优化中的化简。编译优化的活跃变量分析、控制流分析可以极好的处理常量传播、死代码的情况,那么能否将编译优化规则加到VMP伪代码上?
这就需要将VMP伪代码转化成常见编译器(gcc、clang)能处理的形式。首先想到的是LLVM,但开发过程用到LLVM相关的库,开发和调试都比较困难,后来直接利用C作为中间代码进行转化。
为了保证优化顺利进行,必须转化成容易优化的代码。其中关键的规则是,尽量使用局部变量。将VMP虚拟机的虚拟机寄存器变成C语言的局部变量、虚拟栈作为局部变量数组。说到这里估计会有人糊涂了,举个例子:
原始C代码: a = b;
编译成汇编后可能会变成: mov eax, ebx。
经过VMP之后变成:push R1; pop R0。 (R1是ebx,R0是eax)
用我们的方法变成C语言,伪指令会变成C代码:
sp -= 4; //分配栈stack[sp] = R1; // push R1R0 = stack[sp]; // pop R0sp += 4; //恢复栈
这段C代码编译器在优化(比如gcc O3)过程会将直接化为R0=R1。
惊喜出现了,这和最初始的C代码a=b岂不是(基本)一样的么?
这是超级简化例子,实际C代码 a = b在编译的时候会涉及栈变量的读写,比如可能变成
mov eax, [ebp + 4]mov [ebp+8], eax。
这个时候变成VMP指令会生成内存读写指令。转化成C代码之后可以将内存读写指令变成指针读写,编译器的别名分析也能优化类似的代码,细节就不多讨论了。
再举一个VMP特点的例子, 即NOR逻辑,也就是not not and逻辑。VMP中的与、或、非、异或、减法都通过NOR逻辑实现。一条xor eax, ebx指令,会产生大量的VMP伪代码,通过多次NOR运算,达到XOR的效果。
用C语言的宏表示如下:
#define NOR(a,b) ((~((uint32_t)(a))) & (~((uint32_t)(b))))#define NOT(x) NOR( (x),(x) )#define AND(a,b) NOR( NOT(a), NOT(b))#define OR(a,b) NOR( NOR((a),(b)), NOR((a),(b)) )#define SUB(a,b) NOT( NOT(a) + (b) )#define XOR(a, b) NOR(NOR(a, b), AND(a, b))
这个时候又能展示编译器的强大优化能力了,如果编译如下C代码
uint32_t a,b;scanf("%d %d", &a,&b);printf("%d %d %d %d %d",SUB(a,b), XOR(a,b), NOT(a), OR(a,b), AND(a,b));
使用gcc -O3编译优化,得到的结果程序拖到IDA中可以得到如下的伪代码
__isoc99_scanf("%d %d");printf("%d %d %d %d %d", v4 - v5, ~(v4 & v5) & (v4 | v5), ~v4, v4 | v5, v4 & v5);
使用clang -O3编译优化,效果如下。
__isoc99_scanf("%d %d", &v5, &v4);printf("%d %d %d %d %d", ~(v4 + ~v5), v5 ^ v4, ~v5, v5 | v4, v5 & v4);
Bingo!可以看到复杂的NOR逻辑没有出现优化后的代码中, 除了sub和xor有一点小问题以外,not, and, or被化简处理的非常好。
如果采用传统的规则匹配来化简NOR逻辑,则需要加入很多对应的匹配规则。而如果某一天这些规则发生变化,则又需要修改匹配规则。当使用编译器来化简,问题就变得简单了许多。
0x02 实现
基本思路有了,基本实现方法是:
1. 提取VMP保护后代码中的VMP伪指令
2. 将伪指令转化成C语言变量操作的语句
3. 转化后的文件使用gcc或者clang进行编译
4. 结果文件放到IDA中还原回C代码。
提取伪代码这一块前面的工作已经比较成熟,不再花时间造轮子了。直接使用VMP分析插件v1.4进行提取,伪代码格式类似如下:
0040751C |. 0C vPushReg4 vR3 DWORD _t17 = EBP0040751D |. 7B vPushVEsp DWORD _t18 = 300040751E |. 9C vPopReg4 vR7 DWORD _t19 = 300040751F |. 24 vPushReg4 vR9 DWORD _t20 = _t1300407520 |. 08 vPushReg4 vR2 DWORD _t21 = ESI00407521 |. 00 vPushReg4 vR0 DWORD _t22 = EDI00407522 |. A6 00 vPushImmSx1 0 DWORD _t23 = 000407524 |. 1C vPushReg4 vR7 DWORD _t24 = 3000407525 |. 3E FC vPushImmSx1 0FC DWORD _t25 = 0FFFFFFFC00407527 |. 39 vAdd4 DWORD _t26 = 2C; DWORD _t27 = AddFlag(_t25, _t24)00407528 |. B8 vPopReg4 vR14 DWORD _t28 = _t2700407529 |. 52 vWriteMemSs4 DWORD _t29 = 00040752A |. A6 FC vPushImmSx1 0FC DWORD _t30 = 0FFFFFFFC0040752C |. 1C vPushReg4 vR7 DWORD _t31 = 300040752D |. 39 vAdd4 DWORD _t32 = 2C; DWORD _t33 = AddFlag(_t31, _t30)0040752E |. 8C vPopReg4 vR3 DWORD _t34 = _t33
中间的vPushReg4 vR3即是插件中定义的伪指令格式,后面是插件生成的表达式。
如前面所述,为了进行优化,将VMP的16个虚拟寄存器作为16个局部变量。虚拟栈作为局部变量数组,vESP作为数组下标指针。将所有指令转化成C代码。
如vAdd4转化成如下代码
uint32_t op1 = pop4();uint32_t op2 = pop4();uint32_t result = op1 + op2;uint32_t flag = add_flag(op1, op2, result);push4(result);push4(flag);
其中push4和pop4则为向虚拟栈数组中赋值的内联函数。
将所有虚拟指令进行类似的转化,即得到转化后的C文件。使用gcc或者clang进行O3编译,输出文件就可以拖到IDA中看还原效果了。
其他具体细节还有很多,这里不多介绍,有兴趣的可以留言联系进行深入交流。
0x03 还原效果
完成转化后将转化后的C文件使用gcc或者clang进行O3优化,得到输出文件,即为VMP还原后的代码。
这里使用测试程序all_op2.exe,使用一个VMP 1.81 demo版本加虚拟化all_op2.vmp.exe(因为只是测试方法,使用了比较弱的版本)。
使用VMP分析插件v1.4提取伪代码为all_op2_vmp_1.81.txt。
利用前面的方法转化成C代码,再进行使用gcc和clang进行编译优化,得到all_op2.gcc和all_op2.out.clang文件。效果对比如下(为了显示方便,手动将几个默认为int类型的变量修改成了_DWORD*型,不影响逻辑):
all_op2.exe在IDA中反编译结果:

all_op2.gcc在IDA中反编译的结果:
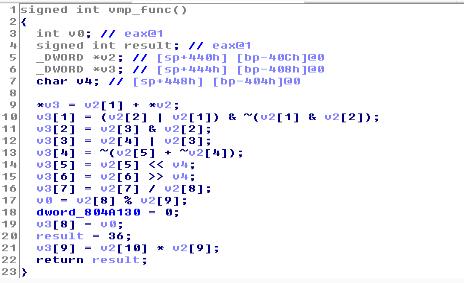
可以神奇的发现主要代码逻辑已经被清晰的还原出来了。
要注意到代码中是包含数组访问的、同时还有与、或等逻辑运算,都较好的还原了出来。
为了不占用页面不贴汇编代码了,汇编代码可以自己看附件中的程序。
0x4 方法的不足
这个方法是最近发现并简单实现的,很多细节都无法照顾,而且方法本身也有很多局限。
1. 最主要的问题是不能处理跳转。
可以看到前面的示例中是不含条件和循环的。因为VMP处理跳转和条件跳转的时候会将这些直接跳转全部转化为间接跳转。以条件跳转为例,VMP会先将两个跳转的地址压处栈中,再根据比如的flag计算值决定使用哪个地址作为跳转目标。这一部分很难直接利用编译器进行优化。
目前还没有想到太好的解决方法。
当然使用VMP分析插件v1.4中匹配并化简规则的方法是可以解决问题的,但与本文的方法论不一致。
而在编译优化角度上,我还没有想到好的可以将VMP间接跳转化成直接跳转的方法。
主要问题在于VMP间接跳转直接提供了指令地址,跳转到指令地址上。而转化成C代码后,指令地址信息已经丢失了。无法将要跳转的地址与C代码中的语句关联起来。具体来说,对于一条jmp指令如:
汇编上表示如下:
label:.... (代码)jmp label
VMP表示如下:
0x401000:... (代码)...0x402000vPush 0x401000vJmp
vJmp会跳转到栈顶的地址去。即0x401000这个地址。
而C代码级别没有地址信息,也就无法确定0x401000个地址究竟是要跳转到哪里。
(虽然可以 (*((void*)() 0x401000))()这样进行跳转,但没有任何意义,因为0x401000处并未放着转换后的代码。
考虑过用一个跳转表进行转化
比如
label1:...(代码)label2:switch(addr){case 0x401000: goto label1;case 0x402000: goto label2;}
但这种switch结构GCC很难优化。会生成大量未优化的代码,十分影响可读性。
2. 减法和异或
减法和异或优化的不好。减法有时候不能直接优化成sub,而是变成 a-b = ~(~a+b)的形式。
最常见分配栈空间的指令,如sub esp, 8,如果优化失败,接下来的指令都无法优化,会产生大量的可读性特别差的代码。
可以看到前面的例子中原始代码是不含局部变量的,也就是不含sub esp类的指令的。
3. 无法恢复完全相同的汇编、恢复出的代码不能运行
由于虚拟栈作为了局部变量数组,这种方法编译生成的汇编码比较冗长,也难以阅读,不过不影响IDA的反编译。
IDA反编译时似乎也会进行简单的优化,因此显示效果还不错。
受方法本质的限制,是不能恢复出和原始代码一模一样的汇编的,也不能运行。但代码逻辑是基本一致的。
0x5 写在最后
这里说一下私心,之所以敢于在方法和工具不成型的时候就提前把方法分享出来。是希望有感兴趣的和懂VMP的大牛指点一下。论坛上有很多前辈在这方面研究十分深入,经验丰富。这个方法算是拍脑袋想到的方法,存在不少问题。希望大牛们对提到的几个问题有什么改进的思路,或者发现了其他可能存在的问题,都麻烦留言不吝赐教。(尤其是前面提到间接跳转问题,让我十分头疼。如果大大们有好的想法,请一定留言指教)
或者对VMP、LLVM、编译原理、数据流分析了解的牛人,觉得此方法有完善成实用工具的可能,愿意抽时间与我一起进行工具开发,学习讨论,更十分欢迎。
测试程序放在附件里,如果有感兴趣的,请务必留言联系。
转化的源码暂时不放出来了,只有几百行,如果理解我的思路,自己实现也很简单。
如果以后做出实用的工具的话肯定会放出来。现在就不献丑了。
多谢各位。
本文由看雪论坛 穆雷 原创
转载请注明来自看雪社区