Introduction
如果您必须在SQL Server的任何很大程度上使用分层数据,然后你就知道有很多不同类型的等级结构,它们都有自己的优缺点.不幸的是,每个结构的优点通常不会与其他结构的优点重叠。
我最喜欢的两种层次结构是 The Adjacency List Model (邻接列表模型)和 The Nested Set Model(嵌套集模型,也叫前序遍历树模型lft,rgt).
我很喜欢邻接表,因为它们很容易让人理解,而且很容易做出改变.
如果一个邻接表出了问题,即使是一个人,也可以相对轻松地修复它们,因为每个节点都知道只有一个节点。不幸地是,它们很难使用,因为它们需要相对缓慢而复杂的过程或递归代码来遍历层次结构,而不需要做一些更复杂的事情,比如聚合数据和为人类的消费排序。邻接表的底线是,它们易于维护,但使用起来却很缓慢和复杂.
我也很喜欢嵌套集,因为它们很容易使用,而且在所有的东西上都很容易使用,因为这些东西在做的时候都很慢而且很麻烦。嵌套集的问题在于,它们对于人类来说是非常难以组装和维护的。即使在计算机的帮助下,在层次结构的开始处插入一个新的节点,也需要重新计算组成嵌套集的大多数锚点。此外,如果某些东西在锚点上出现了混乱,那么大多数人几乎不可能及时地修复它们,因为单个节点与多个节点相关,而不是一个节点。我不使用相对新的层次型结构数据类型,原因与前面提到的原因相同。
为了获得邻接表和嵌套集的优点,这两种方法的缺点都没有很多人想象的那么困难。你要做的就是在每次你改变邻接表的时候,从邻接表中重建嵌套的集合。由于大多数层次结构都比较小,而且不经常改变,所以大多数情况下,使用传统的堆栈方法进行这样的重构是可以接受的。
但是,如果有一个有一百万或更多节点的层次结构呢?如果您需要频繁地更改这样一个大的层次结构,该怎么办?如果你有一个来自第三方的新的百万节点邻接表,老板在你的脖子上呼吸,现在需要改一下吗?从大型的邻接表中构建或重新构建嵌套的集合可能不会在一夜之间使用传统方法完成如此大的层次结构,那么,你会怎么做呢?你会做什么呢?
答案是:做一点数学计算,然后得到一个理算表。
本文的目的是向您展示如何将一个”格式良好“的”邻接表“转换为嵌套的集合,这比您所想象的要快得多。
Who This Article Is For
我在过去写的文章中,大部分都包含了你需要知道的所有东西来完成这篇文章。在层次结构中,整本书,成百上千的章节,以及成千上万的互联网文章都是关于这个主题的,我不可能在一篇文章中涵盖所有的方面.出于这个原因,我必须在本文中做出一些假设,例如,我必须假设您已经知道了什么邻接表和嵌套集结构,以及它们是如何使用的。我必须假设您知道如何在一个邻接表中防止"循环"。我必须假设您已经知道了什么是统计表,以及如何使用它来替换某些类型的循环。而且,我必须假定您在某些常见的t-sql函数中有一些基本的知识,比如知道”CTE“和"递归CTE"是什么以及它们是如何工作的。
我可以帮助您开始了解什么是统计表,以及如何使用它来替代特定的循环,将您的内容引用到SQLServerCentral上的文章:
http://www.sqlservercentral.com/articles/T-SQL/62867/
最后但并非最不重要的是,我编写这篇文章和代码,以便任何人都可以使用SQL Servel 2005(以上)来享受高性能层次结构带来的好处,这也是为什么我在本文中不涉及"新"层次结构的原因,它在SQL Server 2005中是不可用的.
Some Jargon
我还假设你已经知道了大多数的等级术语,比如什么是"节点" 和 "边缘" 但是我从(多层次营销)产业中借用了一些术语,以使我的解释更简短,但愿如此,更容易理解。
Downline (沿下行线,下线)
因为大多数的组织结构图和类似的树都是在顶部的根节点和底部的叶节点上显示的。某些类型的企业称为"MLMs"(多层营销)使用”Downline“一词来简化”给定节点的所有子节点“。换句话说,它包含从给定节点到叶节点的所有子节点。它来自于一个事实,即所有的子节点都是在一个组织结构图上的给定节点上"拥有"自己的。
Upline (上线)
与”Downline“ 相反。基本上,它意味着"给定节点的所有祖先",如果你要在一个给定节点的Upline的所有节点上涂色,在层次结构的每个层次上,从给定节点到根节点的只有一个颜色节点.正如你在这篇文章中所看到的,在我们将要使用的一些简单公式中,这是一个非常重要的概念.
Sort Path (排序路径)
你可能知道这个一个”Materialized Hierarchical Path“或者类似的术语,它包含了一个给定节点的整个upline的连接(并且通常是分隔的)列表,根节点是最左边的,而给定的节点则是最右边的。很多人不知道的是,它也可以用于排序,所以我们把这个词简化为"排序路径"。
Test Data (测试数据)
这篇文章的前提是基于对一个过程的一个非常高的性能替换的巨大声明.这通常要比我们大多数人在代码中忍受的时间长得多。当然,这样的声明必须以代码形式的可论证的证据来支持。问题在于(请原谅双关语),大层次结构的数据不会在树上生长。在Interner上,几乎没有一组大型的分层数据可供使用,虽然有一些代码可以构建一个,它们通常需要较长的比我们愿意等待,以建立甚至相对较小的测试层次结构。
我们还需要一个更小的,更容易理解的层次结构,我们都可以将其与易于显示和理解的关系图联系起来。
最后但并非最不重要的是,我们需要能够轻松地在更大的,更小的层次之间来回切换,而无需更改任何代码。
出于这些原因,我创建了两个存储过程,一个是快速创建可编程的大型层次结构,另一个是创建一个固定大小的层次结构,用于解释各种方法。由于代码下降并重新创建了表,所以所有的测试代码都是在TempDB中执行的,所以我们不会意外地覆盖您可能正在使用的实际表。
这两个存储过程位于”层级代码“中。在本文末尾的”参考资料“一节中压缩文件。如果您打算在本文中继续学习,我建议您解压该文件并同时执行这两个脚本。 (BuildSmallEmployeeTable.sql and BuildLargeEmployeeTable.sql) 创建两个存储过程。
这两个过程都构建具有相同结构的表,它们包含一个EmployeeID, ManagerID, and EmployeeName,这两种代码都通过使用它们的所有其他代码实现了最佳性能的索引。(你可以使用这些索引来对自己的表进行交叉检查。)这两个表都被命名为"dbo.Employee" 不可能同时存在。
作为一个边栏,我使用了TempDB几乎所有的试验都是在一个开发箱中。
我只是不想冒着被错误地删除某人通常被命名员工表的机会。
The 'BuildLargeEmployeeTable' Stored Procedure
理解了这个存储过程是如何工作的,远远超出了本文的范围(尽管您对代码有大量的文档记录) the "dbo.BuildLargeEmployeeTable" stored procedure将在”dbo.Employee“在TempDB数据库中建立一个良好的Adjacency List。第一个(必需的)参数用于识别层次结构应该包含的节点的数量,并在我的4个处理器(i5)上构建一个一百万个节点层次结构,在7秒内使用6GB的笔记本。您可以为第二个(可选的)参数添加一个非零值,以随机化ID,这种方式更接近现实生活中的一个大层次结构。当然,这需要一点额外的时间,但我相信你仍然会对它的工作速度感到满意,尤其是当你意识到它在17秒内完成了100万行。
如果您想了解更多的细节,请查看存储过程中的注释。下面是这个存储过程的示例调用,以创建一百万个节点Employee表
EXEC dbo.BuildLargeEmployeeTable 1000000,1;
The "BuildSmallEmployeeTable" Stored Procedure
The "dbo.BuildSmallEmployeeTable" stored procedure是非常直接的,它有条件地放弃“dbo.Employee“表并使用固定数据重新构建它,我们将在本文中使用这些数据来解释新转换过程中发生了什么。
下面是对存储过程的调用,以构建小型Employee表。它不接受任何参数。
EXEC dbo.BuildSmallEmployeeTable;
这个图片的数据是由 "dbo.BuildSmallHierarchy" stored procedure创建的。如您所见,这是一个小型的组织结构图。
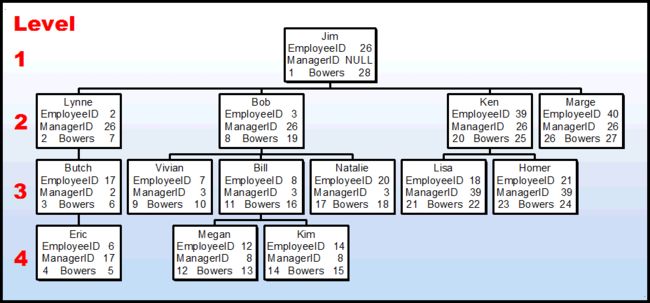
每个节点都有4行数据(总共5列信息),下面的前3个项目包含在构建中"dbo.BuildSmallEmployeeTable" stored procedure.
1.第一行包含employee的名称,并包含在employee表中。在讨论节点时,仅包含个人的名称,并且不会出现在我们将要构建的最终表中。
2.第二行包含EmployeeID,并包含在Employee表中。
3.第三行包含employee的ManagerID,并包含在employee表中.
4.第四行包含两个不包含在邻接表中的信息,这一行的两个数字是我们尚未构建的嵌套集的”左“和”右“值。
What are "Bowers"?
在大多数关于嵌套集的讨论中,嵌套集的“左”和“右”值的两个数字,都存在于称为“lft”和“rgt”的相当普通的列中。BWAA-HAAA ! ! !我现在可以看到Abbott 和Costello。
Costello:哪一列是排序的正确的列?这个(指向“rgt”列)?
Abbott: 不,你需要按左栏排序。
Costello: 你确定那是正确的专栏吗?
Abbott: 不,我只是告诉你这是左列,这是正确的一列。
为了避免这种混淆,我将这些列成为”LeftBower“ 和”RightBower“,Why "Bower"?大型船前的两个大锚被称为”Bower“,因为这两个数字是嵌套集合中的每个节点的”锚“这似乎是合乎逻辑的。
The Push Stack Method
在我们开始将一个邻接表转换为嵌套集的新过程之前,让我向您展示传统的方法,也称为“推栈”方法("Push-Stack"),它是非常程序化的(RBAR1 on steroids),这是它在组织结构图上的样子。
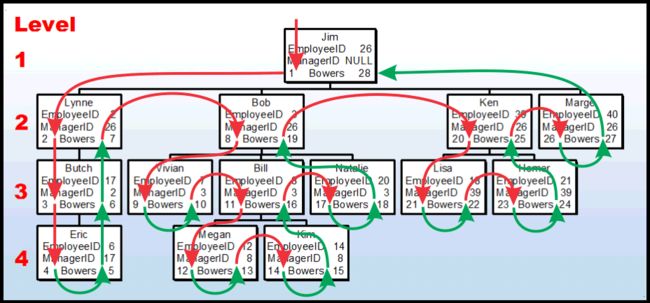
如果你看left 和 Right Bowers 从1 开始在Jim节点上,每个红色箭头表示一个”push“的数据 到 一个 "stack"上。每个绿色箭头表示从”stack“中取出(”Pop“),"Pushes"创建 LeftBower 和"Pops"创建 RightBower.
图没有显示的是,每次push 做一个加入 选择(SELECT) 在原始表的牺牲副本和包含嵌套集的最终表之间。每次push还包含两个表之间的连接插入,然后从牺牲表删除。每个Pop都执行相同的初始连接,然后再最后的表上进行更新。
这意味着,除了根节点,每个节点都有两个连接选择,一个连接插入,一个删除和一个更新,以便构建嵌套的集(Nested Sets)。对已一百万个节点层次结构来说,这也意味着至少有500万的执行计划需要被评估(即使被重用)并执行。
所有这些都意味着缓慢和资源密集。你还可以添加”deceitful“这个词,因为您可能会被骗去想,如果你在一个只有一万个节点的小层级上运行 push-stack方法,那就没那么糟糕了。当您在更大的层次上运行时它,您很快就会发现随着节点数量的增加,代码会变得非常糟糕。
我修改了我在网上找到的一些push-stack代码,通过更改表名、列名和相关数据类型来匹配我们的测试数据生成过程所生成的员工(Employee )表。它的速度非常慢,所以我再次调整了它,使它的运行速度提高了三倍,把它转换成SQL Server专有代码,并将一些索引添加到它所创建的表中,以其他标准来看,它仍然是缓慢的。
下面是”push-stack“转换代码的4个不同运行结果。您可以看到,在1,000和10,000个节点之间出现一个主要性能问题的第一个迹象,因为10次节点的数量是70倍,而不是10倍。
Duration for 1,000 Nodes = 00:00:00:870
Duration for 10,000 Nodes = 00:01:01:783 (70 times slower instead of just 10)
Duration for 100,000 Nodes = 00:49:59:730 (3,446 times slower instead of just 100)
Duration for 1,000,000 Nodes = 'Didn't even try this'
如果你希望自己尝试相同的实验,那么我最终使用的push-stack的代码也在 "HierarchyCode.zip" file中,在本文末尾的参考资料一节中的压缩文件。
现在你知道为什么人们开了这么多不同的方法来维护Nested Sets,使用传统方法从简单到维护的邻接表转换到高性能的Nested Sets 结构,花费的时间太长了。
不过,这种情况即将发生改变。
Set Based Code to Calculate the Bowers(基于设定的代码来计算Bowers)
我们已经看到了典型的RBAR1 push-stack方法将邻接表转换为嵌套集的方法是无法快速完成我们想要的,特别是如果我们有一个大的层级,有一百万个节点或更多。如果我们推断转换一百万个节点需要花费的时间,我们的运行时间大约是2天,当然不是一夜之间就能完成的。
所以,让我们用一个小数字和一个Tally Table.来构建一个更好的方法。我们还会看到,到目前位置,可能会出现一些问题,使得大多数人无法将大型的邻接表和嵌套表相结合。
Calculating the Left Bower(计算left Bower)
计算left Bower的数学计算非常简单,让我们使用之前看到的相同的小层次组织结构图来看看它是如何工作的。
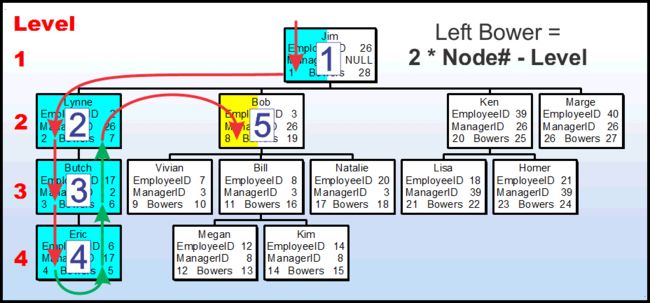
在这个例子中,我们尝试计算Bob的Left Bower,你会变得感激Bob,因为我们会在这些例子中让它死。
注意节点的颜色。如果我们使用push-stack方法,它们代表了我们已经通过(或触摸)的节点,以获得Bob的Left Bower。如果一个节点是全彩色的。那么我们已经通过了两次节点(触及了两个节点),我们知道这些节点的Bowers.如果我们只通过触摸节点一次,只有”已知Bower“的一面被着色了。我们在第五个节点(Bob的节点)上,但是还没有计算Right Node,这就是为什么它的颜色与其他节点不同,即使我们现在正在触摸主节点的的Left Bower.
所以,首先,Bob是链中的第五个节点,它是由push-stack方法形成的,为了本文的目的。我们称这个数字为"节点号",每个节点有两个Bower,如果我们把每个节点的Bowers的数量 乘以Bob的节点号,我们就得到了”10“。不过,我们还没有完成。
在这五个节点中,有多少个Bowers的”push-stack“进程还没有触碰?这些是由部分颜色的节点的不同着色部分所指示的。在这种情况下,答案再次是”2“,这就是我在这篇文章的行话中提到的关于”upline“的重要概念。事实证明,给定节点的”level“(Bob节点的2)将总是正确指示Bowers的数量,如果我们使用的是push-stack方法的话。不要忘记,upline永远只包含一个级别的节点。
把所有的数字都插入到我在上面的图表右上角的公式中,我们最终会得到(2*5)-2 或者”8“,Bob的Left Bower是”8“。
让我们试着对Kim做同样的事情。
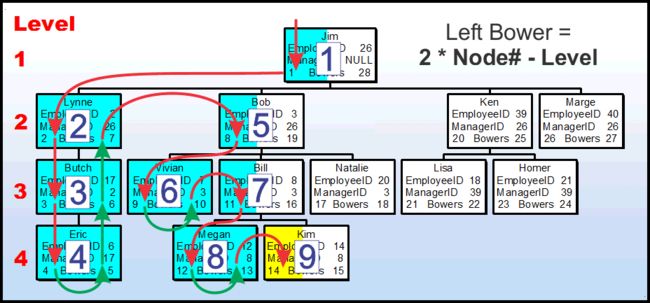
使用和Bob一样的概念,我们将节点编号按”push-stack“方法进行顺序编号,而且,Bowers是否已经被"触碰"(完全彩色的盒子),或者仅仅是Bowers的"触碰"(半彩色的盒子)。注意,我们只接触了Kim的upline Left Bower的每一个节点,和这些节点的编号(数量?)和Kim's的水平相同,即是”4“,Kim的节点号是”9“,因为它是第9个节点,被push-stack方法触碰了。
使用和之前一样的公式,我们得到(2*9)-4 或者 18-4 或者 14 我们能正确的计算出kim的Left Bower.
最明显的问题是,我们需要知道节点号,并且它们需要与使用push-stack方法相同的顺序。除此之外,我们还需要知道level,我们如何让做到这一切呢?我们需要一个事例来解决这个问题,'2 * (insert miracle here) – (insert another miracle here)',实际上,我们需要四个miracles(示例)
1) 查找并计算节点
2) 正确的顺序
3) 计算level.
4) 要比push-stack方法快数百倍甚至千倍.
The Miracle of the 'Sort-Path'
同样地,”sort-path“的一个专有名称是”Materialized Hierarchical Path“,
对于每个节点,它包含给定节点的upline中节点的整个列表,其中最左边的根节点和最远的右边节点.由于我们在每个”sort-part“中都有大量的节点,所以每个节点都需要尽可能紧凑的格式,但也需要以相同的格式存储每个节点,以满足我们的需要。这是一个层级结构的工作方式,除了层级结构使用(按位计数法)符号HierarchyID ,而不是真实的符号(EmployeeID),就像我们将要做的那样。
每一个EmplyeeID都作为个整数存储在邻接表(Employee表中),一个整数是4个字节,不管它包含的值是0还是20亿(举例),每个整数的值可以很容易地在BINARY 和 VARBINARY 数据类型中存储为4个字节。
来总结一下我们将要租的事情:
1.按照邻接表中的父/子关系,读取给定Level上的所有节点。
2.当我们读取给定级别中的节点时,将每个节点标记为有当前级别的数字。
3.当我们读取给定级别的节点时,将EmployeeID转为Binary(4),并将其与上一级的EmployeeID的二进制字符串连接在一起。这将构建”sort-part“
4.按照Srot-part显示行数,这将以相同的顺序对行进行编号,而push-stack方法将这些行进行编号。
5.一旦,1,2,3,4步骤的数据完成,就可以用计算Left Bower更新数据。
听起来像是一大堆复杂的工作,不是吗?但它不是。一个递归CTE可以很容易地完成所有的5步,但我碰巧知道,如果我们使用一些“分割”方法,并且只使用递归CTE来执行前4步,那么事情将会更快地运行。在这个过程中,我们将直接构建最终的表。
这是所有5个步骤的代码:
-- ===========================================================================
-- 1. Read ALL the nodes in a given level as indicated by the parent child relationship in the Adjacency List.
-- 2. As we read the nodes in a given level, mark each node with
-- the current level number.
-- 3. As we read the nodes in a given level, convert the EmployeeID to
-- a Binary(4) and concatenate it with the parents in the previous
-- level's binary string of EmployeeID's. This will build the
-- SortPath.
-- 4. Number the rows according to the Sort Path. This will number the
-- rows in the same order that the push-stack method would number
-- them.
-- ===========================================================================
--===== Since we're going to drop and create tables, do this in a nice, safe
-- place that everyone has.
USE TempDB;
--===== Conditionally drop Temp tables to make reruns easy(有条件地删除临时表以使重新运行变得容易)
IF OBJECT_ID('dbo.Hierarchy','U') IS NOT NULL
DROP TABLE dbo.Hierarchy;
--===== Build the new table on-the-fly including some place holders(动态构建新表,包括一些占位符)
WITH cteBuildPath AS
( --=== This is the "anchor" part of the recursive CTE.(这是递归CTE的”锚“部分)
-- The only thing it does is load the Root Node.(它所做的唯一事情就是加载根节点)
SELECT anchor.EmployeeID,
anchor.ManagerID,
HLevel = 1,
SortPath = CAST(
CAST(anchor.EmployeeID AS BINARY(4))
AS VARBINARY(4000)) --Up to 1000 levels deep.
FROM dbo.Employee AS anchor
WHERE ManagerID IS NULL -- The only thing it does is load the Root Node.(它所做的唯一的事情就是加载根节点)
UNION
--==== This is the "recursive" part of the CTE that adds 1 for each level这是CTE递归的部分,每一层都增加了1,
-- and concatenates each level of EmployeeID's to the SortPath column. 并将每个层次的EmployeeID连接到SortPath列。
SELECT recur.EmployeeID,
recur.ManagerID,
HLevel = cte.HLevel + 1,
SortPath = CAST( --This does the concatenation to build SortPath
cte.SortPath + CAST(Recur.EmployeeID AS BINARY(4))
AS VARBINARY(4000))
FROM dbo.Employee AS recur
INNER JOIN cteBuildPath AS cte
ON cte.EmployeeID = recur.ManagerID
) --=== This final SELECT/INTO creates the Node # in the same order as a
-- push-stack would. It also creates the final table with some
-- "reserved" columns on the fly. We'll leave the SortPath column in
-- place because we're still going to need it later.
-- The ISNULLs make NOT NULL columns.(最后的 SELECT/INTO 创建一个Node在相同的排序 将作为一个push-stack)它还创建了最终的表--”reserved“列on the fly,我们将把SortPath列留下,我们后面将要用到它。ISNULL 并不是空列。
SELECT EmployeeID = ISNULL(sorted.EmployeeID,0),
sorted.ManagerID,
HLevel = ISNULL(sorted.HLevel,0),
LeftBower = ISNULL(CAST(0 AS INT),0), --Place holder 补位数字
RightBower = ISNULL(CAST(0 AS INT),0), --Place holder
NodeNumber = ROW_NUMBER() OVER (ORDER BY sorted.SortPath),
NodeCount = ISNULL(CAST(0 AS INT),0), --Place holder
SortPath = ISNULL(sorted.SortPath,sorted.SortPath)
INTO dbo.Hierarchy
FROM cteBuildPath AS sorted
OPTION (MAXRECURSION 100) -- Change this IF necessary(必要时改变这)
;
--===========================================================================
-- 5. Once the data from Steps 1, 2, 3, AND 4 is complete, update that(一旦步骤1,2,3,4的数据完成更新计算Left Bower数据。)
-- data with the calculated Left Bower.
--===========================================================================
--===== Calculate the Left Bower
UPDATE dbo.Hierarchy
SET LeftBower = 2 * NodeNumber - HLevel
--SELECT * FROM dbo.Hierarchy
如果你第一次运行EXEC dbo.BuildSmallEmployeeTable 去构建小型Employee table ,然后运行上面的脚本,这是您将在新的dbo.Hierarchy table (层次表)中获得内容。
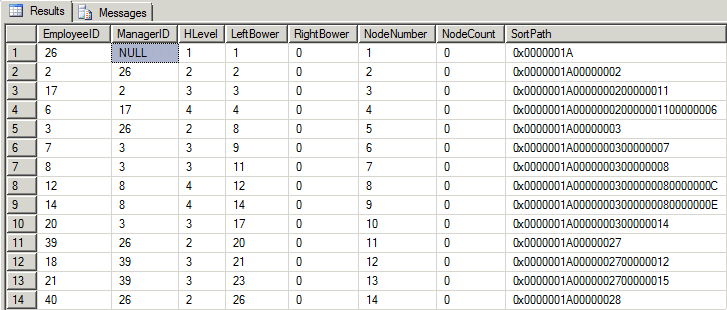
在SSMS查询结果中,将VARBINARY 数据显示为十六进制,如果您查看SortPath列,它包含每个节点的upline中每个EmployeeID的连接十六进制等价,您可以很容易地看到它是如何被用于排序的。还要注意,给定节点的upline的每个级别都包含在sort-part中。只需将SortPath列的每8个字符分组(从”0x“开始,每字节2个字符),您就可以看到每个EmployeeID对应的十六进制对应,这将在接下来的步骤非常重要。
另外,我们不需要保存表中的NodeNumber列,但是我把它放在那里,这样我们就可以很容易地验证使用它计算Left Brower的值在这个小而详细的层次结构上是正确的。
对了,上面的代码在我的笔记本上完成了10万个节点层次结构,在3秒之内!到目前为止,这比push-stack方法快998倍,即使在我们计算了Right Bower之后,一百万节点的速度也要快几千倍。如果您想尝试我们目前到目前为止所做的,执行
EXEC dbo.BuildLargeEmployeeTable 100000
构建一个10万个节点的Employee表,然后运行上面的代码.
Four miracles down. Three to go.
Calculating the Right Bower (计算 Right Bower)
就像有一个“简单”的公式来计算Left Bower,所以它是正确的。让我们看看这是如何计算”Bob”的。
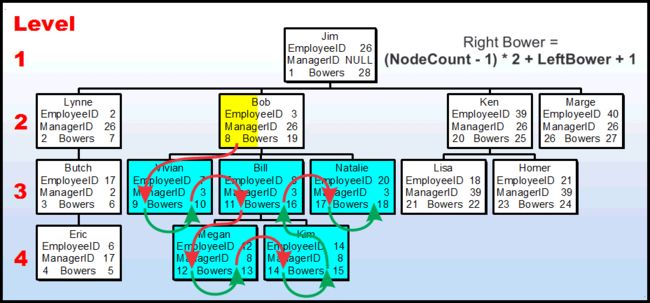
再一次,完全蓝色的节点表示我们已经“接触”两次的节点,如果我们使用的是“push-stack”方法。它由红色和绿色的箭头表示,我们也触摸了(并成功地计算了Bob的Left Bower,知道它是8,因为我们刚刚完成了计算。
如果我们找到Bob的所有节点,包括Bob,我们就会有6个节点,其中5个节点有2个Bowers计算(蓝色节点)和一个(Bob的节点),其中只有1个Bowers计算。就像上面图右上角的公式一样,如果我们计算所有的节点。
减去1(Bob的节点数量)所以我们只处理蓝色的节点(Bob的下一行),乘以Bowers每个节点的数量(2),再加上Bob的Left Bower,再加上Bowers已经计算(触摸)过的Bob(1),我们最终得到了正确的Right Bower.换句话说就是(6 Nodes -1) * 2 + 8 + 1 = (5 * 2) + 9 = 10 + 9 = 19.
对任何其他节点(甚至是Jim的节点)尝试相同的操作,并看到它对每个节点都有效。作为一个边栏,可以通过只计算蓝色节点来简化这个公式。不过,不这样做。这个公式是为了简化即将到来的计算步骤。
这里的问题是什么?答案是,我们还没有计算出Bob的下一行有多少个节点,我们还没有计算出Bob的下一行中任何节点的左或右的节点。这就像我们在计算嵌套集之前需要知道嵌套集。
我们还需要三个奇迹。我们需要:
1)找到Bob的下一行的所有节点。
2)计算它们的和
3)仍然尽可能快递完成它。
The 'Tally Table' Miracle("数据表"的奇迹)
如果我们执行代码生成小层次结构表(EXEC dbo.BuildSmallEmployeeTable)和运行Left Brower代码我们以前创建的,我们得到一个结果集看起来像下面的图形,当您看到它时,请记住,我说SortPath包含每个给定节点的upline中的所有节点。Bob的下线节点也不例外。在上面的图形中,Bob的节点信息以黄色突出显示。Bob出现在其他5个(蓝色)节点的SortPath中。这是Bob的downline。我们所要做的就是按级别将SortPath分开,并计算在SortPath中出现的每个EmployeeID的数量。
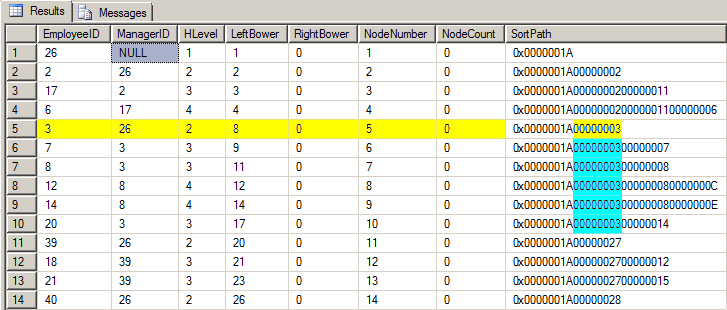
这就是一个特别形成的统计表的神奇之处。让我们编写代码来拆分SortPath节点,并以一种基于集合的方式一次性计算它们。
首先,我们需要在特殊的统计表中存储什么(我们将从这里调用“HTally”)?我们需要在SortPath中每个EmployeeID的起始位置。如果您还记得,每个EmployeeID都被保存为BINARY(4)二进制(4),这意味着每个EmployeeID在SortPath列中占用了4个字节。第一个EmployeeID从位置1开始,并持续4个字节。第二个EmployeeID从1开始的第一个起始位置开始4个字符,这意味着它从5开始,然后继续4个字节。同样,第三个EmployeeID从9开始,持续4个字节,以此类推。还请记住,每一组4个字节的垂直覆盖层(HLevel)。
换句话说,我们的HTtally 表需要有1、5、9等数字,它的级别与整个层次结构中一样多。我将使用一个真正的表格来保持代码的简单性,你当然可以在即时构建一个,使用Itzik ben-gan著名的“级联CTE”(简称“cCTE”)技巧。
这是构建HTally表的一种方法,在这种情况下,它将处理多达1000个级别。它只需要构建一次就可以变成一个永久的表了对于这个演示,请在TempDB中运行下面的代码,因为这是我们目前为止所做的所有工作的地方。
====创建用于分割SortPath的HTally表
SELECT TOP 1000 --(4 * 1000 = VARBINARY(4000) in length)
N = ISNULL(CAST(
(ROW_NUMBER() OVER (ORDER BY (SELECT NULL))-1)*4+1
AS INT),0)
INTO dbo.HTally
FROM master.sys.all_columns ac1
CROSS JOIN master.sys.all_columns ac2
;
--===== Add the quintessential PK for performance.(为性能添加典型的PK.)
ALTER TABLE dbo.HTally
ADD CONSTRAINT PK_HTally
PRIMARY KEY CLUSTERED (N) WITH FILLFACTOR = 100
;
接下来,我们不仅要做分割,还要记住节点,我们还要计算Right Bower。不要眨眼。这对于它的实际操作来说是非常快的
WITH cteCountDownlines AS
( --=== Count each occurrence of EmployeeID in the sort path(在排序路径中计算每一个EmployeeID的出现)
SELECT EmployeeID = CAST(SUBSTRING(h.SortPath,t.N,4) AS INT),
NodeCount = COUNT(*) --Includes current node包括当前节点
FROM dbo.Hierarchy h,
dbo.HTally t
WHERE t.N BETWEEN 1 AND DATALENGTH(SortPath)
GROUP BY SUBSTRING(h.SortPath,t.N,4)
) --=== Update the NodeCount and calculate the RightBower 更新NodeCount并计算 RightBower
UPDATE h
SET h.NodeCount = downline.NodeCount,
h.RightBower = (downline.NodeCount - 1) * 2 + LeftBower + 1
FROM dbo.Hierarchy h
JOIN cteCountDownlines downline
ON h.EmployeeID = downline.EmployeeID
;
这是您从一个小的层次结构示例中得到的结果。
SELECT * FROM dbo.Hierarchy ORDER BY LeftBower; --Wow! Another way to sort!
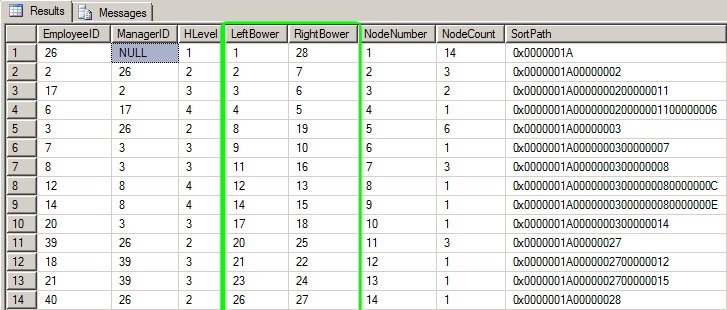
我们这里所拥有的是世界上最好的。 EmployeeID和ManagerID组成了邻接表。SortPath构成了一个"Materialized Hierarchy Path" ,它包含了一些我们需要的有用信息。LeftBower 的和RightBower 的列组成了嵌套的集合。并不是说我们需要它们但是我们有一些很好的“温暖模糊”('warm fuzzy' )的列,比如HLevel,NodeNumber和NodeCount(MLMers需要这个专栏和HLevel来计算支付费用),HLevel实际上可以用来控制GUI中的缩进或报告级别。
现在我们需要做的就是添加一些索引和“Bob's your Uncle”。(易如反掌)
The Final Code
让我们把所有的这些都放在一个很好的,易于使用的存储过程中。在这个过程中,我们将把左和右的Bowers的创建合并到一个单独的代码中,从而完成一个额外的表扫描,使用SQL Server专有的和非常有用的更新版本。
我已经在代码中包含了很多文档。
CREATE PROCEDURE dbo.RebuildNestedSets AS
/****************************************************************************
Purpose:
Rebuilds a "Hierarchy" table that contains the original Adjacency List,
the Nested Sets version of the same hierarchy, and several other useful
columns of data some of which need not be included in the final table.
Usage:
EXEC dbo.RebuildNestedSets
Progammer's Notes:
1. As currently written, the code reads from a table called dbo.Employee.
2. The Employee table must contain well indexed EmployeeID (child) and
ManagerID (parent) columns.
3. The Employee table must be a "well formed" Adjacency List. That is, the EmployeeID column must be unique and there must be a foreign key on the ManagerID column that points to the EmployeeID column. The table must not contain any "cycles" (an EmployeeID in its own upline). The Root Node must have a NULL for ManagerID.
4. The final table, named dbo.Hierarchy, will be created in the same
database as where this stored procedure is present. IT DOES DROP THE
TABLE CALLED DBO.HIERARCHY SO BE CAREFUL THAT IT DOESN'T DROP A TABLE
NEAR AND DEAR TO YOUR HEART.
5. This code currently has no ROLLBACK capabilities so make sure that you
have met all of the requirements (and, perhaps, more) cited in #3 above.
Dependencies:
1. This stored procedure requires that the following special purpose HTally
table be present in the same database from which it runs.
--===== Create the HTally table to be used for splitting SortPath
SELECT TOP 1000 --(4 * 1000 = VARBINARY(4000) in length)
N = ISNULL(CAST(
(ROW_NUMBER() OVER (ORDER BY (SELECT NULL))-1)*4+1
AS INT),0)
INTO dbo.HTally
FROM master.sys.all_columns ac1
CROSS JOIN master.sys.all_columns ac2
;
--===== Add the quintessential PK for performance.
ALTER TABLE dbo.HTally
ADD CONSTRAINT PK_HTally
PRIMARY KEY CLUSTERED (N) WITH FILLFACTOR = 100
;
Revision History:
Rev 00 - Circa 2009 - Jeff Moden
- Initial concept and creation.
Rev 01 - PASS 2010 - Jeff Moden
- Rewritten for presentation at PASS 2010.
Rev 02 - 06 Oct 2012 - Jeff Moden
- Code redacted to include a more efficient, higher performmance
method of splitting the SortPath using a custom HTally Table.
****************************************************************************/
-- ===========================================================================
-- Presets
-- ======================================================= ====================
--===== Suppress the auto-display of rowcounts to prevent from returning
-- false errors if called from a GUI or other application.
SET NOCOUNT ON;
--===== Start a duration timer
DECLARE @StartTime DATETIME,
@Duration CHAR(12);
SELECT @StartTime = GETDATE();
-- ===========================================================================
-- 1. Read ALL the nodes in a given level as indicated by the parent/
-- child relationship in the Adjacency List.
-- 2. As we read the nodes in a given level, mark each node with the
-- current level number.
-- 3. As we read the nodes in a given level, convert the EmployeeID to
-- a Binary(4) and concatenate it with the parents in the previous
-- level's binary string of EmployeeID's. This will build the
-- SortPath.
-- 4. Number the rows according to the Sort Path. This will number the
-- rows in the same order that the push-stack method would number
-- them.
--===========================================================================
--===== Conditionally drop the final table to make reruns easier in SSMS.
IF OBJECT_ID('FK_Hierarchy_Hierarchy') IS NOT NULL
ALTER TABLE dbo.Hierarchy
DROP CONSTRAINT FK_Hierarchy_Hierarchy;
IF OBJECT_ID('dbo.Hierarchy','U') IS NOT NULL
DROP TABLE dbo.Hierarchy;
RAISERROR('Building the initial table and SortPath...',0,1) WITH NOWAIT;
--===== Build the new table on-the-fly including some place holders
WITH cteBuildPath AS
( --=== This is the "anchor" part of the recursive CTE.
-- The only thing it does is load the Root Node.
SELECT anchor.EmployeeID,
anchor.ManagerID,
HLevel = 1,
SortPath = CAST(
CAST(anchor.EmployeeID AS BINARY(4))
AS VARBINARY(4000)) --Up to 1000 levels deep.
FROM dbo.Employee AS anchor
WHERE ManagerID IS NULL --Only the Root Node has a NULL ManagerID
UNION ALL
--==== This is the "recursive" part of the CTE that adds 1 for each level
-- and concatenates each level of EmployeeID's to the SortPath column.
SELECT recur.EmployeeID,
recur.ManagerID,
HLevel = cte.HLevel + 1,
SortPath = CAST( --This does the concatenation to build SortPath
cte.SortPath + CAST(Recur.EmployeeID AS BINARY(4))
AS VARBINARY(4000))
FROM dbo.Employee AS recur WITH (TABLOCK)
INNER JOIN cteBuildPath AS cte
ON cte.EmployeeID = recur.ManagerID
) --=== This final INSERT/SELECT creates the Node # in the same order as a
-- push-stack would. It also creates the final table with some
-- "reserved" columns on the fly. We'll leave the SortPath column in
-- place because we're still going to need it later.
-- The ISNULLs make NOT NULL columns
SELECT EmployeeID = ISNULL(sorted.EmployeeID,0),
sorted.ManagerID,
HLevel = ISNULL(sorted.HLevel,0),
LeftBower = ISNULL(CAST(0 AS INT),0), --Place holder
RightBower = ISNULL(CAST(0 AS INT),0), --Place holder
NodeNumber = ROW_NUMBER() OVER (ORDER BY sorted.SortPath),
NodeCount = ISNULL(CAST(0 AS INT),0), --Place holder
SortPath = ISNULL(sorted.SortPath,sorted.SortPath)
INTO dbo.Hierarchy
FROM cteBuildPath AS sorted
OPTION (MAXRECURSION 100) --Change this IF necessary
;
RAISERROR('There are %u rows in dbo.Hierarchy',0,1,@@ROWCOUNT) WITH NOWAIT;
--===== Display the cumulative duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartTime,114);
RAISERROR('Cumulative Duration = %s',0,1,@Duration) WITH NOWAIT;
--===========================================================================
-- Using the information created in the table above, create the
-- NodeCount column and the LeftBower and RightBower columns to create
-- the Nested Sets hierarchical structure.
--===========================================================================
RAISERROR('Building the Nested Sets...',0,1) WITH NOWAIT;
--===== Declare a working variable to hold the result of the calculation
-- of the LeftBower so that it may be easily used to create the
-- RightBower in a single scan of the final table.
DECLARE @LeftBower INT
;
--===== Create the Nested Sets from the information available in the table
-- and in the following CTE. This uses the proprietary form of UPDATE
-- available in SQL Serrver for extra performance.
WITH cteCountDownlines AS
( --=== Count each occurance of EmployeeID in the sort path
SELECT EmployeeID = CAST(SUBSTRING(h.SortPath,t.N,4) AS INT),
NodeCount = COUNT(*) --Includes current node
FROM dbo.Hierarchy h,
dbo.HTally t
WHERE t.N BETWEEN 1 AND DATALENGTH(SortPath)
GROUP BY SUBSTRING(h.SortPath,t.N,4)
) --=== Update the NodeCount and calculate both Bowers
UPDATE h
SET @LeftBower = LeftBower = 2 * NodeNumber - HLevel,
h.NodeCount = downline.NodeCount,
h.RightBower = (downline.NodeCount - 1) * 2 + @LeftBower + 1
FROM dbo.Hierarchy h
JOIN cteCountDownlines downline
ON h.EmployeeID = downline.EmployeeID
;
RAISERROR('%u rows have been updated to Nested Sets',0,1,@@ROWCOUNT)
WITH NOWAIT;
RAISERROR('If the rowcounts don''t match, there may be orphans.'
,0,1,@@ROWCOUNT)WITH NOWAIT;
--===== Display the cumulative duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartTime,114);
RAISERROR('Cumulative Duration = %s',0,1,@Duration) WITH NOWAIT;
--===========================================================================
-- Prepare the table for high performance reads by adding indexes.
--===========================================================================
RAISERROR('Building the indexes...',0,1) WITH NOWAIT;
--===== Direct support for the Nested Sets
ALTER TABLE dbo.Hierarchy
ADD CONSTRAINT PK_Hierarchy
PRIMARY KEY CLUSTERED (LeftBower, RightBower) WITH FILLFACTOR = 100
;
CREATE UNIQUE INDEX AK_Hierarchy
ON dbo.Hierarchy (EmployeeID) WITH FILLFACTOR = 100
;
ALTER TABLE dbo.Hierarchy
ADD CONSTRAINT FK_Hierarchy_Hierarchy FOREIGN KEY
(ManagerID) REFERENCES dbo.Hierarchy (EmployeeID)
ON UPDATE NO ACTION
ON DELETE NO ACTION
;
--===== Display the cumulative duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartTime,114);
RAISERROR('Cumulative Duration = %s',0,1,@Duration) WITH NOWAIT;
--===========================================================================
-- Exit
--===========================================================================
RAISERROR('===============================================',0,1) WITH NOWAIT;
RAISERROR('RUN COMPLETE',0,1) WITH NOWAIT;
RAISERROR('===============================================',0,1) WITH NOWAIT;
GO
(以上暂时没做格式化(待改))
Performance:
下面是我的膝上型计算机(笔记本)上的代码的性能,在相同的级别上进行了push-stack方法的测试(在括号中包含的push-stack持续时间)。
Duration for 1,000 Nodes = 00:00:00:053 (compared to 00:00:00:870)
Duration for 10,000 Nodes = 00:00:00:323 (compared to 00:01:01:783)
Duration for 100,000 Nodes = 00:00:03:867 (compared 00:49:59:730)
Duration for 1,000,000 Nodes = 00:00:54:283 (compared to something like 2 days!!!)
Note to MLM'ers
MLM层次结构在层次结构中是相当独特的。通常情况下,它们运行的非常深,级别很好。很可能是1000级(var二进制(4000))和本文所使用的HTally表的相关最大值可能不足以满足您的需求。本文中的代码可以轻松地更改为支持2000个级别,对性能的影响很小.如果您需要超过2000个级别(var二进制(8000)),那么我建议您改用VARBINARY(MAX),并使用Itzek ben-gan的级联cte来构建一个cteHTally结构。因为没有一个blob(二进制大对象)数据类型(即使是ben-gan的方法)被连接到一起,所以本文中的代码将花费大约三倍的时间来执行。对于一个millon节点,我的笔记本电脑大约花了3.5分钟。考虑到这样的事情需要花费2天的时间来运行,我认为您可能仍然对这段代码感到满意。如果不这样做,那么您需要提出一种更有效的方法,将SortPath分解为不直接连接到var二进制(MAX)SortPath的方法,这是当前使用HTally表的代码。
Conclusion(结论)
Acknowledgements (后记)
如果没有我从三个个人中获得的一些知识,这篇文章是不可能的,尤其是直接或间接的。
首先,当然,当你说“SQL的层次结构”或“嵌套的集合”时,你必须站起来,向Joe Celko致敬,他在这几年里所做的工作。他逐字地写了这本书。
如果没有Adam Machanic在本文中使用的那些出色的公式,我仍然在寻找一种方法来快速地将一个邻接表转换为嵌套集。我所做的只是用一个统计表对性能进行了调整,并解释了为什么他的公式工作得这么好。请访问我在2009年初访问的同一篇文章。
http://sqlblog.com/blogs/adam_machanic/archive/2006/07/12/swinging-from-tree-to-tree-using-ctes-part-1-adjacency-to-nested-sets.aspx
最后,我不知道是谁写了我在使用数字表格时看到的第一篇文章(我称之为Tally Tables),但感谢你让我的生活变得更简单。
Thank for listening, folks.
p.s. 实际上还有一个“奇迹”我们可以做。虽然嵌套集总是有目的的,但我们可以使嵌套的集合实际上已经过时了,用于计算目的。参见“类Hierarchies on Steroids”的第2部分。
1.”PBAR“ 发音是"ree-bar' 和是一个”Modenism“for "Row-By-Agonizing-Row"逐行的,
Resources:
HierarchyCode.zip