1 什么是solr?
“内事不决问百度,外事不决问谷歌”,相信大家对百度、谷歌等搜索引擎都很熟悉了。网上信息浩瀚万千,而且毫无秩序,所以搜索引擎对用户的作用就体现出来了。
不过,因为商业原因,百度、谷歌等搜索引擎都不是开源的。但是,大家不用担心,有闭源的,当然也有开源的搜索引擎。优秀的开源搜索引擎有Apache Solr、Elastic Search、Index Tank等等,今天我们主要介绍Apache Solr。
Apache Solr是一个高性能,基于Lucene的全文搜索服务器。做为一款搜索引擎,solr不具备爬虫一样采集信息的能力,而是专注于信息的存储和检索。许多朋友误认为solr是数据库,从广义上讲也可认为是数据库,但是它和传统意义上的数据库还是有些区别的。
相信使用过关系型数据库的朋友们一定都做过搜索的功能,比如:有100条记录,我想搜索记录中含有“云计算”字段的记录,可以使用关系型数据库提供的“模糊搜索”的功能。“模糊搜索”能不能满足你的要求呢?如果记录数小,100条、1000条记录当然没问题。但是,如果有100万条、1000万条甚至上亿,那么“模糊搜索”的效果就会大大折扣。而这时,我们就需要用到solr等搜索引擎了。
Solr是基于lucene的倒排索引技术(也叫全文索引,mysql等关系型数据库也有这个概念,但是“术业有专攻”,solr实现的更好),什么是倒排索引,下面我会做具体介绍。
1.1倒排索引
传统意义的数据库,做索引时,都是一个文档id对应一个或者多个内容字段。而倒排索引则是一个内容字段对应多个文档id。什么意思呢?举个例子,假设分别把下面三句话存储到mysql和solr中:
I like sports
I like reading
I like reading books
在mysql中,一个文档id对应一条记录,一条记录中就会有一个或多个内容字段。比如:文档id为1,对应“I like sports”;文档id为2,对应“I like reading”。而在搜索时,就会一条记录一条记录的去检索,比如:我想搜索“books”字段,就会先从文档1找起,文档1没有,文档2也没有,文档3找到了,好,返回数据。相对来说,这样效率有点低。

而在solr中,倒排索引就相反了。它会这样做索引,“I”内容字段,对应文档id为1和2;“like”内容字段,对应文档id为1和2;“sports”内容字段,对应文档id为1;“reading”内容字段,对应文档id为2和3;“books”内容字段,对应文档id为3,等等。这样做的好处在哪呢?

比如:我想搜索“like reading books”这句话,我会把这句话分成三个单词“like”、“reading”、“books”(这在solr中叫分词,后面会详细讲),这时我开始通过内容字段查找文档id。比如我找“like”,文档id为1、2、3,那么这三个文档都可以取出来。然后,我接着找“reading”,这时,文档id为1的没有,只剩下2和3了。最后,我找“books”,只剩下文档id为3的存在了。根据一定的算法,这次搜索结果,会给三个文档打分,从高到低:文档3、文档2、文档1。返还给用户优先级,也是3、2、1。
这样做的好处是:不用按照文档id,一个一个的遍历内容字段了,而是根据多个内容字段,去找交叉最多的文档id(当然了,匹配文档id不止内容字段交叉,还有时间、权重等因素,方便理解,省略了),这样做的话,搜索速度立马上升。
1.2基本操作
Solr是基于Java语言开发的开源搜索引擎,内部嵌入了jetty,提供了web界面,用户可以很方便的在web上操作。当然,考虑到稳定性,我没有使用solr自带的jetty,而是选择了tomcat。
1.2.1 下载solr和tomcat
从Apache官网上下载solr和tomcat并解压到你希望保存的文件夹(我是都保存在“/usr”中的)。然后把“/usr/solr/server/solr-webapp/”下的“webapp”目录,复制到“/usr/tomcat/server/webapps/”中并改名为“solr”。
在“/usr/tomcat/server/webapps/solr/WEB-INF/”中创建“classes”目录,并复制“/usr/solr/server/resources/”下的“log4j.properties”文件到“classes”文件夹中;把“/usr/solr/server/lib/ext/”下的所有jar包复制一份到“/usr/tomcat/server/webapps/lib/”目录中。
1.2.2 配置tomcat的web.xml
该配置文件指定了solr的具体位置,好为tomcat控制solr做准备。文件在“/usr/tomcat/server/webapps/solr/WEB-INF”目录下:

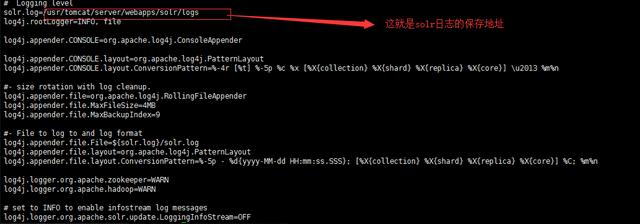
1.2.3 配置tomcat的log4j.properties
该配置文件在“/usr/tomcat/server/webapps/solr/WEB-INF/classes”目录下,指定了solr的日志保存地址:
1.2.4 启动tomcat
因为我是用tomcat做solr的web容器,所以启动tomcat,自然也就会把solr也启动了。启动tomcat的命令,在tomcat的二进制命令目录中。进入“/usr/tomcat/server/bin”,执行“./startup.sh”。Tomcat启动后,在浏览器输入“http://solr服务器ip:8080/solr/index.html#/”后,就会显示下图所示的画面,表示solr启动成功。

1.3中文分词
Solr与mysql一样,查询数据之前,需要先插入数据做成索引。做成索引的方式之前已经有过介绍,下面我开始着重讲述solr的分词部分。
Solr提供了许多的方式用来充当索引的数据源,比如传递xml数据、json数据给solr,mysql等关系型数据库,甚至solr还提供了许多编程语言的扩展给用户,用户可以直接使用php、python等语言的solr扩展给solr服务器传递数据。这部分solr官网比较详细,不再细述。
分词是solr在做索引和查询的时候,非常重要的一个步骤。比如说,“I like reading books”,这句英文,我们就可以分成四个单词(内容字段),“I”、“like”、“reading”、“books”,这很容易,根据空格就能分词了。我们搜索“books”单词,可以把solr中的这句话搜索出来。
但是,solr对于中文分词就不友好了。再举个例子:“我喜欢读书”,这句话怎么分词,我们人类可以很容易区分,把它分成“我”、“喜欢”、“读书”或者“我”、“喜欢读书”;但是,电脑怎么做,它可不懂怎么区分中文。上面这句话,它极有可能分成“我喜”、“欢读”、“书”,或者更离谱的分词都有可能,但是这样做就没意义了。
下面我们就需要引入一款优秀的关于solr的中文分词器了:IKAnalyzer。它也是java开发的,大致原理:导入一定数量的中文词语,然后通过词库的词语分词。比如:我们从一开始,就把“我”、“喜欢”、“读书”这样的中文词语导入到IKAnalyzer中,然后分词的时候,按照一定的逻辑,遇到“喜欢”就分一个词,遇到“读书”就再分一个词等等。每次产生新的词语,就重新导入词库一次。这样,中文分词的问题就大致解决了。
下面简单说下IKAnalyzer的使用:
在“/usr/tomcat/server/webapps/solr/WEB-INF/classes”下创建“IKAnalyzer.cfg.xml”配置文件:

在同目录下创建“dict.txt”和“stopword.dic”文件,“dict.txt”是扩展词库,“stopword.dic”是停用词词库。
从IKAnalyzer网站下载“ik-analyzer-solr-6.3.0.jar”,并把它放到tomcat的“/usr/tomcat/server/webapps/solr/WEB-INF/lib”,重新启动tomcat,就可以使用它了。
2 Solrcloud?
Solrcloud是solr的分布式版本,如果要求不高,我们可以只使用solr就足够了。但是,如果访问量或者信息量比较大的话,可能就需要升级成solrcloud了。
不过,如果solr想做成分布式的solrcloud,需要有一组件来对不同的solr节点进行控制和保证配置文件一致性。在原有的基础上,我们需要借助zookeeper。
Zookeeper是一个开源的分布式协调服务,提供配置维护、域名服务、分布式同步、组服务等功能,非常强大和方便。在solrcloud中通常充当配置维护和分布式同步的功能。整体架构如下图所示:

2.1 zookeeper配置
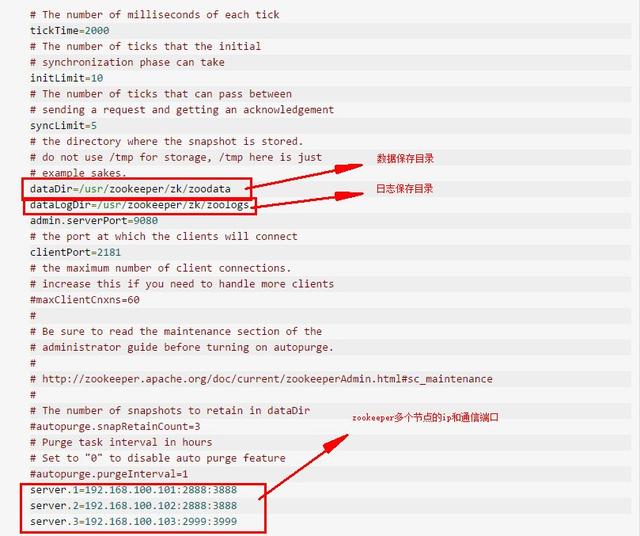
在zookeeper的配置文件目录中,zoo.cfg为其主要配置文件。里面主要配置了zookeeper的数据文件夹、日志文件夹以及全部节点的ip和通信端口。另外需要注意的是:如果你修改好zoo.cfg文件,重启zookeeper之后,zoo.cfg文件会被初始化,之前的zoo.cfg会备份成zoo.cfg.bak。所以,在你关闭zookeeper之后,想要重启zookeeper之前,你需要删除zoo.cfg,并且把zoo.cfg.bak改名为zoo.cfg。
修改好zookeeper的配置文件后,去到zookeeper下的bin目录,启动zookeeper:“./zkServer.sh start”。
2.2 tomcat引入zookeeper相关信息
进入tomcat的bin目录,修改“catalina.sh”文件。在“cygwin=false”前面加上以下代码,这是指定zookeeper的ip和端口号,tomcat开启前,需要知道zookeeper节点的信息,为solrcloud做准备。再次启动成功tomcat,整个solrcloud就算启动成功了。
3总结
由于篇幅有限,对于solr的介绍还只是冰山一角。主要是希望能够起到抛砖引玉的作用,solr的功能点比如:权重设置、分面查询、结果高亮、数据导入、各种编程语言的solr扩展等都没有介绍,以后有机会的话,再与大家一一探讨。