白话“卡方检验”
什么是“卡方检验”?
卡方检验是假设检验的一种,用于分析两个类别变量的相关关系,是一种非参数假设检验,得出的结论无非就是“两个变量相关”或者“两个变量”不相关,所以有的教材上又叫“独立性检验”。如果不是很清楚“假设检验”的朋友们,就要好好翻一下本科阶段《概率论与数理统计》的教材了。
关于假设检验的关键字有:总体、样本、点估计、区间估计、显著性水平、置信区间、统计量、枢轴量、分位点、三大分布、中心极限定理(明确正态分布的重要地位)、抽样分布定理。
如果这些关键字你还比较生疏的话,可以翻翻本科的《概率论与数理统计》教材,在“数理统计”部分,你可以找到它们。
卡方检验在做什么?
卡方检验用于分析两个类别变量的相关关系。
它的流程基本是这样的:我感觉变量 A 和变量 B 存在相关关系,于是我提出假设“变量 A 和变量 B 存在相关关系”,然后我要用严格的数学方法证明“变量 A 和变量 B 存在相关关系”这个假设成立。
- 什么是“类别变量”?
类别变量就是取值为离散值的变量,“性别”就是一个类别变量,它的取值只有“男”和“女”,类似还有”婚否“、”国籍“等。
- 什么是“分析两个类别变量的相关关系”?
以我们熟知的 Kaggle 平台上的泰坦尼克号幸存者预测提供的数据为例,”性别“对于”是否幸存“的关系研究,就属于这方面的内容。研究表明,泰坦尼克号上的乘客秉承”女士优先,照顾弱势群体“的基本原则,因此女性幸存的概率比男性要大,这就说明,”性别“对于”是否幸存“有相关关系,我们后面会使用卡方检验来验证这一事实。
假设检验是什么?
假设检验,顾名思义,就是提出一个假设,然后检验你提出的假设是否正确。假设检验的流程其实是固定的,关键其实在于理解假设检验的设计原则。
这里说一句题外话,“提出假设,然后证明假设”其实我们一点都不陌生,人类探索未知事物、真理用的都是这个思路。聪明的祖先根据经验和直觉,提出一个猜想,然后再用严格的理论去论证这个猜想,例如我们熟知的“万有引力定律”、“地球是圆的”,这些说法刚刚提出来的时候,就只是科学家们的猜想,随后(很可能是很久很久以后),才被证明他们的猜想是正确的、伟大的。只不过在统计学中,“提出猜想”叫“提出假设”,“证明猜想”叫“检验”。
假设什么?
那么我们假设什么呢?这里就要引入“原假设”和“备择假设”的概念了。“原假设”是“备择假设”的对立面。
下面这个原则很重要:
备择假设通常是研究者想收集证据予以支持的假设;
原假设是研究者想收集证据予以推翻的假设。
重要的事情,我再写两遍:如果你想通过种种论证,证明一件事情,就要把这件事情写成“备择假设”。备择假设通常用于表达研究者自己倾向于支持的看法(这很主观),然后就是想办法收集证据拒绝原假设,以支持备择假设。
特别要说明的一点是:如果你不遵守这个“原假设”和“备择假设”设计的基本原则,你很可能会得到相反的结论。
假设检验很像司法界对于一个事实的认定,本着“疑罪从无”的原则,如果你要说明一个人有罪,你必须提供充足的证据,否则被告人的罪名就不能成立,这个说法叫“没有充分的证据证明被告有罪”。
因此,如果我们最后的结论是“原假设”成立,我们一般不这么说,即我们不说“原假设”成立,我们不说“原假设”是真的。我们说不能拒绝“原假设”,或者说没有充分的证据拒绝“原假设”,或者说没有充分的证据证明“备择假设”成立。
卡方检验的“原假设”与“备择假设”
因为我们做假设检验一定是觉得两个类别变量有关系,才去做检验。再想想那个“疑罪从无”原则,我们是觉得一个人有罪,才去举证。因此卡方检验的“原假设”一定是假设独立,“备择假设”一定是假设相关,即:
原假设:类别变量 与类别变量 独立;
备择假设:类别变量 与类别变量 不独立 。
这一点是极其重要且明确的,请你一定记住它,在统计软件中都是这样设定的。
原假设是两个类别变量独立。
原假设是两个类别变量独立。
原假设是两个类别变量独立。
如何检验?
做“检验”这件事情,就很像我们以前做的“反证法”,我们假定要证明的结论的对立面成立,然后推出矛盾,即说明了我们的假设是错误的,即原命题成立。请看下面这个例子:
请你证明:这个餐厅的菜很难吃。
证明:假设这个餐厅的菜很好吃,那么周末的晚上生意一定很好,然而实际观察下来,顾客流量和平时一样,推出矛盾,所以假设不成立,即这个餐厅的菜很难吃。
用假设检验的思路,在这个例子中:
原假设:这个餐厅的菜很好吃;
备择假设:这个餐厅的菜很难吃。
我们把倾向于要证明的结论设置为“备择假设”,而推理是基于“原假设”成立进行的,推理得出矛盾,说明“原假设”错误,从错误的起点推出了错误的结论,因此“原假设”不成立,这就是假设检验里面说的“拒绝原假设”。
因此,检验其实很简单,就是一个是非论证的过程,是单选题,只有两个选项,选择其一。
假设检验如何论证?
假设检验的论证流程其实是固定的。论证依据的事实是“小概率事件在一次试验中几乎不可能发生”,通常,我们得到的矛盾就在于:通过计算统计量,发现通过一次试验得到这个统计量是一个“小概率事件”,“小概率事件”在一次试验中,居然发生了,我们就认为这是很“诡异”的,一定是之前的某个环节出了问题,即“原假设”不成立,于是拒绝“原假设”,即证明了“备择假设”成立。
为什么叫“卡方检验”?
“卡方检验”即利用“卡方分布”去做“假设检验”。
什么是“卡方分布”?
“卡方分布”(也写作 “分布”)是统计学领域的三大分布之一,另外两个分布是“ 分布”与“ 分布”,这些分布都是由正态分布推导出来的,可以认为它们是我们熟知的分布,因为它们可以取哪些值,以及取这些值的概率都是完全弄清楚了的。
注:忘记了三大分布的朋友们,请一定要翻翻自己本科的教材,看看这些分布用来做什么?为什么出现在“数理统计”中,理解使用这些分布是为了从样本中估计总体的信息。
统计学的研究任务是通过样本研究总体,因为我们无法把所有的总体都做一次测试,一般可行的做法就是从总体中抽取一部分数据,根据对这一部分数据的研究,推测总体的一些性质。
而“三大分布”就是我们研究样本的时候选取的参照物。一般我们研究的思路是这样的:如果经过分析,得出待研究的样本符合这些我们已知的分布之一,因为三大分布是被我们的统计学家完全研究透了的,可以认为是无比正确的,就可以通过查表得到这些分布的信息,进而得到样本的一些性质,帮助我们决策。
这里举一个例子,比如你是一个面试官,你手上掌握着“北京”、“上海”、“广州”三个省市的人才信息库,来了一个面试者,从简历中得知这个人来自“北京”,那么我们就可以直接从“北京”市的人才信息库中查阅到他的详细履历,掌握到他更全面的信息。
上面提到的“北京”、“上海”、“广州” 这 3 个城市的人才信息库,就相当于统计学中的三大分布,你不用记住它,你不用随身携带它,但是你可以查阅它,它会告诉你你想知道的信息。
做假设检验的时候,我们也是类似的思路,我们需要利用总体的样本构造出合适的统计量(或枢轴量),并使其服从或近似地服从已知的确定分布,这样我们就可以查阅这些确定分布的相关信息,得到待研究样本所反映出来的总体的一些性质。
上面说到了“统计量”和“枢轴量”,下面简单谈一谈。
- 什么是“统计量”?
统计量:不含总体分布未知参数的函数称为样本的统计量。统计量经常作为一个样本的代表,例如平均数、众数、最大值、最小值,统计量由多个数映射成一个数。 - 什么是“枢轴量”?
枢轴量:仅含有一个未知参数,并且分布已知的样本的函数,称为枢轴量。引入枢轴量的作用,其实就是为了解方程,或者说解不等式,这一部分非常重要的理论基础是“抽样分布定理”。
如果忘记了的朋友们一定要翻翻以前的教程,“抽样分布定理”是非常重要的。根据抽样分布定理,我们经常是这样用的:样本的某个含有未知参数的函数符合某个已知分布,已知分布可以查表,因此未知参数的性质就知道了。求“置信区间”与做“假设检验”通常就是这样的思路。
卡方检验的统计量
说明: 是观测频数(实际值), 是期望频数(可以认为是理论值),期望频数的计算公式我们马上会介绍到。这个统计量服从自由度为 的 分布, 为行数, 为列数。
如何理解卡方检验的统计量?
- 我们先看每一个加法因子的分子,是 ,它表示了观察频数和理论频数的“距离”(或者称作“差距”),如果差距越小,卡方统计量的值就越小,则表示观察频数和理论频数越接近;
- 分母是理论频数,表示标准化,想想卡方分布的定义, 个标准正态分布的平方和,所以这个统计量符合卡方分布(我这个说法只是为了帮助理解统计量的形式,不是严格论证,严格的数学证明请参考相关教材),我们就可以查阅卡方分布表,看看这个卡方分布取到这个统计量的概率有多大,如果这个概率大,表明观察频数和理论频数差别不大,两个类别变量独立,如果这个概率小,表示观察到这个频数的概率很小,即观察频数和理论频数差别显著,拒绝原假设,两个类别变量相关。
下面举个例子,说明卡方检验的基本流程。
例:研究类别变量“青少年行为”与类别变量“家庭状况”的相关关系
以下例子选自中国人民大学龙永红主编《概率论与数理统计》(第三版)P190 “独立性检验”一节例 5.32。
研究青少年行为与家庭状况的关系,调查结果如下:
| 青少年行为\家庭状况 | 离异家庭 | 和睦家庭 | 合计 |
|---|---|---|---|
| 犯罪 | |||
| 未犯罪 | |||
| 合计 |
分析:“青少年行为”是离散型变量,有“犯罪”与“未犯罪”两个取值;“家庭状况”是也离散型变量,有“离异家庭”与“和睦家庭”两个取值,从直觉上,我们认为它们是相关的。因此
上面这张表,我们可以称之为观察频数表,观察依据事实。下面我们会计算一张“理论频数表”,理论依据假设。
- 第 1 步:建立统计假设。
原假设:“青少年行为”与“家庭状况”独立。
备择假设:“青少年行为”与“家庭状况”不独立。
- 第 2 步:计算期望频数与检验统计量。
要计算出检验统计量,关键是计算出期望频数。我们之前说到了,假设检验是基于原假设进行论证,因此我们的期望频数应该是基于【“青少年行为”与“家庭状况”独立】得到的,即:两个类别的交叉项的概率可以根据独立事件的概率乘法公式 得到。具体是这样做的,上面那张表中,把交叉项隐藏起来:
- 一行一行看,这 个青少年里,,;
- 一列一列看,这 个青少年里,,;
在【“青少年行为”与“家庭状况”独立】这个假设下有:
我们要计算期望频数,就把上面这 个概率分别乘以样本总数 就可以了,于是我们得到理论频数表:
| 青少年行为\家庭状况 | 离异家庭 | 和睦家庭 |
|---|---|---|
| 犯罪 | ||
| 未犯罪 |
下面我们就套公式 了,将每个单元格的 加起来,就可以得到 统计量:
上面说服从自由度为 的 分布, 为行数, 为列数,即服从 的 分布,接下来,我们就要看得到这个统计量的概率有多大:
from scipy import stats
import seaborn as sns
import matplotlib.pyplot as plt
samples = stats.chi2.rvs(size=10000, df=1)
sns.distplot(samples)
plt.title('$\chi^2$,df=1')
plt.show()
得到图像如下:
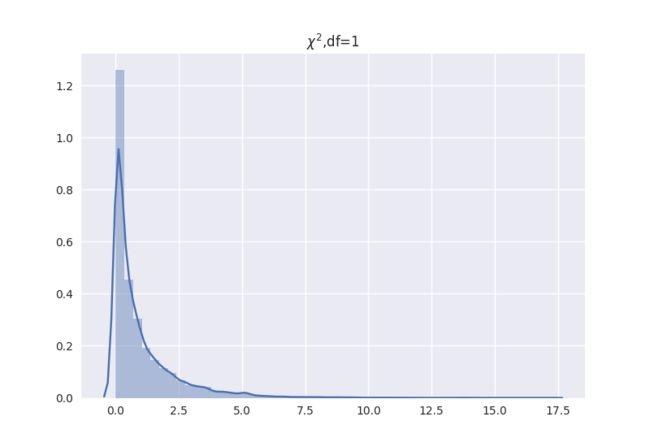
可以看到, 都不在能图像显示到的范围之内,说明这个概率很低。下面我们查表或者使用 Python 查一下,这个概率是多少:
from scipy import stats
stats.chi2.pdf(152.15, df=1)
2.956796099836173e-35
得到:,确实是一个几乎为 的数。这说明了什么呢?
说明了,在我们的假设【“青少年行为”与“家庭状况”独立】下,得到这组观测数据的概率很低很低,基于小概率事件在一次试验中几乎不会发生,但它却发生了,就证明了我们的“原假设”是不正确的,即有充分证据决绝“原假设”。(这一部分有点绕,其实很简单,多看几遍就非常清楚了。)
其实到这里,我们对卡方检验就已经介绍完了,是不是觉得很简单。但是在实际操作的过程中,我们还会引入 值,很多统计软件也会帮我们计算出 值,这个 值是个什么鬼呢?下面先给出我的结论:
什么是 值?
为什么提出了 值?检验统计量有什么不好?
说明:以下我根据对 值的理解自己总结的,是人话,但不一定准确。
得到“检验统计量”有个缺点,就是它是一个很“死”的数字,我们看到 ,我们只能直观感觉它很大,因为如果观察频数与理论频数大约相等,这个值应该很小,但不能量化这个值有多大。这只是统计量服从某个自由度的卡方分布的情况。
那么问题来了,如果统计量服从其它分布呢?统计量这个干巴巴的数字,你怎么知道这个这个分布取到这个统计量的概率有多大?因此还差一步,我们还必须查表。所以得到 值的过程就是帮你查表了, 值是一个概率值,它介于 和 之间, 值是当前分布取到这个统计量的概率到当前分布极端值(指的是概率很小的极端值)这个区间的累计概率之和,即取到这个值,到比这个值更“差”的概率之和,如果 值很大,说明统计量取当前值的概率在一个正常的范围(一般是认为设定成 ),如果 值很小,说明这个统计量取当前值的概率也非常小。
特别说明:对于连续型随机变量来说,取到某个值的概率其实是 ,因此上面才用到了对于区间取概率之和。
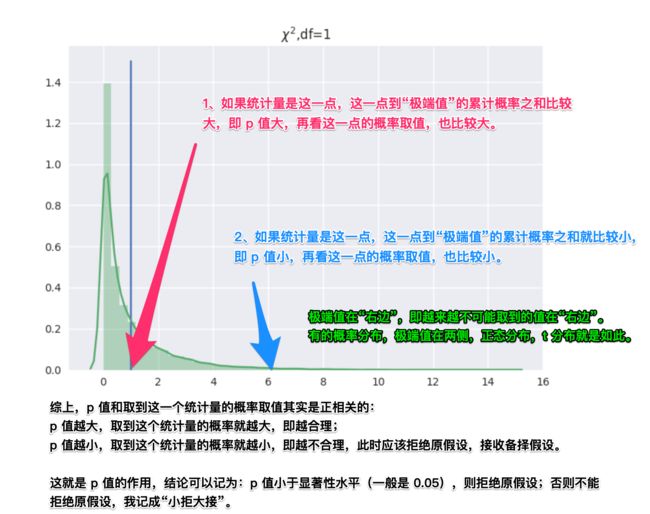
说明:上面所说的累积概率之和如果很小,小于一个临界值,这个临界值我们称之为“显著性水平”,用 表示,一般取 。多说一句,这个显著性水平其实是我们在原假设成立的情况下,拒绝原假设的概率,即犯第一类错误的概率,具体就不展开了,请参考相关《概率论与数理统计》教材。
所以我们总结一下:
1、 值统一了假设检验的比较标准,把计算统计量的概率大小统一变成计算 值,如果这个 值小于一个预先设定好的很小的数,则拒绝原假设,如果 值大于这个预先设置好的很小的数,则说明没有充分证据拒绝原假设;
2、使用 值进行假设检验的时候,会更便利。因此,使用 值进行假设检验的评判标准就只要一个,就是记住这句话“小拒大接”,即比 小,就拒绝“原假设”,比 大,结论是“没有理由拒绝原假设”。
值在不同的检验问题中,计算的方式会有一些不同,区别就在于概率极端值是在一侧还是在两侧。在这里,我们就以卡方检验为例,如果我们计算出来的统计量的值为 ,那么看图:
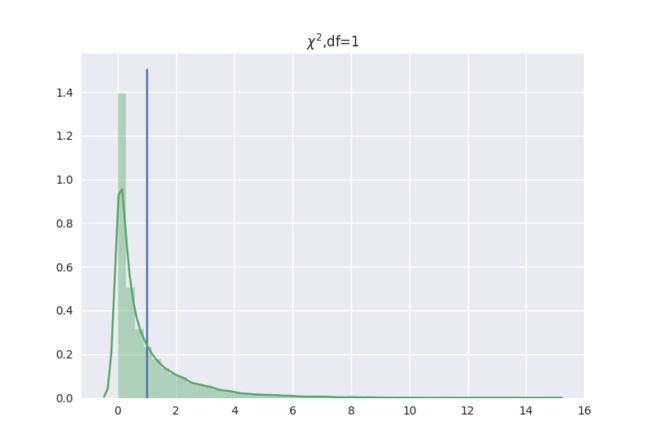
这个时候,统计量取 的概率就很高了,从图中可以看出大于 。我们作如下分析:
- 分布长尾在右边,是个右偏分布,在 附近的概率是非常高的,我们要找一个临界值,如果统计量取到这个临界值,以及这个临界值的右边,我们认为这样的事情发生的概率是很低的,这里就要借助累计概率和分位点的概念;
(说明:累计积分和分位点的概念都是十分重要的,在这里就不赘述了,读者可以查阅相关统计学的教材。)
- 我们认为,在 分布,如果一个点到右边无穷的累计积分小于“显著性水平”,我们就认为这个点以及右边所有的点的取值,都是小概率事件。
于是,对于卡方检验而言,得到的统计量,我们可以计算这个从统计量到正无穷的积分,如果这个积分值小于“显著性水平”,即认为这个统计量的概率一定在“显著性水平”所确定的临界点的右边,即它是比“小概率事件”发生的概率还小的“小概率事件”。
下面,我们自己写一个函数来实现卡方检验相关的计算,实现和 scipy 软件包提供的卡方检验同样的效果。
from scipy import stats
from scipy.stats import chi2_contingency
def custom_chi2_contingency(observed):
"""
自己编写的卡方检验的函数,返回
"""
# 每一行求和
row = observed.sum(axis=1)
# 每一列求和
col = observed.sum(axis=0)
# 总数求和
all_sum = observed.sum()
# meshgrid 生成网格
x1, x2 = np.meshgrid(col, row)
# 期望频数
expected_count = x1 * x2 / all_sum
# 统计量,即卡方值
chi2 = ((observed - expected_count)**2 / expected_count).sum()
# 自由度
df = (len(row) - 1) * (len(col) - 1)
# 计算 p 值,这里用到了卡方分布的概率积累函数,
# 因为这个 cdf 是计算从左边到这点的累计积分,因此用 1 减它
p = 1 - stats.chi2.cdf(chi2, df=df)
return chi2, p, df, expected_count
下面验证我们编写的卡方检验函数的正确性:
obs = np.array([[178, 272], [38, 502]])
result1 = custom_chi2_contingency(obs)
result2 = chi2_contingency(obs)
print('自定义卡方检验的函数返回:')
print(result1)
print()
print('scipy 提供的卡方检验返回:')
print(result2)
自定义卡方检验的函数返回:
(152.16271892047084, 0.0, 1, array([[ 98.18181818, 351.81818182],
[117.81818182, 422.18181818]]))
scipy 提供的卡方检验返回:
(150.2623232486362, 1.5192261812214016e-34, 1, array([[ 98.18181818, 351.81818182],
[117.81818182, 422.18181818]]))
显示:
自定义卡方检验的函数返回:
(152.16271892047084, 0.0, 1, array([[ 98.18181818, 351.81818182],
[117.81818182, 422.18181818]]))
scipy 提供的卡方检验返回:
(150.2623232486362, 1.5192261812214016e-34, 1, array([[ 98.18181818, 351.81818182],
[117.81818182, 422.18181818]]))
参考资料
1、结合日常生活的例子,了解什么是卡方检验
https://www.jianshu.com/p/807b2c2bfd9b
2、假设检验之八:p值是什么:
https://zhuanlan.zhihu.com/p/26068572