都是基于哈希表提供键值映射的数据结构
Hashtable是线程安全的,效率比较低,被废弃的其他原因可能是因为Hashtable没有遵循驼峰命名法吧 -----笑哭
继承的父类不同
HashTable是继承自Dictionary(已被废弃)
HashMap是继承自AbstractMap
不过它们都实现了同时实现了Map、Cloneable(可复制)、Serializable(可序列化)这三个接口
对Null Key 和 Null Value 的支持不同
Hashtable既不支持Null key也不支持Null value,当key为Null时,调用put() 方法,就会抛出空指针异常。因为拿一个Null值去调用方法了。

当value为null值时,Hashtable对其做了限制,也会抛出空指针异常。

HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断
线程安全性不同
Hashtable是线程安全的,它的每个方法中都加入了Synchronize方法。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步
HashMap不是线程安全的,在多线程并发的环境下,可能会产生死锁等问题。使用HashMap时就必须要自己增加同步处理
虽然HashMap不是线程安全的,但是它的效率会比Hashtable要好很多。这样设计是合理的。在我们的日常使用当中,大部分时间是单线程操作的。HashMap把这部分操作解放出来了。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定
遍历方式的内部实现上不同
Hashtable、HashMap都使用了Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式
HashMap的Iterator是fail-fast迭代器。当有其它线程改变了HashMap的结构(增加,删除,修改元素),将会抛出ConcurrentModificationException。不过,通过Iterator的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM
JDK8之前的版本,Hashtable是没有fast-fail机制的。在JDK8及以后的版本中 ,HashTable也是使用fast-fail
初始容量大小和每次扩充容量大小的不同
Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1
HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍
Hashtable会尽量使用素数、奇数。而HashMap则总是使用2的幂作为哈希表的大小。之所以会有这样的不同,是因为Hashtable和HashMap设计时的侧重点不同。Hashtable的侧重点是哈希的结果更加均匀,使得哈希冲突减少。当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀。
HashMap则更加关注hash的计算效率问题。在取模计算时,如果模数是2的幂,那么我们可以直接使用位运算来得到结果,效率要大大高于做除法。HashMap为了加快hash的速度,将哈希表的大小固定为了2的幂。当然这引入了哈希分布不均匀的问题,所以HashMap为解决这问题,又对hash算法做了一些改动。这从而导致了Hashtable和HashMap的计算hash值的方法不同
计算hash值的方法不同
为了得到元素的位置,首先需要根据元素的key计算出一个hash值,然后再用这个hash值来计算得到最终的存储位置
Hashtable直接使用对象的hashCode。hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。然后再使用除留余数法来获得最终的位置。Hashtable在计算元素的位置时需要进行一次除法运算,而除法运算是比较耗时的
HashMap为了提高计算效率,将哈希表的大小固定为了2的幂,这样在取模预算时,不需要做除法,只需要做位运算。位运算比除法的效率要高很多。为了解决这个问题,HashMap重新根据hashcode计算hash值后,又对hash值做了一些运算来打散数据。使得取得的位置更加分散,从而减少了hash冲突。当然了,为了高效,HashMap只做了一些简单的位处理(将得到的hash值与table的长度做位运算)。从而不至于把使用2 的幂次方带来的效率提升给抵消掉
HashMap的工作原理
概述:HashMap是基于hashing的原理,使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当调用put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于在Node数组table中找到bucket位置来储存Entry对象。当put新的储存对象的键值key的hashCode与数组中已存在对象键值的hashCode相同(碰撞发生),如果两个hashCode相等(equals),则判断是否覆盖(onlyIfAbsent参数值或已存在对象的value值为null),否则创建并存储新的储存对象,已存在存储对象的next指针将指向新的存储对象,形成拉链存储结构(JDK8还多了一重红黑树型结构的判断)
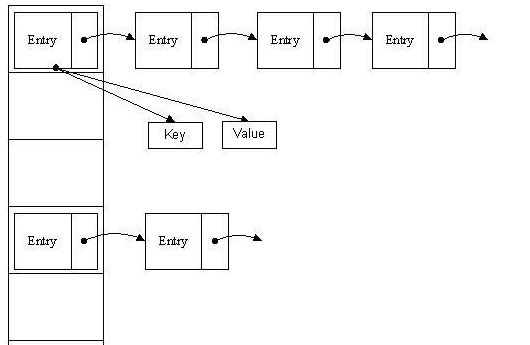
上图就是HashMap中hash表的结构示意图,左侧为储存entry的Node数组table,当发生碰撞以后,bucket相同但键值不相等的的entry就会以单向链表的形式链接起来
先揪出这几个重要的属性变量(源码基于JDK1.8)
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold; // 下一次resize的时候扩容数组的长度
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor; // 负载因子大小 即数组容量达到负载因子大小时resize扩容
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node[] table; // 储存键值对象的数组
通常情况下使用默认的构造方法创建HashMap
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
默认的负载因子(DEFAULT_LOAD_FACTOR)的值为 0.75,这是时间和空间成本上一种折中,增大负载因子可以减少 Hash 表(Entry 数组table)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*
* 此HashMap经过结构修改的次数结构修改是指更改HashMap中映射数量或以其他方式修改其
* 内部结构(例如,重新散列)的修改。该字段用于使HashMap的Collection-views上的迭代器
* 失败 翻译直译 - -!
*/
transient int modCount;
初始化过程中并没有初始化table数组的初始长度
初始化之后就是往里面塞东西了,调用put(K key, V value)方法
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
//这里进行了table的初始化操作
if ((tab = table) == null || (n = tab.length) == 0)
//当table == null || tab.length == 0 的时候进行resize()扩容
n = (tab = resize()).length;
//按照HashMap减少冲突的规则查找当前储存对象对应的bucket位置
if ((p = tab[i = (n - 1) & hash]) == null)
//如果当前待储存对象所对应的bucket位置为null,放心大胆的直接把对象存进去
tab[i] = newNode(hash, key, value, null);
else {
//如果到了这里,恭喜你,产生碰撞了
//即表示通过键值hashCode处理后得到的bucket有重复
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果碰撞的两个key相等 这里需要对hashCode和equals有清晰的认识
//将已存在的键值对象赋值给新对象是用于后面判断映射已存在
e = p;
else if (p instanceof TreeNode)
//碰撞键值的key不相等
//红黑树型结构则直接将新插入的结点挂在树上qwq
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//碰撞键值的key不相等
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//将已存在的对象指向新存储对象
p.next = newNode(hash, key, value, null);
//如果表太小,调整大小,替换给定散列的索引处的bin中的所有链接节点
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//找到键值相等的已储存对象则退出
break;
//移动指针,直到找到最后一个已存储的对象
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
//如果已存在对象的value值为空或者onlyIfAbsent = true则覆盖旧的value值
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//没有碰撞 初始化table或者直接往数组插入数据后
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
get(Object key)方法捶打一下
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
*
A return value of {@code null} does not necessarily
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
//根据hashCode提取对应的bucket位置
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//bucket对应的不是单一存储对象,而是链表
//由此看见,当bucket对应单一存储对象时,效率是最高的
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
感谢:
Java中的HashMap
HashMap 与HashTable的区别
HashMap与hashCode以及equals
HashMap实现原理分析
HashMap工作原理
HashMap的实现原理 HashMap底层实现,hashCode如何对应bucket?