一、线性分类Linear Classification
线性分类器中的score function完成下面的函数映射:
具体来讲,就是将D维的图像x,映射到K维的分类标签。以cifar-10数据集为例,图像大小为32 x 32像素,加上RGB三通道,x的维度就是32 x 32 x 3 = 3072。该数据集有10个分类标签,则K = 10。
具体的计算公式如下:

其中:
xi
代表图片样本集中的某个图片样本,这里将图片的每个像素值拉长,形成了一个 [D, 1] 的列向量。对于cifar-10数据集的图片,其大小为32 x 32像素,加上RGB三通道,xi的维度是3072, xi就是[3072, 1]的列向量。这里对于如何拉长形成列向量的规则并没有特定要求,只要每个图片都按相同的方式生成其向量即可W
W是一个 [K, D]的矩阵,其中每一行代表一个分类标签的分类器。对于cifar-10,W就是 [10, 3072],共10个分类器,分别对应于cat、dog、ship等类别标签。b
b是 [K, 1]的偏置,cifar-10中就是[10, 1]
最终运用上面的公式,可以计算出一个图片对应K个类别的各自得分。
而要训练的,则是通过training样本确定最优的W和b的值
二、线性分类的两种解释
W和b的值大致可以认为其对图片中各个位置上的点的颜色的偏好,例如对于ship类别,一些位置的点偏好蓝色(可能由于该类别图片样本中有许多蓝色的海水)。
其中一种对线性分类器的解释是,可以将图片看做高维空间中的点,那么每一个类别的分数就是该空间中的一个线性函数。
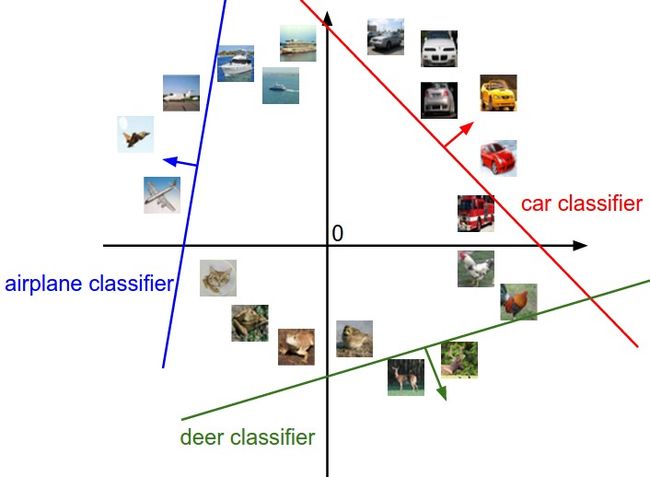
线性函数上的点其在该类别的得分为0,箭头方向一面的点则分值为正,反方向的点则分数为负。
而另一种理解是,可以将线性分类看做某种模板匹配。W中的每一行对应于类别中的某一类的模板。

从上图可以看出,这种模板匹配的能力很弱,例如,对于car类别,它只能比较好的识别红色的车辆,可能是由于cifar-10数据集中红色车辆比较多。后面可以看到,如果应用神经网络进行分类,网络中的隐藏层可以识别不同颜色的车辆,然后在网络的高层来进行更进一步的评分。
三、损失函数 Multiclass Support Vector Machine
课程给出了两种Loss Function,Multiclass Support Vector Machine和Softmax。先看看Multiclass SVM。
Multiclass SVM
Multiclass SVM希望图片的正确分类的得分score高于不正确分类的得分一个固定的间隔值,这个值称作margin。
具体来说,如果第i个样本根据score function得到的分类得分向量为s,其中每一类的得分分量记为sj(即第j类的得分),那么第 i 个样本的loss function定义如下

注意,其中求和项不包括其正确分类的那一项,delta就是margin值。
举个例子,如果对第 i 个样本的得分为 s = [13, -7, 10],并设置delta = 10,那么运用上面的公式就有
另外,对于公式,如果以 W 矩阵的第 j 行 wj 代入 sj,syi也以类似方式代入可以得到如下的等效公式

最后,将每个样本的Loss值 Li求和,并取平均,则可以得到线性分类器对整个样本的Loss值。
max(0, -)被称作 hinge loss,这是常用的形式。有时也会使用其平方的形式 max(0, -)2,被称作squred hinge loss SVM(或叫做 L2 - SVM)
Regularization
但是,直接应用上面的Loss Function具有一些不合适的地方,简单来说,就是对于同样的Loss值,W的取值并不唯一,这时需要引入正则化 regularization 来约束W。
具体的做法是,给loss function增加一个regularization惩罚项R(W),常用的有L2 regularization。如下所示

加这项加入loss function后,即变为如下形式

或者其等效形式

其中的lamda是一个hyper-parameter,通常可以用cross validation的方式来决定其取值。
Regularization的意义
L2 regulariztion带来许多好处。其中最明显的一个是,对大的weights的惩罚可以提高模型的泛化承担,因为没有输入可以仅靠其自己就对score产生很大的作用。
举例来说,如果有一个输入x = [1, 1, 1, 1],并且有两种不同的weight,w1 = [1, 0, 0, 0]和w2 = [0.25, 0.25, 0.25, 0.25]。可以知道w1x = w2x = 1,但是根据L2 regulariztion项,其各自的惩罚值为1和0.25,最终选取较小的loss值会使得算法选择w2作为weight值。最终分类器会更多的考虑值比较小的输入维度,而不是被一些大值的维度影响。后面的课程可以看到,应用了regulariztion后,分类器的泛化承担和防止过拟合overfitting会更好。
除了L2,还有其他的regulariztion方法,例如L1、Elastic net(L1 + L2)、Max norm、Dropout等等。
Multiclass SVM的代码实现(未应用regularization)
这里给出了两个版本的对Li计算的实现,一个是向量化的方式,一个是半向量化的方式,如下
def L_i(x, y, W):
"""
unvectorized version. Compute the multiclass svm loss for a single example (x,y)
- x is a column vector representing an image (e.g. 3073 x 1 in CIFAR-10)
with an appended bias dimension in the 3073-rd position (i.e. bias trick)
- y is an integer giving index of correct class (e.g. between 0 and 9 in CIFAR-10)
- W is the weight matrix (e.g. 10 x 3073 in CIFAR-10)
"""
delta = 1.0 # see notes about delta later in this section
scores = W.dot(x) # scores becomes of size 10 x 1, the scores for each class
correct_class_score = scores[y]
D = W.shape[0] # number of classes, e.g. 10
loss_i = 0.0
for j in xrange(D): # iterate over all wrong classes
if j == y:
# skip for the true class to only loop over incorrect classes
continue
# accumulate loss for the i-th example
loss_i += max(0, scores[j] - correct_class_score + delta)
return loss_i
def L_i_vectorized(x, y, W):
"""
A faster half-vectorized implementation. half-vectorized
refers to the fact that for a single example the implementation contains
no for loops, but there is still one loop over the examples (outside this function)
"""
delta = 1.0
scores = W.dot(x)
# compute the margins for all classes in one vector operation
margins = np.maximum(0, scores - scores[y] + delta)
# on y-th position scores[y] - scores[y] canceled and gave delta. We want
# to ignore the y-th position and only consider margin on max wrong class
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
def L(X, y, W):
"""
fully-vectorized implementation :
- X holds all the training examples as columns (e.g. 3073 x 50,000 in CIFAR-10)
- y is array of integers specifying correct class (e.g. 50,000-D array)
- W are weights (e.g. 10 x 3073)
"""
# evaluate loss over all examples in X without using any for loops
# left as exercise to reader in the assignment
实际应用中的考虑
上面的hyper paramter有两个,delta和lamda。如何决定这连个超参数的值呢?
看起来delta和lamda都会对loss function产生影响,然而实际情况时对所以的情况,都可以把delta的值安全的设置为1.0。原因是,score的值会受到W的值按比例放大或缩小的影响,换句话说不同score之间的差值也会相应的按比例变化,这时候delta取什么值似乎并不重要,只要它也按类似的比例变化即可。
而W的可变范围则是由regulariztion中的lamda来约束的,所以,最终我们只需要确定lamda的值即可。
题外话
- Binary SVM其实是Multiclass SVM的特例
- Multiclass SVM的形式还有其他几种,例如One-Vs-All (OVA) SVM、All-vs-All (AVA) 、Structured SVM。
四、Softmax分类器
另一种损失函数是以Softmax + cross entropy来定义的。具体的公式如下,图中的两个公式等效

上面的公式中包含了两层含义。
- softmax函数计算
公式中log函数内部的部分叫做softmax函数,将其独立写成函数形式如下。
其中对于我们的分类器场景,上面公式中的z对应于各个分类的得分函数值,zj就是对应于第j个分类的得分
- cross-entropy计算
损失函数中log和负号部分是应用了cross entropy交叉熵计算的结果。交叉熵的公式如下

它反映了真实的概率分布p和估计概率分布q之间的差异。而对于分类应用,n个分类的真实概率分布中,只有一个分类为真,其概率为1,其余真实概率为0。而我们的估计概率q就是上面的softmax函数应用到各个分类的分的情况,将两者代入交叉熵公式就得到了本节最上面图中的结果(真实概率为0的分类与其对应的softmax部分相乘就变成了0,被略去了)。从这里,也可以认为softmax的具有一定的概率上的意义。
在实际应用中,计算softmax的时候,由于分母的值通过指数计算求和得到,常常由于其值太大,导致除法结果在数值上不稳定,因此需要对其进行normlization处理。具体方式如下
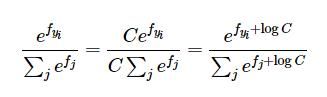
从上图看出,对分子分母乘以相同的C,并将其代入指数中,相当于对每个分类的得分值进行了改变。
常用的做法是让logC = - max(f),即让logC选择为负的得分值中的最大值,相等于将所有的得分减去了其中的最大值,得分的最大值变为了0。