From Import AI
作为自然语言处理领域相关,这期最关心的还是 TCN 在序列建模上的应用。
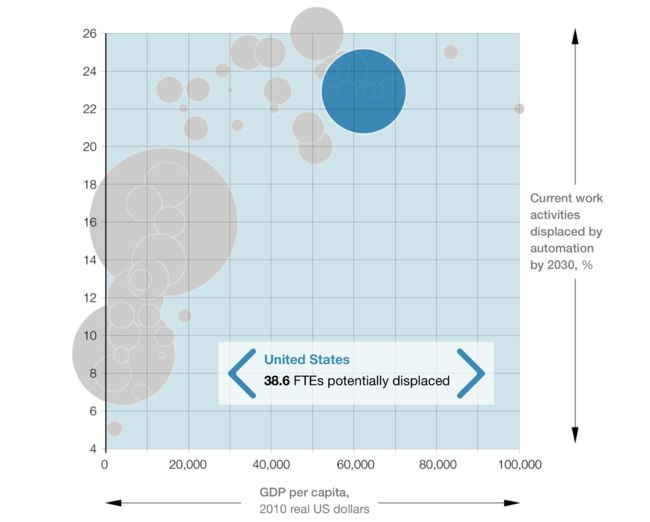
自动化与经济:很复杂:
... AI技术来自何处,为什么对印度来说自动化具有挑战性,等等...
在播客中,麦肯锡全球研究院 McKinsey Global Institute 的三名员工讨论了自动化如何影响中国,欧洲和印度。一些特别有趣的观点如下:
- 由于中国劳动力市场已经达到顶峰,而且与其他发达经济体的人口基数相似,中国有动力使自己的行业实现自动化,从而提高劳动生产率。
- AI技术的供应似乎来自美国和中国,而欧洲则滞后。
- “工作重组这个巨大的影响,采用这种技术的公司将不得不重新组织他们提供的工作类型,这么做会多么困难?公司将不得不重组他们的工作方式,以确保他们得到使用这种技术的成果。”
- 印度可能会挣扎,因为它将数十亿人转移到农业工作岗位上。 “我们必须在这样一个时代进行这种转变:由于自动化在多种类型的制造业中扮演着更重要的角色,因此创造就业机会将变得更具挑战性。”
更多:自动化将如何影响全球经济(麦肯锡全球研究所)。
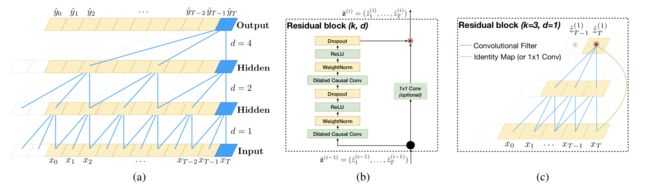
可能比你想的要简单:研究人员表示卷积网络在很多方面击败循环网络:
...简化技术的不断发展...
卡内基梅隆大学和英特尔实验室的研究人员已经严格地比较了CNN(通过时序卷积网络(Temporal Convolutional Network TCN)架构,由 Wavenet 和最近的多项研究启发)与序列模型架构比如RNN的表现(包括LSTM和GRU)。
TCNs序列建模的优点如下:
- 易并行化,而不是顺序处理;
- 灵活可变的接受域;
- 稳定的梯度;
- 对训练的内存要求低;
- 可变长度输入。
缺点包括:比RNN更大的数据存储需求; 转移到不同的数据域时需要使用参数。
测试:
研究人员在多项序列建模任务中对比了TCN和RNN、LSTM等的表现,从MNIST、到字级和字符级语言模型。 11个任务中的9个TCN多表现出了超出其他技术的表现,剩下的其中一个大致与GRU相当,还有一个明显次于LSTM(虽然仍排在第二位)。
发生了什么:
“循环网络在序列建模中占的优势地位很可能成为历史。虽然直到最近,引入扩张卷积 (dilated convolutions) 和残差连接前,卷积架构还确实比较弱。但我们的结果表明,只要应用这些新技巧,一个简单的卷积架构,也可以在多数任务比LSTM这样的训话架构更有效。同时因为TCN相对来说的清晰性和简洁性,我们认为卷积网络会是序列建模中强大的工具组“ 研究人员写到。
为什么重要:
一个机器学习中最令人困惑的事情是,它还完全是经验学习,新技术的出现只能用其在多项任务上的表现来评判。类似此类的研究都暗示着,很多这样的新技术可能都过度复杂化了,往往我们只需要对一些基本的模块进行一些试调,就可以得出更好的结果,这在LSTM和GAN上也都能看到。从一方面来看这似乎是好的,因为简单的模型的模型有更大的灵活性和泛化性。但是从另一方面,这也揭示了现在AI里面很多复杂度不过是因为这是门经验科学的结果导致的,而不是因为坚实的理论基础。
更多:An Empirical Evaluation of Generic Convolutional andRecurrent Networks for Sequence Modeling (Arxiv).
Code for the TCN used in the experiments here(GitHub).
DeepChem 2.0 腾空出“室”

...开源科学计算平台发布其第二个主要版本...
DeepChem的作者已经发布了科学计算的2.0版图书馆,带来了TensorGraph API的改进,新模型 ,分子分析的工具,教程调整和补充,以及一大堆
常规的改进。 DeepChem“旨在提供高质量的开源工具链,在药物,材料科学,量子化学和生物学开发中实现了深度学习的民主化。”
更多:DeepChem 2.0版本说明.
更多:DeepChem网站.
谷歌研究人员利用神经网络解决内存的预取问题:
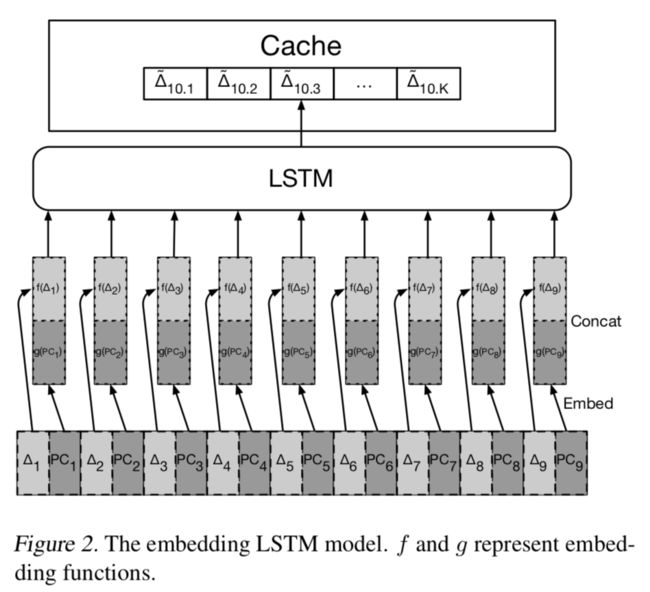
...先是数据库,现在是内存...
人工智能的一个奇怪的潜在应用是处理计算的基本方面,比如说对数据库进行搜索或预取数据以提高性能的系统,这些系统大多数是学习的而不是预编程的。这就是谷歌最近的一篇论文所提出的,其试图利用机器学习技术来解决预存问题,也就是"根据过去的历史来预测高速缓存中不会用到的存储部分”的过程。 预取是一个基本问题,因为预取越好,那么一端存储在被使用前被载入到缓存的几率也就越大,这可以很大程度提高你系统的表现。
工作原理:
预取可以学习吗? “预取基本上是个回归问题。然而,因为输出空间既庞大又极其稀疏,使其不适合标准回归模型“ Google研究人员写道。相反,他们转而使用LSTM,并且发现在预存问题上其两个变种能与人手动设置的系统性能相当。研究人员写道:“第一个版本类似于标准语言模型,而第二个则利用内存访问空间的结构,以减少词汇量并减少模型内存占用。” 他们用来自Google网络搜索任务的数据来测试了系统,并展现出很强的性能。
“论文中的模型比起基于表格的方法,展现出更高的精度和召回率。这项研究还激发了一系列这次探索没解决的问题,我们将其留于未来研究“ 他们写道。这项研究在思想上与Google去年秋天的一个研究类似,利用神经网络来学习数据库的索引结构,并且取得了很好的表现。
一件奇怪的事情:
在开发他们的LSTM之一时,研究人员创建了一个系统摄取的程序计数器的 t-SNE 嵌入,并发现其学习到的特征包含了相当多的信息。 “这个 t-SNE 的结果也展示了一个看待内存访问记录的有趣视角,那就是把它看做是程序行为的一个反应。一个记录表示与程序的输入输出对有着根本的不同,而应该把这些记录表示看做是对整个复杂的人类编写程序的表示。“ 他们写道。
更多:Learning Memory Access Patterns (Arxiv).
学会玩视频游戏,只需要几分钟而不是几天!
...当人工智能和分布式系统聚集在一起时,好事发生了...

加州大学伯克利分校的研究人员提出了一种方法,通过从基础计算基础设施中尽可能地提高效率,进一步优化大规模训练AI算法。他们的新技术使智能体能够在十分钟内在NVIDIA DGX-1(包含40个CPU和8个P100 GPUS)上训练强化学习代理,以掌握Atari游戏。虽然这些算法的样本效率仍然是远亚于人类(需要数百万帧才能接近以数千至数万帧为单位训练的人类的表现),但有趣的是,我们现在能够开发近似人类表现的算法,并且在相近的时间内。
结果:
研究人员表明,考虑到各种分布式系统对A2C,A3C,PPO和APPO等算法的调整,几分钟内即可在各种游戏中获得良好的性能。
为什么重要:
目前,对于某些AI研究人员来说,计算机功能类似于望远镜 - 望远镜的尺寸越大,越看到各种AI算法的缩放属性限制。 我们仍然没有完全理解这里的限制,但是像这样的研究表明,随着新的计算基板单独出现,它可能能够缩放RL算法,在相对较短的时间内实现非常令人印象深刻的技艺。 但是现在仍然有很多未知 - 这是一个激动人心的时刻! “我们还没有确定地确定缩放的限制因素,也没有确定每个游戏和算法的限制因素。虽然我们已经看到了大批量学习中的优化效果,但我们并不知道它们的全部性质,其他因素仍然有可能存在。异步缩放的限制仍然未被发现;我们并没有明确地确定这些算法的最佳配置,但只提供了一些成功的版本,”他们写道。
更多: Accelerated Methodsfor Deep Reinforcement Learning(Arxiv).