MapReduce程序——WordsCount 详解
程序功能:读取文件内容,按照空格或制表符对内容进行切分。并对切分后的内容进行计数,统计该内容出现的次数。
package mapreduce;
import java.io.IOException;
import java.net.URI;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job; //新版本的mapreduce包
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordsCount_01 {
/**
* 读取文件的地址
* 与输出文件的地址
*/
static String INPUT_PATH = "hdfs://master:9000/input/find/*";
static String OUTPUT_PATH = "hdfs://master:9000/output/WordCount01";
/**
* Map类,输入了LongWritable和Text类型
* 输出Text类和IntWritable类
*
* Map(k1,v1) k1读片偏移量(第几个文件),v1为片内容,一行行读取
* 将v1转为字符串并按照空格分割成一个个元素存在数组里
* 最后就是循环把数组里到元素和个数传入到上下文中
* @author sakura
*
*/
static class WordMapper extends Mapper{
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper.Context context) throws IOException, InterruptedException{
String[] words = value.toString().split("\\s"); // 转义后到 \s 匹配任意数量到空格和换行和制表符
for(String word : words){
context.write(new Text(word), new IntWritable(1));
}
};
}
/**
* Reducer类,输入Text和IntWritable类型
* 输出Text,IntWritable类型
*
* Reducer(k2,v2) k2=key 即k1不重复值的列表 每个reduce方法一次只处理一个key(已经被排序去重)
* v2即key出现的次数列表{1,2,1,4}
* 把v2的值放入迭代器中,计算值的总和
* 最后把key的值和总和sum传入到上下文中,就存入到我们到结果文件里
*/
static class WordReducer extends Reducer{
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException{
Iterator it = values.iterator();
int sum = 0;
while(it.hasNext()){
sum += it.next().get();
}
System.out.println("sum = " + sum);
context.write(key, new IntWritable(sum));
};
}
public static void main(String[] args) throws Exception {
/**
* mr要初始化Configuration,需读取配置文件
* 因为开发mapreduce时候只是在填空,在map函数和reduce函数里编写实际进行的业务逻辑,
* 其它的工作都是交给mapreduce框架自己操作的,但是至少我们要告诉它怎么操作,即在conf下到配置文件里
*/
Configuration conf = new Configuration();
/**
* 新建HDFS文件系统,读取输出文件夹
* 如果文件夹已经存在,则删除之
*/
FileSystem fs = FileSystem.get(new URI(INPUT_PATH),conf);
Path outPath = new Path(OUTPUT_PATH);
if(fs.exists(outPath)){
fs.delete(outPath,true);
System.out.println(outPath+"地址已经存在,已重建");
}
/**
* 第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,
* 而具体的map和reduce运算就是task了,这里我们构建一个job,
* 构建时候有两个参数,一个是conf,一个是这个job的名称,随意取。
*/
Job job = new Job(conf,"wordcount");
/**
* 装载一个mapreduce能执行到job的类,即WordsCount_01.class
*/
job.setJarByClass(WordsCount_01.class);
/**
* 构建输入到数据文件
* 和输出的数据文件
*/
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, outPath);
/**
* 装载Map实现类
* combiner阶段,在Reducer前就对相同到key进行了合并操作,使用原则,不影响到reduce计算的最终输入
* 和Reducer实现类
*/
job.setMapperClass(WordMapper.class);
job.setCombinerClass(WordReducer.class);//map运算到后续操作,在map计算出中间文件前做一个简单的合并重复key值的操作,比如重复的单词直接增加v1
job.setReducerClass(WordReducer.class);
/**
* 定义输出的key/value的类型,也就是最终存储在hdfs上结果文件的key/value的类型。
*/
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
/**
* 等待job运行成功
*/
job.waitForCompletion(true);
System.out.println("ending");
}
}
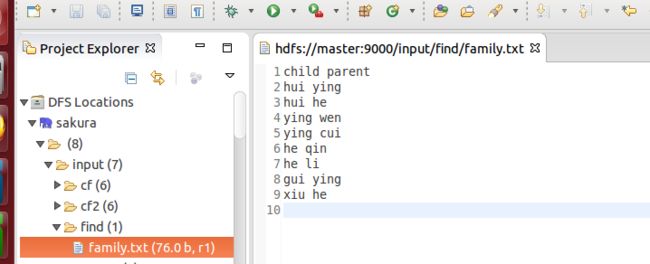
读取的文件内容
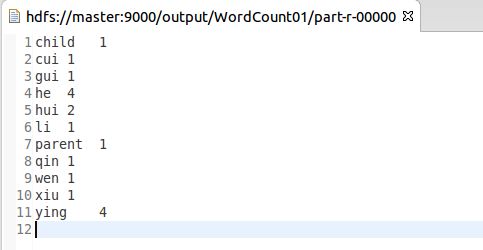
输出的结果
MapReduce程序——WordComparator 详解
程序功能:将wordsCount输出的内容按值进行降序排序。
package mapreduce;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.IntWritable.Comparator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordComparator {
static String INPUT_PATH = "hdfs://master:9000/output/WordCount01/p*";
static String OUTPUT_PATH = "hdfs://master:9000/output/WordCount01/out";
/**
* @param args
* @throws IOException
* @throws IllegalArgumentException
* @throws InterruptedException
* @throws ClassNotFoundException
*/
public static class myComparator extends Comparator {
@SuppressWarnings("rawtypes")
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
/**
* 以字节方式比较两个Writable对象,比较值的大小
* byte[] b1表示第一个参数的输入字节表示,byte[] b2表示第二个参数的输入字节表示
* b1表示前8个字节,b2表示后8个字节,字节是按次序依次比较的
* s1 The position index in b1. The object under comparison's starting index.第一列开始位置
* l1 The length of the object in b1.第一列长度 ,在这里表示长度8
*/
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
/**
*
* @author sakura
* 读取文件内容,按照制表符切分
* 将切分得到的第二份内容,即单词出现到次数作为Key传出去
* 将切分得到到第一份内容,即单词的内容作为Value传出去
*/
public static class Map extends Mapper {
public void map(Object key, Text value, Context context)
throws NumberFormatException, IOException, InterruptedException {
String[] split = value.toString().split("\t");
context.write(new IntWritable(Integer.parseInt(split[1])), new Text(split[0]));
}
}
/**
*
* @author sakura
* 因为mapreduce会自动对key进行排序,因此只要将读到的内容反向传出即可
* 即单词出现到次数作为Value传出去
* 即单词的内容作为Key传出去
*/
public static class Reduce extends Reducer {
public void reduce(IntWritable key, Iterable values, Context context)
throws IOException, InterruptedException {
for (Text text : values) {
context.write(text, key);
}
}
}
public static void main(String[] args)
throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI(INPUT_PATH),conf);
Path outPath = new Path(OUTPUT_PATH);
if(fs.exists(outPath)){
fs.delete(outPath,true);
System.out.println(outPath+"地址已经存在,已重建");
}
Job job = new Job();
job.setJarByClass(WordComparator.class);
job.setNumReduceTasks(1); // 设置reduce进程为1个,即output生成一个文件
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class); // 为job的输出数据设置key类
job.setOutputValueClass(IntWritable.class); // 为job的输出设置value类
job.setSortComparatorClass(myComparator.class); // 自定义排序
FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); // 设置输入文件的目录
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); // 设置输出文件的目录
System.exit(job.waitForCompletion(true) ? 0 : 1); // 提交任务
}
}
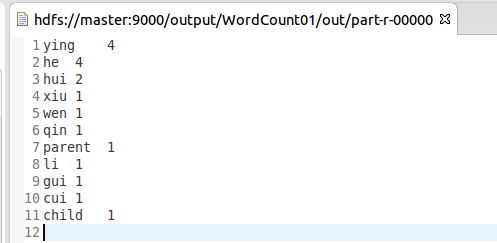
结果截图
通过这个我们,就可以试着分析一些我们想要分析的东西啦。
比如我喜欢看江南的《龙族》,所以我试着简单地切分它,看看它哪句话说得最多噢,哈哈哈
结果如下:
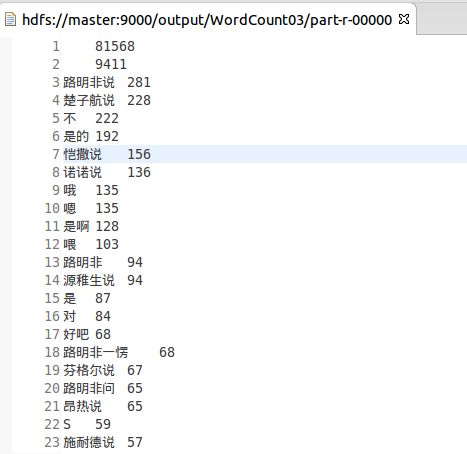
但是现在还不能实现很好地切分中文词,我正在学习当中啦!
我还有个大胆地想法,小数据分析自己的聊天记录,切分看看自己哪些词用得最多..... 然后嘿嘿嘿(逃