越来越多的公司开始尝试使用历史数据库来进行联机分析处理(OLAP)和实现决策支持系统(DSS)。很多人将数据仓库和多维数据库(MDDB)应用于高级系统如专家系统或DSS。这些系统可以用来解决半结构化甚至非结构化的问题。
决策支持系统和数据仓库
DDS决策支持系统是解决半结构化问题的系统-问题有结构化部分也有人工直觉部分。
DSS还可以让用户创造“what if”场景。DDS让用户通过应用他们自己的决策规则和直觉来控制系统的决策选择过程。
有其他方法来模拟多维表——oracle7.3 中使用的设计技术(push toward star schema design)。
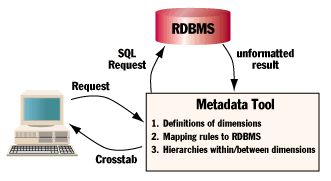
使用关系数据库实现OLAP是通过下列技术的综合来实现的:
pre-joining tables together预-连接表
对多个表的预连接生产的denormalized table去规格化表可以称为星型模式中的事实表。pre-summarization预-汇总
这是为了应付处理任何drill-down向下钻取细节数据的请求。Massive denormalization大量去规格化
存储空间越来越大越来越便宜,使得人们重新思考第三范式的优缺点。现在数据冗余已经是可以接受的了,且看如此多的复制工具,快照工具和非第一范式数据库的存在。如果预先生成尽可能多的结果表,在用户使用时就可以大大提升响应时间。星型模型就是大量去规格化的例子。Controlled periodic batch updating定期地批量更新
重新计算汇总值,并加入数据库。
数据聚集和向下钻取
MDDB最基本的原则就是聚集的思想。为了让管理者能选择不同的聚集层次,大多数数据仓库提供了“向下钻取”特性来允许用户选择不同层次的细节,最终访问原始交易数据。
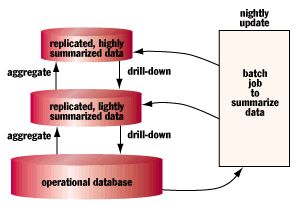
有很多类型的聚集,最常见的是“Roll-up”上卷。比如将日销售额上卷到月销售额。
Oracle对于MDDB的关系型解决方案
Dr. Ralph Kimball提出了使用星型模型来描述一个模拟MDDB结构并去规格化的过程。
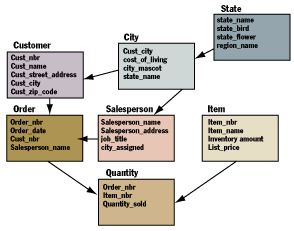
在上面的3NF数据库模型中,要查找123号订单的总交易额,必须对123号订单中的所有项进行quantity乘以price,并最终求和。
create table temp as
select (quantity.quantity_sold *
item.list_price) line_total
from quantity, item
where
quantity.order_nbr = 123
and
quantity.item_nbr = item.item_nbr;
select SUM(line_total) from temp;
为计算西部地区的所有订单交易额的和,需要进行五重表联合操作。
CREATE TABLE temp AS
SELECT (quantity.quantity_sold * item.list_price) line_total
FROM quantity, item, customer, city, state
WHERE
quantity.item_nbr = item.item_nbr /* join ITEM and QUANTITY */
AND
item.cust_nbr = customer.cust_nbr /* join ITEM and CUSTOMER */
AND
customer.city_name = city.city_name /* join CUSTOMER and CITY */
AND
city.state_name = state.state_name /* join CITY and STATE */
AND
state.region_name = 'WEST';
而星型模型的好处是为性能考虑而引入冗余数据。根本而言,一张事实表是一个对原交易数据的1NF表示的数据库,其中的数据存在大量冗余。
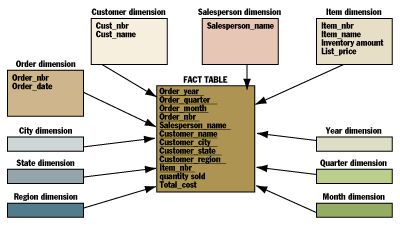
表中有些维度包含数据可以进行连接操作,有些维度如地域不包含任何数据。
虽然存在数据冗余,但星型模型带来的好处却是显而易见的。
比如,仍然要查找123号订单的总交易额:
select sum(total_cost) order_total
from fact
where
fact.order_nbr = 123;
比如,仍然计算西部地区的所有订单交易额的和,虽然数据不是按地域组织的,仍可以快速算出:
select sum(total_cost)
from fact
where
region = 'west'
除了简化查询结构外,所有的表连接操作都被消除了,你可以很方便地从星型模型中抽取数据。另外,类似地域这样的不超过3个离散值的列,通过使用位图索引,可以明显地提高性能。
这种方法的直接结果是商店会保留两份产品数据库,一份3NF交易数据库,另一份即用于决策支持和数据仓库应用的去规格化版本的数据库。
使用Oracle的分布式SQL来填充星型模型
那么,我们如何保证星型模型与操作型数据库同步一致?幸运的是,Oracle提供了多个机制来保证数据的同步一致。当然,星型模型是为了执行长期趋势分析,所以并不强制要求其与数据库保持一致。
在这种合理假设下,你就可以使用一条SQL语句来从操作数据库中抽取并填充新行到星型模型中。
假设星型模型位于London总部,对应的表为fact_table。
INSERT INTO fact_table@london
SELECT
order_year,
order_quarter,
order_month,
order_nbr,
salesperson_name,
customer_name,
customer_city,
customer_state,
customer_region,
item_nbr,
quantity_sold,
price*quantity_sold
FROM quantity, item, customer, city, state
WHERE
quantity.item_nbr = item.item_nbr /* join ITEM and QUANTITY */
AND
item.cust_nbr = customer.cust_nbr /* join ITEM and CUSTOMER */
AND
customer.city_name = city.city_name /* join CUSTOMER and CITY */
AND
city.state_name = state.state_name /* join CITY and STATE */
AND
order_date = SYSDATE /* get only today's transactions */
;
代码与前面的表并不完全对应。
当有些数据行需要被删除怎么办?比如交易被取消。这时候需要在操作数据库上建立一个delete触发器,当删除触发器被触发后会引起星型模型中所有对应的无效数据的删除。
CREATE TRIGGER delete_orders
AFTER DELETE ON order
BEGIN
DELETE FROM fact_table@london
WHERE
order_nbr=:del_ord
END;
这样就可以让星型模型与操作数据库相对同步。
当事实表扩展到超出其初始表容量怎么办?而且还要考虑索引带来的内存开销,对于多维表的查询可能涉及超过5个索引的读取。
为了减轻这个问题,许多设计者将表分割到较小的子表中,分开使用。比如,将每个月的数据分存到单独的表中fact_table_1_96, fact_table_2_96。当需要在单个操作中使用多张表时,就可以使用SQL union操作来合并表。
SELECT * FROM fact_table_1_96
UNION ALL
SELECT * FROM fact_table_2_96
UNION ALL
SELECT * FROM fact_table_3_96
ORDER BY order_year, order_month;
除了较小表索引外,这种表分割和union all操作带来了使得Oracle并行查询引擎可以在子表上同步进行全表扫描。这种情况下,系统为每个子表扫描启动一个进程。上例中,性能大概会有50%的提升。
聚集,上卷,和星型模型
运行时聚集的一个解决方案是提前编写SQL来根据用户可能感兴趣的维度预先聚集数据。