定义

除了实现了List接口,还实现了RandomAccess,Cloneable, java.io.Serializable接口
transient Object[] elementData; // non-private to simplify nested class access
transient 关键字使得进行序列化时会忽略此对象数组,主要考虑elementData在序列化时没有被占满,如果对elementData进行序列化时将造成空间和时间上的浪费,所以在序列化时是遍历数组非空元素。
3种构造函数
- 无参构造函数
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {} //0个元素的Object数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//默认初始化,没有分配堆内存空间
}
构造时是将空数组赋值给elementData ,但是在随后的第一个add元素的时候,会先新创建一个容量为10的初始数组。
- 初始容量构造函数
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];//分配指定初始容量的堆内存空间
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
- 初始集合构造函数
private static final Object[] EMPTY_ELEMENTDATA = {};
public ArrayList(Collection c) {
elementData = c.toArray();//集合转换成数组对象,并将引用直接赋值给缓冲数组
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class) // 类型检查
elementData = Arrays.copyOf(elementData, size, Object[].class); //拷贝并进行类型转换
} else { //如果集合长度为0,则将缓冲数组设置为0元素的空数组,没有分配堆内存空间
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
add
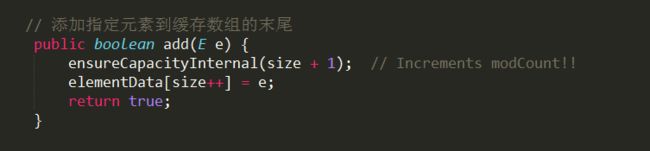
在尾部添加不需要通过复制来移动元素
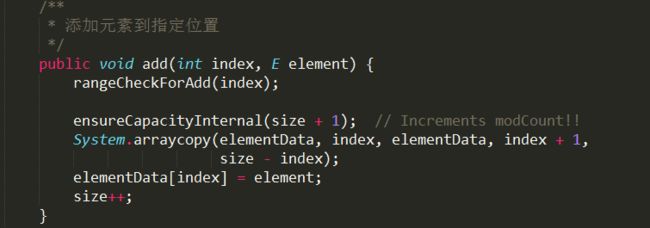
在指定位置上添加元素,需要通过原生方法System.arraycopy()复制来实现数组元素的移动
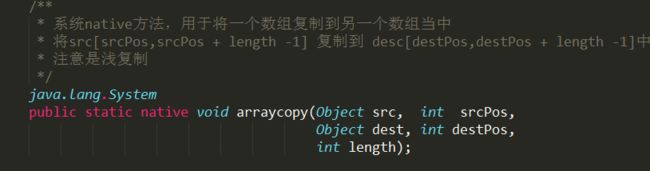
System.arraycopy()是一个原生的方法,效率较高,但注意的是这里的复制是浅复制,即只复制引用,对堆中始终只有一份元素对象。
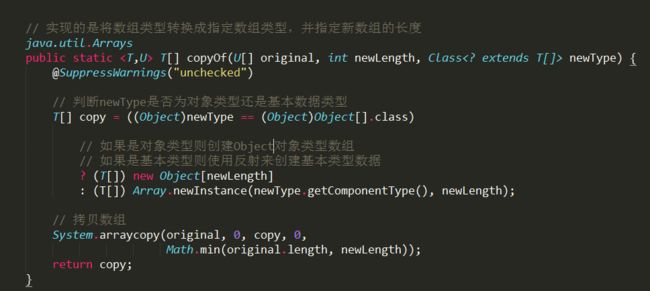
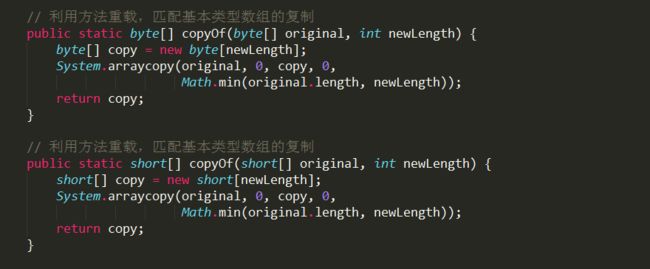
- Array.copyOf()方法通过方法签名来区别对待对象类型数组和基本类型数组,基本数据类型数组又是通过方法的重载来匹配不同基本数据类型。
- 在对象类型数组复制中,也会对对象类型进行判断,如果确认是Object类型则先创建Object数组,然后转型为指定类型T[],然后将旧数组元素复制到新创建的数组中;如果不是对象类型的数组,则通过Array.newInstance()反射创建基本类型的数组
remove
元素移动见下图 index == 2
0 1 2 3 4
0 1 3 4 4
0 1 3 4
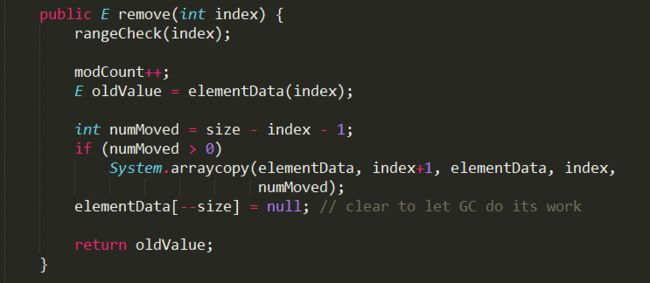
删除指定位置上的元素,时间复杂度为O(1)

删除第一个和指定对象相等的元素,会遍历整个数组,时间复杂度为O(n)
扩容函数
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) { // 当指定的最小容量大于最小拓展容量时才会进行扩容
ensureExplicitCapacity(minCapacity);
}
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++; // 每一次扩容都要增加修改计数
// overflow-conscious code
if (minCapacity - elementData.length > 0) // 溢出检查
grow(minCapacity);
}
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0) // 新的容量小于最小容量则将最小容量作为新的容量
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) // 如果新容量大于数组的最大长度则返回超大容量
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
// overflow 小于0,可能是容量本身为负,或者整数超大导致二进制溢出符号位变1,出现负值,反正都是溢出(上下溢出)
if (minCapacity < 0)
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ? // 判断最小容量是否大于最大数组长度
Integer.MAX_VALUE : // 大于则将整数的最大值作为新容量的大小
MAX_ARRAY_SIZE; // 否则把数组的最大长度作为新容量的大小
}
- 容量的理论最大值为Integer.MAX_VALUE,当数组长度超过MAX_ARRAY_SIZE时,会将数组扩容到理论最大值,见 hugeCapacity() 方法
- MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;是因为有些虚拟机会在数组类型数据堆中保留head Word字段会占用空间,所以可分配的数组长度达不到整数的最大值,-8 是一个保险值(32位JVM需要32位head word,64位JVM需要64位head word,即最多8字节),确保不会因为head word的空间占用而抛出OutOfMemoryError
序列化
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; iArrayList instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i 序列化分析详见
私有设计迭代器
public Iterator iterator() { // 返回的是Itr向上转型的Iterator接口
return new Itr();
}
private class Itr implements Iterator // 基于缓冲数组elementData进行设计的迭代器 私有内部类
public ListIterator listIterator() { // 返回的是ListItr向上转型的ListIterator接口
return new ListItr(0);
}
private class ListItr extends Itr implements ListIterator // 拓展了关于List的迭代器接口
私有迭代器,主要实现了范围检查以及配合游标的移动,实现了fail-fast机制(在遍历过程中如果modCount与expectedModCount不相等,则抛出ConcurrentModificationException异常),源码比较简单(思路和AbstractList.Itr、AbstractLsit.List.Itr一样),不在赘述。
iterator()方法对私有内部类进行了向上类型转换,而且将内部私有类也转换成了公有Iterator接口,可在类外获取此迭代器,同理ListIterator()
子列表的实现
public List subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex); // this 多态,方法动态绑定
}
private class SubList extends AbstractList implements RandomAccess {
private final AbstractList parent; // 通过持有父类对象实例,实现对实例方法的包装, 装饰器模式
private final int parentOffset;
private final int offset;
int size;
...
}
返回指定范围的子列表,同样是将私有内部实现转换成公有接口,完成面向接口的编程,将内部实现和公有接口进行分离。
子列表对象的通过装饰器模式和对象的多态(方法动态绑定),复用了ArrayList的代码实现,并实现了RandomAccess接口。
需要注意的是在子列表上的操作(如add、remove等)都会反映到原来的ArrayList上面(共用elementData),即子列表只是提供一种在原列表上的一种视图。
排序
public void sort(Comparator c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c); // 通过Array.sort排序
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
java8 并行迭代 Spliterator接口
public Spliterator spliterator() {
return new ArrayListSpliterator<>(this, 0, -1, 0);
}
static final class ArrayListSpliterator implements Spliterator {
private final ArrayList list;
private int index; // current index, modified on advance/split
private int fence; // -1 until used; then one past last index 最后一个元素的为位置,集合边界
private int expectedModCount; // initialized when fence set
/** Create new spliterator covering the given range */
ArrayListSpliterator(ArrayList list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
private int getFence() { // initialize fence to size on first use
int hi; // (a specialized variant appears in method forEach)
ArrayList lst;
if ((hi = fence) < 0) { // fence边界还没有初始化,则进行初始化边界
if ((lst = list) == null) // 列表为空引用,则初始边界及上边界为 0
hi = fence = 0;
else { // 列表不为null,则将集合的size作为边界和上边界的值
expectedModCount = lst.modCount;
hi = fence = lst.size;
}
}
return hi; // 返回上边界
}
public ArrayListSpliterator trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
// 只有low = index和hi相差为0或1时,才会发生条件为true的情况,此时可分割的范围太小,则不进行分割
return (lo >= mid) ? null : // divide range in half unless too small
// 将本身的集合迭代器边界设置为[mid,hi),并返回新的集合迭代器,范围为[lo,mid),实现遍历二分
new ArrayListSpliterator(list, lo, index = mid,expectedModCount);
}
public boolean tryAdvance(Consumer action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) { // 当当前索引小于边界(elementData 索引范围为[0,hi = size))
index = i + 1;
@SuppressWarnings("unchecked") E e = (E)list.elementData[i];
action.accept(e); // 对下一个剩余元素执行操作
if (list.modCount != expectedModCount) // fail-fast机制
throw new ConcurrentModificationException();
return true;
}
return false;
}
public void forEachRemaining(Consumer action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList lst; Object[] a;
if (action == null)
throw new NullPointerException();
//当集合引用不为null,且集合的缓冲数组不为null
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) { //当fence边界没有初始化则将集合的size作为边界
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) { // 遍历执行
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc) // fail-fast机制
return;
}
}
throw new ConcurrentModificationException(); // fail-fast机制
}
}
Spliterator 是Java8 引入的新接口,顾名思义,Spliterator可以理解为Iterator的Split版本,对于Java的流API,进行并行分割迭代计算,充分利用多核CPU的优势,并行计算具有极大的辅助作用。在使用Iterator的时候,我们一般都是单线程地去顺序遍历集合的元素,但是使用Spliterator可以将集合元素分割成多份,使用多个线程 同时进行迭代,大大地提高了执行效率。
// 判断时候还有元素,如果有则对下一个剩余的元素执行action操作,
// 如果没有下一个剩余的元素可以被执行则返回false,否则返回true
boolean tryAdvance(Consumer action);
// 对每一个剩余的元素都执行action操作
default void forEachRemaining(Consumer action) {
do { } while (tryAdvance(action)); // 通过调用tryAdvance实现
}
// 如果集合可以分割,则对集合进行分割,并返回Spliterator
Spliterator trySplit();
...
3 种访问元素访问
- 随机访问
String value = null;
int size = list.size();
for (int i=0; i此方法是直接在缓冲数组上的通过索引访问的,速度最快
- foreach访问
String value = null;
for(String a : list){
value = a;
}
foreach访问也比随机访问要慢,但是要快于迭代器的方式(foreach是一种语法糖,在编译期间需要进行语法解析,插入额外的辅助访问的代码,会有一定的消耗)
- 迭代器访问
String value = null;
Iterator iter = list.iterator();
while (iter.hasNext()) {
value = (String )iter.next();
}
速度最慢,由于要保存迭代器的状态,所以性能受到损耗
总结
- 当新增元素时通过ensureCapacityInternal来扩大elementData的指定新增的容量,删除元素时,只是将elementData的指定位置引用赋值为null,方便GC回收,重新复制数组减少容量;而且无参构造函数只有第一次添加元素时才会分配存储空间。
- ArrayList是通过缓冲数组elementData来保存数据的,当容量不够时,对element进行扩容(** int newCapacity = oldCapacity + (oldCapacity >> 1);即增加原来容量的一半**),所有的查询和修改都是通过数组的索引来操作elementData数组的
- ArrayList有三种构造函数,一种是指定初始容量的,会创建一个初始容量的数组并赋值给elementData引用,一种是默认构造函数,使用的是默认容量10,一种是通过一个集合来构建
- clone函数,底层通过System.arraycopy将原来ArrayList的缓冲数组elementData拷贝给新的ArrayList的缓冲数组
- 每一次影响集合结构的修改(包括增加、删除、扩容、移动元素位置,不包括修改set)ArrayList的时候都要使得modCount自增,确保感知在使用迭代器和进行序列化过程中是否发生并发修改ArrayList的情况
- 序列化时先写集合的size(不是容量即element的长度)到输出流,然后在写elementData数组元素到输出流,反序列化时则是先读集合容量,然后在读集合元素。
- 在子列表上的操作(如add、remove等)都会反映到原来的ArrayList上面(共用elementData),即子列表只是提供一种在原列表上的一种视图。