点击这里进入人工智能嘚吧嘚目录,观看全部文章
职友集是一家汇聚全网众多招聘信息的网站,并具有很多职位趋势分析。
这篇文章介绍如何快速爬取职友集网站的信息。
爬虫思路分析
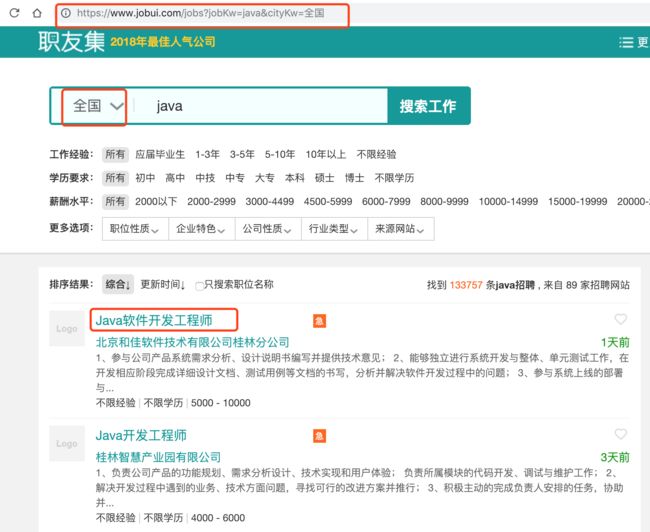
首先确认需要爬取的职位信息的地址格式是https://www.jobui.com/jobs?jobKw={key_word}&cityKw={city_name}。

然后确认我们所需要的职位详细页面链接格式是https://www.jobui.com/job/{job_id}/
我们只需要从职位列表页面获取每个职位对应的职位详细页面链接,即可对获取到职位详细信息。而每个职位的链接其实就是职位列表页每个职位标题的href属性。
所以我们把爬虫分为三步(以10页为例):
-
爬取职位列表页面的链接,每页17个,分10页可以爬取170个链接,最好存储到文件以备下一步使用。
-
从存储的链接文件中一次读取全部170个链接,然后逐个链接爬取,并且将网页源码分别存储为170个文件备用。
-
从存储的170个职位文件中读取数据,这些数据都是html源码,可以用BeautifulSoup解析。
爬取职位详情的全部链接
习惯性的在浏览器登录注册,从控制台Networks中找到/jobs?...请求并copy request headers获得请求头字符串,并利用str2dict函数转为dict对象备用。
header_str='''
GET /jobs?jobKw=python&cityKw=%E5%85%A8%E5%9B%BD&n=2&taget=subscribe HTTP/1.1
Host: www.jobui.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
...
'''
#字符串转dict的方法
def str2dict(s,s1=';',s2='='):
li=s.split(s1)
res={}
for kv in li:
li2=kv.split(s2)
if len(li2)>1:
res[li2[0]]=li2[1]
return res
headers=str2dict(header_str,'\n',': ')
headers
这里的headers看起来是这样的一个dict:
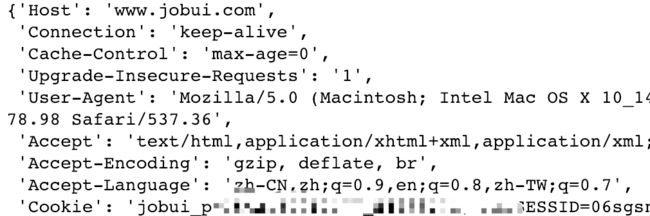
下面是获取链接link的函数
import requests
from bs4 import BeautifulSoup
urlstr = 'https://www.jobui.com/jobs?jobKw={kw}&cityKw=%E5%85%A8%E5%9B%BD&n={n}'
#n,页码,第几页;kw,搜索词,如'python'
def getLinks(n,kw):
links = []
url = urlstr.format(n=n,kw=kw)
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text)
jobs = soup.find('ul', {'data-jobidlist': True})
jobs=jobs.find_all('li')
for job in jobs:
atag = job.find('h3', {'data-positionid': True}).parent
links.append('https://www.jobui.com' + atag['href']) #获取到链接href属性
return links
先从大数据工程师.json中读出已有的全部链接,放入all_links,然后再启动爬虫爬取新的链接也放入all_links,并且去除重复,重新存储大数据工程师.json覆盖,实现新增链接。
#获取detail页面链接
import json
import os
import time
kw = '大数据工程师'
all_links = []
linkfdr = './jobui/links/'
file = linkfdr + '{}.json'.format(kw)
if not os.path.exists(linkfdr): #如果文件夹不存在就创建它
os.makedirs(linkfdr)
#先读取已有的,避免重复
if os.path.isfile(file):#检查文件存在
with open(file, 'r') as f:
all_links = json.loads(f.read())
#增加新的链接
for i in range(0, 10):
print('Crawling LINK:', i)
try:
all_links = all_links + getLinks(i, kw)
time.sleep(1)
except:
print('Get link failed.')
with open(file, 'w') as f:
all_links = list(set(all_links)) #去重复
f.write(json.dumps(all_links))
print('LINK OK!')
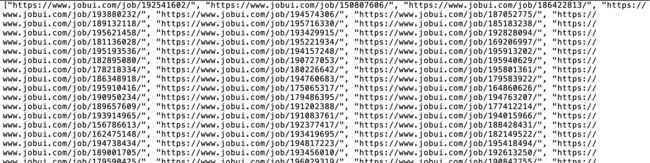
这个代码将在当前文件夹的/jobui/link/文件夹中创建一个以kw命名的.json文件,比如大数据工程师.json,其中包含了10个页面共170个职位链接地址,看起来如下:
爬取并存储每个职位详情源码
根据链接读取文件并存储的函数。
#link,职位页面的地址,http://...完整地址;keyw,关键词,将作为存放网页源码文件的文件夹名称。
def getHtml(link, keyw):
res = requests.get(link, headers=headers)
fdr = './jobui/{}/'.format(keyw)
if not os.path.exists(fdr):
os.makedirs(fdr) #如果不存在文件夹则创建它
fname = link.split('/')[-2:-1][0] #从https://.../job/194131276/中获得194131276
with open(fdr + fname + '.html', 'w',encoding='utf-8') as f:
f.write(res.text)
从大数据工程师.json中读取全部link,为每个link启动getHtml爬取数据并存储页面源码。
#读取link文件中所有链接的html
read_links = []
keyfdr = kw
link_file = linkfdr + '{}.json'.format(keyfdr)
with open(link_file, 'r') as f:
links = json.loads(f.read())
for link in links:
print('Getting HTML:', link)
try:
getHtml(link, keyfdr)
except:
print('--failed')
time.sleep(1)
print('HTML OK!')
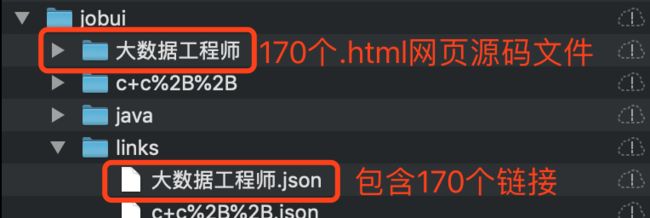
最终生成的文件目录大致是:
注意参考0112编程-windows和mac的python文件读写编码
点击这里进入人工智能DBD嘚吧嘚目录,观看全部文章
每个人的智能新时代
如果您发现文章错误,请不吝留言指正;
如果您觉得有用,请点喜欢;
如果您觉得很有用,欢迎转载~
END