总结一下自己的一点见解
1.1首先需要了解数据库查找的过程
磁盘是一个扁平的圆盘(与电唱机的唱片类似)。盘面上有许多称为磁道的圆圈,数据就记录在这些磁道上。磁盘可以是单片的,也可以是由若干盘片组成的盘组,每一盘片上有两个面。如下图中所示的6片盘组为例,除去最顶端和最底端的外侧面不存储数据之外,一共有10个面可以用来保存信息。

当磁盘驱动器执行读/写功能时。盘片装在一个主轴上,并绕主轴高速旋转,当磁道在读/写头(又叫磁头) 下通过时,就可以进行数据的读 / 写了。
一般磁盘分为固定头盘(磁头固定)和活动头盘。固定头盘的每一个磁道上都有独立的磁头,它是固定不动的,专门负责这一磁道上数据的读/写。
活动头盘 (如上图)的磁头是可移动的。每一个盘面上只有一个磁头(磁头是双向的,因此正反盘面都能读写)。它可以从该面的一个磁道移动到另一个磁道。所有磁头都装在同一个动臂上,因此不同盘面上的所有磁头都是同时移动的(行动整齐划一)。当盘片绕主轴旋转的时候,磁头与旋转的盘片形成一个圆柱体。各个盘面上半径相同的磁道组成了一个圆柱面,我们称为柱面 。因此,柱面的个数也就是盘面上的磁道数。
1.2磁盘的读/写原理和效率
磁盘上数据必须用一个三维地址唯一标示:柱面号、盘面号、块号(磁道上的盘块)。
读/写磁盘上某一指定数据需要下面3个步骤:
(1) 首先移动臂根据柱面号使磁头移动到所需要的柱面上,这一过程被称为定位或查找 。
(2) 如上图11.3中所示的6盘组示意图中,所有磁头都定位到了10个盘面的10条磁道上(磁头都是双向的)。这时根据盘面号来确定指定盘面上的磁道。
(3) 盘面确定以后,盘片开始旋转,将指定块号的磁道段移动至磁头下。
经过上面三个步骤,指定数据的存储位置就被找到。这时就可以开始读/写操作了。
访问某一具体信息,由3部分时间组成:
● 查找时间(seek time) Ts: 完成上述步骤(1)所需要的时间。这部分时间代价最高,最大可达到0.1s左右。
● 等待时间(latency time) Tl: 完成上述步骤(3)所需要的时间。由于盘片绕主轴旋转速度很快,一般为7200转/分(电脑硬盘的性能指标之一, 家用的普通硬盘的转速一般有5400rpm(笔记本)、7200rpm几种)。因此一般旋转一圈大约0.0083s。
● 传输时间(transmission time) Tt: 数据通过系统总线传送到内存的时间,一般传输一个字节(byte)大概0.02us=210^(-8)s
磁盘读取数据是以盘块(block)为基本单位的。位于同一盘块中的所有数据都能被一次性全部读取出来。而磁盘IO代价主要花费在查找时间Ts上。因此我们应该尽量将相关信息存放在同一盘块,同一磁道中。或者至少放在同一柱面或相邻柱面上,以求在读/写信息时尽量减少磁头来回移动的次数,避免过多的查找时间Ts*。
1.3
sql语句和其他语言没有多大的区别,需要经过解析器和编译器来转换成二进制代码。在sql中还有优化性能的缓存等组件。
block数据由DMA从硬盘copy到内存中

2.1
mysql优化可以朝着上面描述等几个方面去着手。
● 对于查找时间的优化,sql聚集索引使用b-树来减小查找时间
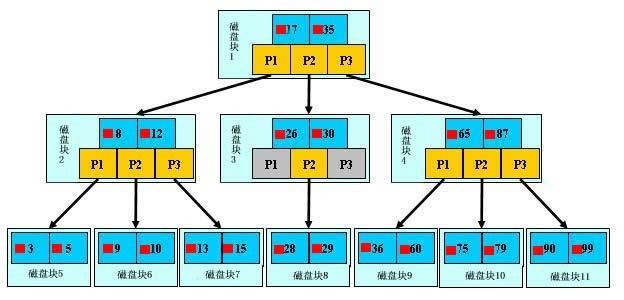
由上图可以明白,查找到对应盘块记录的次数为树的高度,这也是它比二叉树所在对优势,底的增大使得树的高度减小,从而减小查询次数。在此基础上,发展出了B+树,b*树更加增加了数据的查找的性能。
●对与聚集索引,因为其为在空间中连续的存储,所以最好不要进行大量的修改和增删操作。
b+树在表单数据量非常庞大时会退化成遍历查询,所以在表单数据量变得很大的时候我们需要对表进行分区操作,具体操作请看(http://www.cnblogs.com/AK2012/archive/2012/12/25/2012-1228.html)
●对于sql非聚集索引,采用的是另外一种为r树的数据结构。
下图是Guttman论文中的一幅图:
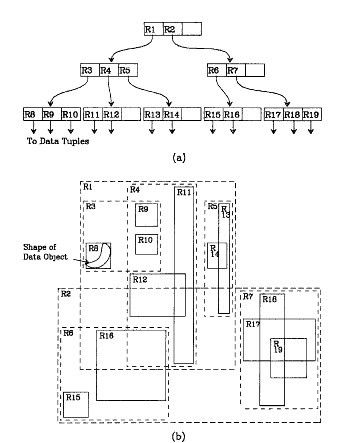
这里简单解释一下,对于空间中不规则的r8,用最小的矩形来把它包裹住,而r9,r10也是相同的道理。r8,r9,r10的页节点为r3,为叶子节点的最小包裹矩形,依次类推。
r树很好的解决了不连贯的空间存储如何查找的问题,但是扩展到6维以上会导致r树性能下降退化为遍历操作(我不是很明白这点)
非聚集索引使用指针来表达对应的区块,使得修改操作变得容易很多。
3.优化
3.1
对于sql语句编译和解析器来说,
select ** from dual *
SELECT * FROM dual
为不同的语句,这样在编译的时候会增加编译的时间,所以在写sql语句的时候尽聊使用规范化的语句,保证一致性。
**select * from orderheader where changetime >'2010-10-20 00:00:01'
**select * from orderheader where changetime >'2010-09-22 00:00:01'
以上两句语句,查询优化器认为是不同的SQL语句,需要解析两次。如果采用绑定变量
select * from orderheader where changetime >@chgtime
3.2
有的时候会需要进行一些模糊查询比如
select*from contact where username like ‘%yue%’
关键词%yue%,由于yue前面用到了“%”,索引这时候实效sql引擎便会遍历全表,除非必要,否则不要在关键词前加%。尽量使用yue%等确定的前缀
3.3
绑定变量在php和java对数据库操作的时候很常见,我在查找python对次此采取的操作时并没有查到对应的方法。
先给sql引擎发送一个sql语句,后面使用绑定变量,引擎中语句缓存会识别语句从而减少解析和编译的时间。
我看到一篇blog中写的批量执行语句时已经对绑定变量做了优化的。(MySQLdb中的cursor.executemany我怀疑并没有做对应的优化策略)
3.4尽量少使用or语句,在执行or语句的时候,sql引擎会放弃索引查找的方式而使用遍历查找,极大的增加了查询的时间。
3.5
使用temp表单来减少对主表对查询操作,减轻主表热点程度。大大减少了程序执行中“共享锁”阻塞“更新锁”,减少了阻塞,提高了并发性能。
3.6
SQL Server中一句SQL语句默认就是一个事务,在该语句执行完成后也是默认commit的。其实,这就是begin tran的一个最小化的形式,好比在每句语句开头隐含了一个begin tran,结束时隐含了一个commit。
有些情况下,我们需要显式声明begin tran,比如做“插、删、改”操作需要同时修改几个表,要求要么几个表都修改成功,要么都不成功。begin tran 可以起到这样的作用,它可以把若干SQL语句套在一起执行,最后再一起commit。好处是保证了数据的一致性,但任何事情都不是完美无缺的。Begin tran付出的代价是在提交之前,所有SQL语句锁住的资源都不能释放,直到commit掉。
可见,如果Begin tran套住的SQL语句太多,那数据库的性能就糟糕了。在该大事务提交之前,必然会阻塞别的语句,造成block很多。
Begin tran使用的原则是,在保证数据一致性的前提下,begin tran 套住的SQL语句越少越好!有些情况下可以采用触发器同步数据,不一定要用begin tran。
3.7
SQL Server 表连接的三种方式(参考链接地址:http://www.cnblogs.com/ATree/archive/2011/02/13/sql_optimize_1.html)
(1) Merge Join
(2) Nested Loop Join
(3) Hash Join
SQL Server 2000只有一种join方式——Nested Loop Join,如果A结果集较小,那就默认作为外表,A中每条记录都要去B中扫描一遍,实际扫过的行数相当于A结果集行数x B结果集行数。所以如果两个结果集都很大,那Join的结果很糟糕。
SQL Server 2005新增了Merge Join,如果A表和B表的连接字段正好是聚集索引所在字段,那么表的顺序已经排好,只要两边拼上去就行了,这种join的开销相当于A表的结果集行数加上B表的结果集行数,一个是加,一个是乘,可见merge join 的效果要比Nested Loop Join好多了。
如果连接的字段上没有索引,那SQL2000的效率是相当低的,而SQL2005提供了Hash join,相当于临时给A,B表的结果集加上索引,因此SQL2005的效率比SQL2000有很大提高,我认为,这是一个重要的原因。
总结一下,在表连接时要注意以下几点:
(1) 连接字段尽量选择聚集索引所在的字段
(2) 仔细考虑where条件,尽量减小A、B表的结果集
4
在物理层面上
●增加磁盘的转速(比较难以实现)
●横向扩展和纵向扩展(由于硬件设备价格的持续下降,很多都会采用这样的方式)
使用横向扩展,用负载均衡设备(h5)或者是计算机(使用负载均衡软件Ngix等)对大量sql语句请求做分流可以大大减轻单个设备的压力。
纵向扩展不太了解,先暂时放一放(==)
●读写分离策略
实际上大量的sql请求为读请求,在一台master机器上执行update/insert操作,而在多台slave机器上执行读请求也可以降低设备压力。master把更后的表单再 copy给slave。