这次多变量线性回归模型用的数据集是在alr3包名叫water的数据集。
library(alr3)
data("water")
str(water)
'data.frame': 43 obs. of 8 variables:
APMAM : num 9.13 5.28 4.2 4.6 7.15 9.7 5.02 6.7 10.5 9.1 ...
APSLAKE: num 3.91 5.2 3.67 3.93 4.88 4.91 1.77 6.51 3.38 4.08 ...
OPRC : num 7.43 11.11 12.2 15.15 20.05 ...
BSAAM : int 54235 67567 66161 68094 107080 67594 65356 67909 92715 70024 ...
head(water)
Year APMAM APSAB APSLAKE OPBPC OPRC OPSLAKE BSAAM
1 1948 9.13 3.58 3.91 4.10 7.43 6.47 54235
2 1949 5.28 4.82 5.20 7.55 11.11 10.26 67567
3 1950 4.20 3.77 3.67 9.52 12.20 11.35 66161
4 1951 4.60 4.46 3.93 11.14 15.15 11.13 68094
5 1952 7.15 4.99 4.88 16.34 20.05 22.81 107080
6 1953 9.70 5.65 4.91 8.88 8.15 7.41 67594
water数据集一共有8个变量,43行观测值,最后一个特征BSAAM是响应变量,其中第一个变量是年份,与模型需要预测的响应变量无关,去除后得到新的数据集。
socal.water <-water[,-1]
head(socal.water)
APMAM APSAB APSLAKE OPBPC OPRC OPSLAKE BSAAM
1 9.13 3.58 3.91 4.10 7.43 6.47 54235
2 5.28 4.82 5.20 7.55 11.11 10.26 67567
3 4.20 3.77 3.67 9.52 12.20 11.35 66161
4 4.60 4.46 3.93 11.14 15.15 11.13 68094
5 7.15 4.99 4.88 16.34 20.05 22.81 107080
6 9.70 5.65 4.91 8.88 8.15 7.41 67594
所有数据都是数值类型,为了避免多重共线性,需要做自变量的相关性检查。
library(corrplot)
water.cor <- cor(socal.water)
corrplot(water.cor,method = "number")
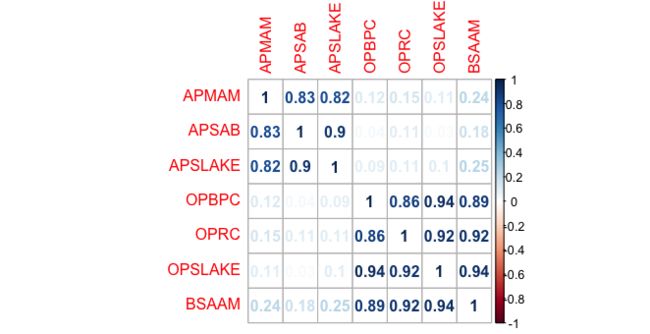
前三个自变量的特征高度相关,后三个自变量的特征也高度相关。
除了corrplot,另外一种常用的可视化的相关性检查可以通过pairs()函数。
pairs(~.,data = socal.water)

可以看到前三个自变量的散点图呈线性分布,后三个自变量也是。
先忽略多重共线性,对数据做一次回归,后面再做特征选择。
fit <- lm(BSAAM~.,data = socal.water)
summary(fit)
Call:
lm(formula = BSAAM ~ ., data = socal.water)
Residuals:
Min 1Q Median 3Q Max
-12690 -4936 -1424 4173 18542
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15944.7 4099.8 3.89 0.00042 ***
APMAM -12.8 708.9 -0.02 0.98572
APSAB -664.4 1522.9 -0.44 0.66524
APSLAKE 2270.7 1341.3 1.69 0.09911 .
OPBPC 69.7 461.7 0.15 0.88084
OPRC 1916.5 641.4 2.99 0.00503 **
OPSLAKE 2211.6 752.7 2.94 0.00573 **
Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 7560 on 36 degrees of freedom
Multiple R-squared: 0.925, Adjusted R-squared: 0.912
F-statistic: 73.8 on 6 and 36 DF, p-value: <2e-16
第一、二、四个变量不通过假设检验,对于特征选择,我们可以选择leaps包的最优子集回归。
sub.fit <- regsubsets(BSAAM~.,data = socal.water)
best.summary <- summary(sub.fit)
names(best.summary)
[1] "which" "rsq" "rss" "adjr2" "cp" "bic" "outmat" "obj"
最常用的特征选择统计方法有四个,赤池信息量准则(AIC),马洛斯的Cp,贝叶斯信息量准则(BIC)和修正R方(Adjusted R-squared)。
AIC和Cp最求最小化,修正R方追求最大化。
最优子集回归输出了Cp、bic和修正R方三种统计方法。
which.max(best.summarybic)
[1] 3
修正R方和BIC都显示最优模型的特征数量是3个,我们可以通过Cp画出统计图。
par(mfrow=c(1,2))
plot(best.summary$cp,xlab = "number of features",ylab = "Cp")
plot(sub.fit,scale = "Cp")
最终得到的是,第三、五、六个特征生成的模型拥有最小的Cp,且通过之前的假设检验。
我们再用这三个特征生成模型观察结果。
best.fit <- lm(BSAAM~APSLAKE+OPRC+OPSLAKE,data = socal.water)
summary(best.fit)
Call:
lm(formula = BSAAM ~ APSLAKE + OPRC + OPSLAKE, data = socal.water)
Residuals:
Min 1Q Median 3Q Max
-12964 -5140 -1252 4446 18649
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15425 3638 4.24 0.00013 ***
APSLAKE 1712 500 3.42 0.00148 **
OPRC 1798 568 3.17 0.00300 **
OPSLAKE 2390 447 5.35 4.2e-06 ***
Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 7280 on 39 degrees of freedom
Multiple R-squared: 0.924, Adjusted R-squared: 0.919
F-statistic: 159 on 3 and 39 DF, p-value: <2e-16
模型拟合得很好,我们plot一下观察是否通过线性回归的统计假设检验。
par(mfrow=c(2,2))
plot(best.fit)
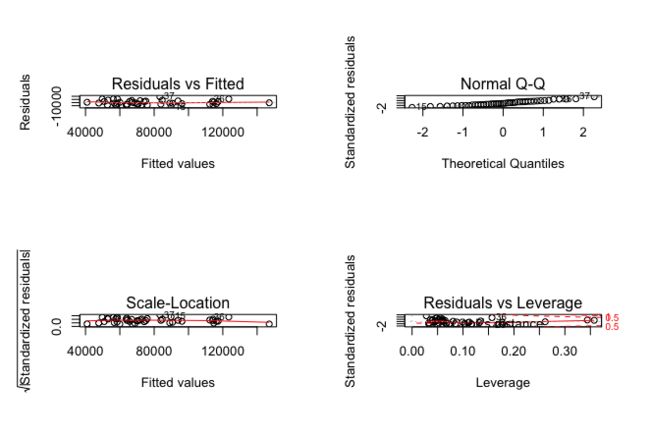
通过假设检验,我们再看看之前的多重共线性问题。
多重共线性可以通过car包的vif()函数,输出方差膨胀因子(VIF)这个统计量。
VIF值最小值为1,表示根本不存在多重共线性,,一般认为VIF值超过5则说明存在严重的多重共线性。
vif(best.fit)
APSLAKE OPRC OPSLAKE
1.011 6.453 6.445
很明显,OPRC和OPSLAKE存在严重的多重共线性。
解决共线性最简单的方式就是,再不影响预测能力的前提下去除这个变量。
我们可以看看最优子集回归的best.summary。
par(mfrow=c(1,1))
plot(sub.fit,scale = "adjr2")
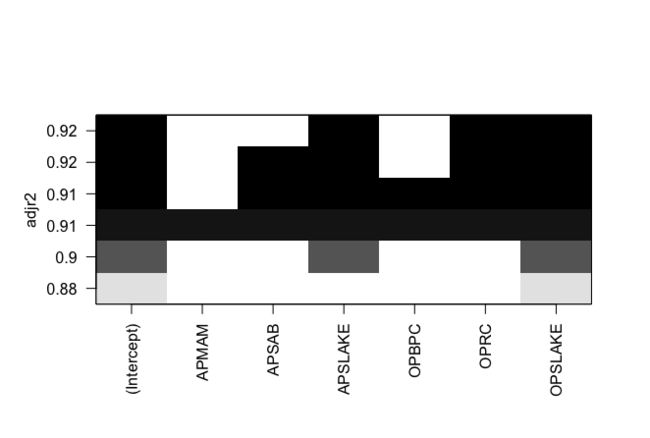
统计图显示,去除了OPRC特征之后,adjr2(修正R方)仍然具有0.9的预测能力。
再次用去除OPRC之后的特征拟合模型。
fit.2 <- lm(BSAAM~APSLAKE+OPSLAKE,data = socal.water)
summary(fit.2)
Call:
lm(formula = BSAAM ~ APSLAKE + OPSLAKE, data = socal.water)
Residuals:
Min 1Q Median 3Q Max
-13336 -5893 -172 4220 19500
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19145 3812 5.02 1.1e-05 ***
APSLAKE 1769 554 3.19 0.0027 **
OPSLAKE 3690 196 18.83 < 2e-16 ***
Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 8060 on 40 degrees of freedom
Multiple R-squared: 0.905, Adjusted R-squared: 0.9
F-statistic: 190 on 2 and 40 DF, p-value: <2e-16
再plot一下看是否通过统计假设检验。
par(mfrow = c(2,2))
plot(fit.2)