
前言
本文利用python的scrapy框架对虎牙web端的主播、主播订阅数、主播当前观看人数等基本数据进行抓取,并将抓取到的数据以csv格数输出,以及存储到mongodb中
思路
观察虎牙网站后确认所有频道url都在www.huya.com/g中的,而主播房间数据则是ajax异步数据,获取数据的链接为
http://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId={频道id}&tagAll=0&page={页码}
该链接通过控制gameId和page来返回某频道下某页的数据,根据以上观察爬行设计思路如下
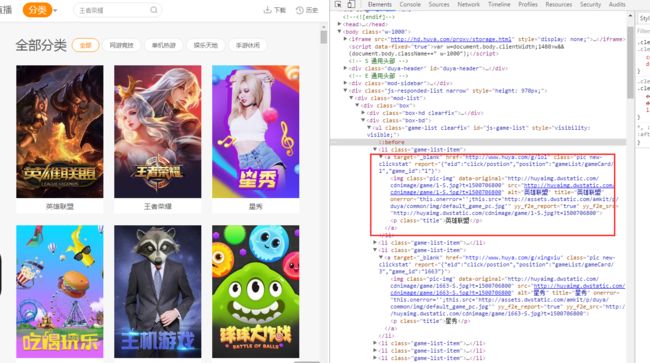
第一步:访问www.huya.com/g页面,在li(class类型为game-list-item)中获取当前所有频道的链接、标题、频道id
第二步:根据第一步获取到的频道的链接进入频道页面,在频道页面获取当前频道页数,再根据该频道id,页数构造异步数据请求链接
第三步:从第二步中获取频道返回的异步数据内容,将返回的json数据类型转化为字典,再获取要抓取的目标内容。
第四步:向第三步中获取到的主播房间url发出请求,进入房间页面后抓取主播订阅数
第五步:将数据输出为csv格式以及存在mongodb数据库中。
代码
items
在items中定义要抓取的字段内容,items代码如下
class HuyaspiderItem(scrapy.Item):
channel = scrapy.Field() #主播所在频道
anchor_category = scrapy.Field() #主播类型
anchor_name = scrapy.Field() #主播名称
anchor_url = scrapy.Field() #直播房间链接
anchor_tag = scrapy.Field() #主播标签
anchor_roomname = scrapy.Field() #主播房间名称
position = scrapy.Field() #当前频道的主播排名
watch_num = scrapy.Field() #观看人数
fan_num = scrapy.Field() #订阅数量
crawl_time = scrapy.Field() #爬取时间
pipelines
在pipelines中设置输出为csv表以及将数据保存到mongodb中,pipelines代码设置如下
# -*- coding: utf-8 -*-
import json,codecs
import pymongo
class HuyaspiderPipeline(object):
def __init__(self):
self.file = codecs.open('huyaanchor.csv','wb+',encoding='utf-8') #创建以utf-8编码的csv文件
client = pymongo.MongoClient('localhost',27017) #创建mongodb连接
db = client['huya'] #创建mongodb数据库huya
self.collection =db['huyaanchor'] #创建数据库huya中collection
def process_item(self, item, spider):
item = dict(item) #将抓到的item转为dict格式
line = json.dumps(item)+'\n' #定义line字段将抓到的item转为jump格式,加上空格换行
self.file.write(line.decode('unicode_escape')) #将line写进csv中输出
self.collection.insert(item) #将item写进mongodb中
middlewares
在middlewares中以继承UserAgentMiddleware父类方式创建创建HuyaUserAgentMiddlewares类,该类用于scrapy每次执行请求时使用指定的useragent,middlewares代码如下
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
class HuyaUserAgentMiddleware(UserAgentMiddleware):
def __init__ (self,user_agent=""):
'''定义随机user_agent列表'''
self.user_agent =user_agent
self.ua_list = ["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",]
self.count=0
def process_request(self,request,spider):
ua ='Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:53.0) Gecko/20100101 Firefox/53.0'
request.headers.setdefault('Use-Agent',ua) #设定reuqest使用的Use-Agent为ua
request.headers.setdefault('Host','www.huya.com') #设定reuqest使用的Host为www.huya.com
request.headers.setdefault('Referer','http://www.huya.com/') #设定reuqest使用的Referer为http://www.huya.com/
settings
settings配置如下,在“DOWNLOADER_MIDDLEWARES”以及“ITEM_PIPELINES”设置上述items和middlewares中的配置。
DOWNLOADER_MIDDLEWARES = {
'huyaspider.middlewares.HuyaUserAgentMiddleware': 400, #启动middlewares中设定好的usragent
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':None, #禁用默认的usragent
}
ITEM_PIPELINES = {
'huyaspider.pipelines.HuyaspiderPipeline': 300, #设置pipelines
}
spider
在spider中定义了parse、channel_get、channel_parse、room_parse四个函数,其作用说明如下
parse :获取虎牙下所有频道的url 、频道id 、频道名称
channel_get : def parse的回调函数,根据频道id构造主播数据连接并执行请求
channel_parse :channel_get 的回调函数,根据返回的json数据抓取相应内容,并抓出主播的房间链接,对房间链接执行请求
room_parse :channel_parse的回调函数,抓取主播的订阅数量
代码如下
# -*- coding: utf-8 -*-
import scrapy,re,json,time
from scrapy.http import Request
from huyaspider.items import HuyaspiderItem
class HuyaSpider(scrapy.Spider):
name = "huya"
allowed_domains = ["www.huya.com"] #设置爬虫允许抓取的
start_urls = ['http://www.huya.com/g'] #设置第一个爬取的url
allow_pagenum = 5 #设置爬取频道的数量
total_pagenum = 0 #计算档前已爬取频道的数量
url_dict={} #设置存放url的dict
def parse(self,response):
parse_content= response.xpath('/html/body/div[3]/div/div/div[2]/ul/li') #抓取当前频道
for i in parse_content:
channel_title = i.xpath('a/p/text()').extract() #抓取频道名称
channel_url = i.xpath('a/@href').extract_first() #抓取当前频道url
channel_id = i.xpath('a/@report').re(r'game_id\D*(.*)\D\}') #抓取当前频道对应的id,用正则去掉不需要部分
channel_data = {"url":channel_url,"channel_id":channel_id[0]} #将频道url和频道id组成一一对应的dict
self.url_dict[channel_title[0]]=channel_data #将频道名称和channel_data添加在url_dict中
if self.total_pagenum <= self.allow_pagenum: #用于控制爬出抓取数量,当total_pagenum小于allow_pagenum 继续爬
self.total_pagenum += 1
yield Request(url=channel_url,meta={'channel_data':channel_data,'channel':channel_title},callback=self.channel_get) #使用request,meta携带数据为频道url,频道id,回调函数为channel_get
def channel_get(self, response):
page_num = int( response.xpath('/html/body/div[3]/div/div/div["js-list-page"]/div[1]/@data-pages').extract_first( ) ) #抓取当前频道一共有多少页,并转为int格式
channel_id = response.meta['channel_data']['channel_id'] #将传入meta的dict(channel_data)中的channel_id值赋给channel_id,该id用于构造url从而实现翻页
channel = response.meta['channel'] #将传入的meta的dict中的channel_id值赋给channel_id
for i in range(1,page_num+1): #根据page_num数量构造"下一页"并继续抓取
url ='http://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId={gameid}&tagAll=0&page={page}'.format(gameid=channel_id,page=i) #获取下一页的json数据
yield Request(url=url,meta={'page':i,'channel':channel},callback=self.channel_parse) #meta携带数据为频道当前页码,频道名称,回调函数为channel_parse
def channel_parse(self, response):
print 'channel_parse start'
count =0 #用于当前房间的位置计算位置
response_json = json.loads(response.text) #利用json.loads将json数据转为字典
channel =response.meta['channel']
for i in response_json['data']['datas']:
count +=1
items=HuyaspiderItem() #实例化item.HuyaspiderItem
items['channel'] = channel #获取频道名称
items['anchor_category'] = i['gameFullName'].replace('/n','') #获取主播类型,并删内容中的换行符
items['watch_num'] = i['totalCount'] #获取观看数量
items['anchor_roomname'] = i['roomName'] #获取房间名称
items['anchor_url'] = 'http://www.huya.com/'+i['privateHost'] #获房间url
items['anchor_name'] = i['nick'] #获主播名称
items['anchor_tag'] = i['recommendTagName'] #获主播推荐标签
items['position'] = str(response.meta['page'])+"-"+str(count) #获取所在频道的位置
yield Request(url=items['anchor_url'],meta={'items':items},callback=self.room_parse) #进入主播房间url获取主播订阅数量,meta携带数据为刚抓取的items,回调函数为room_parse
def room_parse(self,response):
print "room_parse start"
items =response.meta['items']
try:
items['fan_num'] =response.xpath('/html/body/div[2]/div/div/div[1]/div[1]/div[2]/div/div[1]/div[2]/text()').extract() #获取主播订阅数量
except Exception as e:
items['fan_num'] ='none' #如果主播订阅数量为空值则数据则为none
items['crawl_time'] = time.strftime('%Y-%m-%d %X',time.localtime()) #记录爬取时间
yield items #输出items