1.Java集合框架
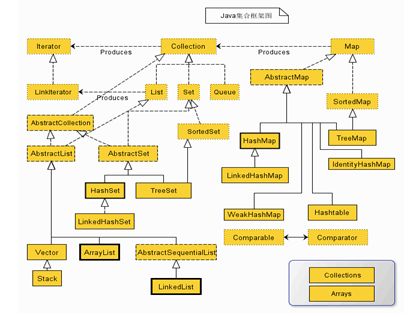
集合类主要分为两大类:Collection和Map。
(1)Collection是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,它主要又分为两大部分:List和Set。
1.List接口通常表示一个列表(数组、队列、链表、栈等),其中的元素可以重复,常用实现类为ArrayList和LinkedList,另外还有不常用的Vector。另外,LinkedList还是实现了Queue接口,因此也可以作为队列使用。
2.Set接口通常表示一个集合,其中的元素不允许重复(通过hashcode和equals函数保证),常用实现类有HashSet和TreeSet,HashSet是通过Map中的HashMap实现的,而TreeSet是通过Map中的TreeMap实现的。另外,TreeSet还实现了SortedSet接口,因此是有序的集合(集合中的元素要实现Comparable接口,并覆写Comparator函数才行)。LinkedHashSet维护的是保持了插入顺序的链接列表。
我们看到,抽象类AbstractCollection、AbstractList和AbstractSet分别实现了Collection、List和Set接口,这就是在Java集合框架中用的很多的适配器设计模式,用这些抽象类去实现接口,在抽象类中实现接口中的若干或全部方法,这样下面的一些类只需直接继承该抽象类,并实现自己需要的方法即可,而不用实现接口中的全部抽象方法。
(2)Map是一个映射接口,其中的每个元素都是一个key-value键值对,同样抽象类AbstractMap通过适配器模式实现了Map接口中的大部分函数,TreeMap、HashMap、WeakHashMap等实现类都通过继承AbstractMap来实现,另外,不常用的HashTable直接实现了Map接口,它和Vector都是JDK1.0就引入的集合类。
(3)Iterator是遍历集合的迭代器(不能遍历Map,只用来遍历Collection),Collection的实现类都实现了iterator()函数,它返回一个Iterator对象,用来遍历集合,ListIterator则专门用来遍历List。而Enumeration则是JDK1.0时引入的,作用与Iterator相同,但它的功能比Iterator要少,它只能再Hashtable、Vector和Stack中使用。
(4)Arrays和Collections是用来操作数组、集合的两个工具类,例如在ArrayList和Vector中大量调用了Arrays.Copyof()方法,而Collections中有很多静态方法可以返回各集合类的synchronized版本,即线程安全的版本,当然了,如果要用线程安全的结合类,首选Concurrent并发包下的对应的集合类。
2.与Java集合框架相关的有哪些最好的实践?
(1)根据需要选择正确的集合类型。比如,如果指定了大小,我们会选用数组而非ArrayList。如果我们想根据插入顺序遍历一个Map,我们需要使用LinkedHashMap。如果我们不想重复,我们应该使用Set。
(2)一些集合类允许指定初始容量,所以如果我们能够估计到存储元素的数量,我们可以使用它,就避免了重新哈希或大小调整。
(3)基于接口编程,而非基于实现编程,它允许我们后来轻易地改变实现。
(4)总是使用类型安全的泛型,避免在运行时出现ClassCastException。
(5)使用JDK提供的不可变类作为Map的key,可以避免自己实现hashCode()和equals()。
(6)尽可能使用Arrays和Collections工具类,而非编写自己的实现。它将会提供代码重用性,它有着更好的稳定性和可维护性。
3.ArrayList和LinkedList的底层实现原理,使用场景
LinkedeList和ArrayList都实现了List接口,但是它们的工作原理却不一样。它们之间最主要的区别在于ArrayList是可改变大小的数组,而LinkedList是双向链表。
LinkedList和ArrayList的差别主要来自于ArrayList和LinkedList数据结构的不同。
1)因为ArrayList是基于索引的数据结构,它使用索引在数组中搜索和读取数据是很快的。ArrayList获取数据的时间复杂度是O(1),但是要删除数据却是开销很大的,因为这需要重排数组中的所有数据。
2)相对于ArrayList,LinkedList插入是更快的。因为LinkedList不像ArrayList一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是ArrayList最坏的一种情况,时间复杂度是O(n),而LinkedList中插入或删除的时间复杂度仅为O(1)。ArrayList在插入数据时还需要更新索引(除了插入数组的尾部)。
3)类似于插入数据,删除数据时,LinkedList也优于ArrayList。
4) LinkedList需要更多的内存,因为ArrayList的每个索引的位置是实际的数据,而LinkedList中的每个节点中存储的是实际的数据和前后节点的位置。
4.ArrayList与Vector的区别
这两个类都实现了List接口(List接口继承了Collection接口),他们都是有序集合,相当于一种动态的数组,我们以后可以按位置索引号取出某个元素,并且其中的数据是允许重复的。ArrayList与Vector的区别,主要包括两个方面:
(1)同步性
Vector是线程安全的,而ArrayList是线程序不安全的。
(2)数据增长
Vector默认增长为原来2倍,而ArrayList的是增长为原来的1.5倍。ArrayList与Vector都可以设置初始的空间大小,Vector还可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法。
5.HashMap详解
HashMap要求映射中的key是不可变对象。不可变对象是该对象在创建后它的哈希值不会被改变。如果对象的哈希值发生变化,Map对象很可能就定位不到映射的位置了。
从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。

Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。threshold就是在此Load factor和length(数组长度)对应下允许的最大元素数目,超过这个数目就重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。
size这个字段其实很好理解,就是HashMap中实际存在的键值对数量。注意和table的长度length、容纳最大键值对数量threshold的区别。而modCount字段主要用来记录HashMap内部结构发生变化的次数,主要用于迭代的快速失败。强调一点,内部结构发生变化指的是结构发生变化,例如put新键值对,但是某个key对应的value值被覆盖不属于结构变化。
因此,length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。
(1)确定哈希桶数组索引位置
Step1:取hashcode值;Step2:高位参与运算;Step3:取模运算
(2)put方法
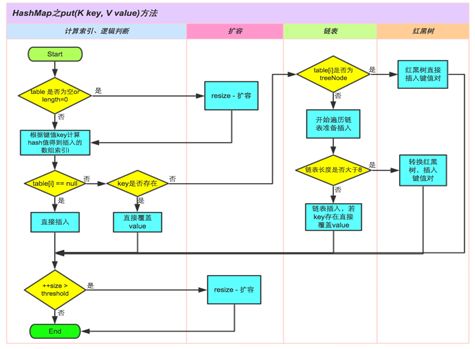
①判断键值对数组table是否为空或为null,则执行resize()进行扩容;
②根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④判断table[i]是否为treeNode,即table[i]是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
(3)扩容机制
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
1 void resize(int newCapacity) {//传入新的容量
2Entry[] oldTable = table;//引用扩容前的Entry数组
3int oldCapacity = oldTable.length;
4if (oldCapacity == MAXIMUM_CAPACITY) {//扩容前的数组大小如果已经达到最大(2^30)了
5threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
6return;
7}
9Entry[] newTable = new Entry[newCapacity];//初始化一个新的Entry数组
10transfer(newTable);//!!将数据转移到新的Entry数组里
11table = newTable;//HashMap的table属性引用新的Entry数组
12threshold = (int)(newCapacity * loadFactor);//修改阈值
13}
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
1 void transfer(Entry[] newTable) {
2Entry[] src = table;//src引用了旧的Entry数组
3int newCapacity = newTable.length;
4for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
5Entry e = src[j];//取得旧Entry数组的每个元素
6if (e != null) {
7src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
8do {
9Entry next = e.next;
10int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
11e.next = newTable[i]; //标记[1]
12newTable[i] = e;//将元素放在数组上
13e = next;//访问下一个Entry链上的元素
14} while (e != null);
15}
16}
17}
6.Hashtable和HashMap的区别
二者的存储结构和解决冲突的方法都是相同的。
(1)HashMap允许key和value为null,而HashTable不允许。
(2)Hashtable是同步的,而HashMap不是。所以HashMap适合单线程环境,Hashtable适合多线程环境。
(3)Hashtable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
为什么HashTable的默认大小和HashMap不一样
Hashtable比较古老,直接使用了除留余数法,那么就需要设置容量起码不是偶数(除(近似)质数求余的分散效果好),而JDK开发者选了11。
HashMap中的length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。
(4)哈希值的使用不同,Hashtable直接使用对象的hashCode。
Hashtable:
inthash = key.hashCode();
intindex= (hash &0x7FFFFFFF) % tab.length;
(5)Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
Hashtable:
intnewCapacity = (oldCapacity <<1) +1;
(6)在Java1.4中引入了LinkedHashMap,HashMap的一个子类,假如你想要遍历顺序,你很容易从HashMap转向LinkedHashMap,但是Hashtable不是这样的,它的顺序是不可预知的。
(7)Hashtable被认为是个遗留的类,如果你寻求在迭代的时候修改Map,你应该使用CocurrentHashMap。
7.HashSet、TreeMap、TreeSet、LinkedHashMap的实现原理
HashSet中不允许有重复元素,这是因为HashSet是基于HashMap实现的,HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个PRESENT。
private static final Object PRESENT = new Object();
HashSet中add方法调用的是底层HashMap中的put()方法,而如果是在HashMap中调用put,首先会判断key是否存在,如果key存在则修改value值,如果key不存在则插入这个key-value。而在set中,因为value值没有用,也就不存在修改value值的说法,这样HashSet中就不存在重复值。
TreeMap的实现使用了红黑树数据结构,也就是一棵自平衡的排序二叉树,这样就可以保证快速检索指定节点。对于TreeMap而言,它采用一种被称为“红黑树”的排序二叉树来保存Map中每个Entry ——每个Entry都被当成“红黑树”的一个节点对待。
TreeSet类似。
LinkedHashMap继承HashMap,此实现与HashMap的不同之处在于,LinkedHashMap维护着一个双向循环链表。此链表定义了迭代顺序,该迭代顺序通常就是将存放元素的顺序。
8.数组中Arrays.sort的排序方法是什么
基本类型:采用调优的快速排序;
对象类型:采用改进的归并排序。
Colletions.sort(list)与Arrays.sort(T[])
Colletions.sort()实际会将list转为数组,然后调用Arrays.sort(),排完了再转回List。
JDK8里,List有自己的sort()方法了,像ArrayList就直接用自己内部的数组来排,而Linked List, CopyOnWriteArrayList还是要复制出一份数组。
