引言
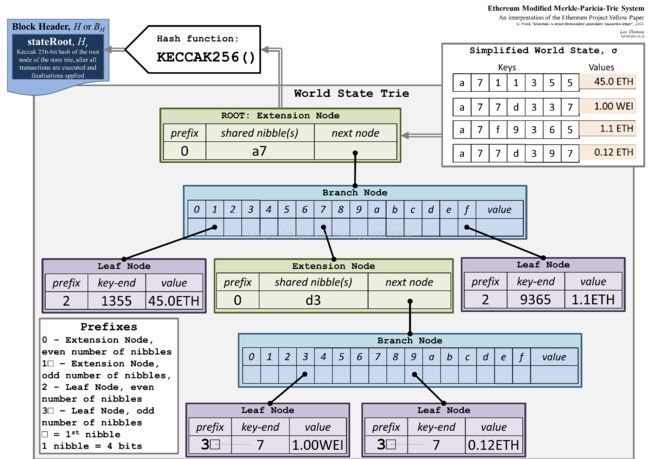
go-etherum的包trie实现了Merkle Patricia Tries,这里用简称MPT来称呼这种数据结构,这种数据结构实际上是一种Trie树变种,MPT是以太坊中一种非常重要的数据结构,用来存储用户账户的状态及其变更、交易信息、交易的收据信息。MPT实际上是三种数据结构的组合,分别是Trie树, Patricia Trie, 和Merkle树。
Trie树 (引用自数据结构之Trie树)
Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树。
Trie树可以利用字符串的公共前缀来节约存储空间。如下图所示,该trie树用10个节点保存了6个字符串:tea,ten,to,in,inn,int:
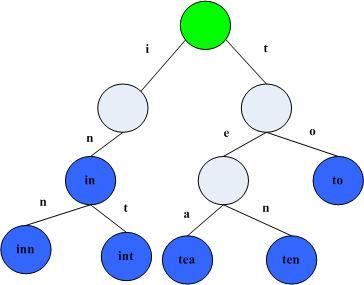
在该trie树中,字符串in,inn和int的公共前缀是“in”,因此可以只存储一份“in”以节省空间。当然,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存,这也是trie树的一个缺点。
Trie树的基本性质可以归纳为:
- 根节点不包含字符,除根节点以外每个节点只包含一个字符。
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符串不相同。
Trie树的优缺点:
缺点:
- 当 hash 函数很好时,Trie树的查找效率会低于哈希搜索。
- 空间消耗比较大。
优点:
- 插入和查询的效率很高,都为O(m),其中 m 是待插入/查询的字符串的长度。
- Trie树中不同的关键字不会产生冲突。
- Trie树只有在允许一个关键字关联多个值的情况下才有类似hash碰撞发生。
- Trie树不用求 hash 值,对短字符串有更快的速度。通常,求hash值也是需要遍历字符串的。
- Trie树可以对关键字按字典序排序。
Patricia 树 (引用自深入浅出以太坊)
Patricia树,或称Patricia trie,或crit bit tree,压缩前缀树,是一种更节省空间的Trie。对于基数树的每个节点,如果该节点是唯一的儿子的话,就和父节点合并。
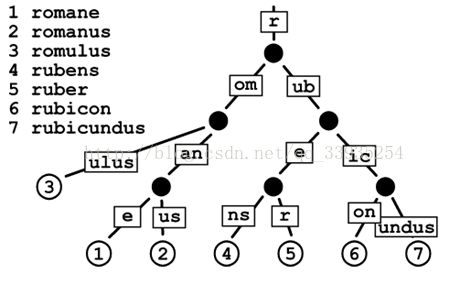
Patricia优缺点:
优点:Patricia Trie相比Trie优点明显,减少了空间的消耗。
缺点:随着后续节点的不断插入和删除,原有节点可能会发生变化,并有可能不断裂变或者合并出新的节点
Merkle 树 (引用自深入浅出以太坊)
Merkle Tree,通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树。Merkle树的叶子是数据块(例如,文件或者文件的集合)的hash值。非叶节点是其对应子节点串联字符串的hash。
要了解Merkle Tree就要先从Hash List说起:
在点对点网络中作数据传输的时候,会同时从多个机器上下载数据,而且很多机器可以认为是不稳定或者不可信的。为了校验数据的完整性,更好的办法是把大的文件分割成小的数据块(例如,把分割成2K为单位的数据块)。这样的好处是,如果小块数据在传输过程中损坏了,那么只要重新下载这一快数据就行了,不用重新下载整个文件。
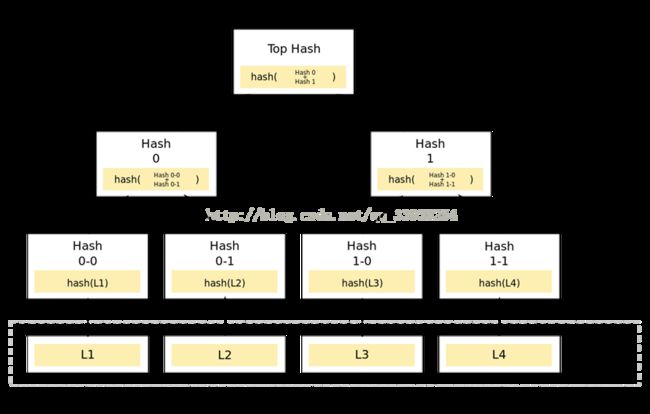
怎么确定小的数据块没有损坏哪?只需要为每个数据块做Hash。BT下载的时候,在下载到真正数据之前,我们会先下载一个Hash列表。那么问题又来了,怎么确定这个Hash列表本身是正确的呢?答案是把每个小块数据的Hash值拼到一起,然后对这个长字符串再做一次Hash运算,这样就得到Hash列表的根Hash(Top Hash or Root Hash)。下载数据的时候,首先从可信的数据源得到正确的根Hash,就可以用它来校验Hash列表了,然后通过校验后的Hash列表校验数据块。
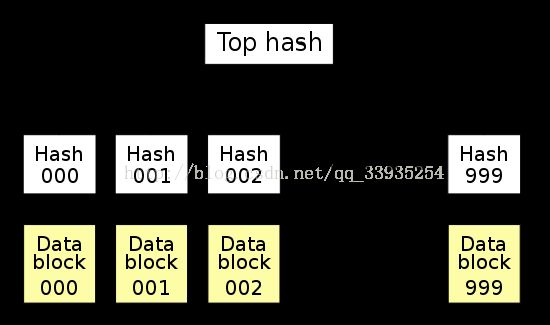
Merkle Tree可以看做Hash List的泛化(Hash List可以看作一种特殊的Merkle Tree,即树高为2的多叉Merkle Tree。
在最底层,和哈希列表一样,我们把数据分成小的数据块,有相应地哈希和它对应。但是往上走,并不是直接去运算根哈希,而是把相邻的两个哈希合并成一个字符串,然后运算这个字符串的哈希,这样每两个哈希就结婚生子,得到了一个”子哈希“。如果最底层的哈希总数是单数,那到最后必然出现一个单身哈希,这种情况就直接对它进行哈希运算,所以也能得到它的子哈希。于是往上推,依然是一样的方式,可以得到数目更少的新一级哈希,最终必然形成一棵倒挂的树,到了树根的这个位置,这一代就剩下一个根哈希了,我们把它叫做 Merkle Root。
在p2p网络下载网络之前,先从可信的源获得文件的Merkle Tree树根。一旦获得了树根,就可以从其他从不可信的源获取Merkle tree。通过可信的树根来检查接受到的MerkleTree。如果Merkle Tree是损坏的或者虚假的,就从其他源获得另一个Merkle Tree,直到获得一个与可信树根匹配的MerkleTree。
Merkle Tree和HashList的主要区别是,可以直接下载并立即验证Merkle Tree的一个分支。因为可以将文件切分成小的数据块,这样如果有一块数据损坏,仅仅重新下载这个数据块就行了。如果文件非常大,那么Merkle tree和Hash list都很到,但是Merkle tree可以一次下载一个分支,然后立即验证这个分支,如果分支验证通过,就可以下载数据了。而Hash list只有下载整个hash list才能验证。
MPT
Trie结构
MPT 是 Ethereum 自定义的 Trie 型数据结构。在代码中,trie.Trie 结构体用来管理一个 MPT 结构,其中每个节点都是行为接口 Node 的实现类。下图是 Trie 结构体和 node 接口族的 UML 关系图:
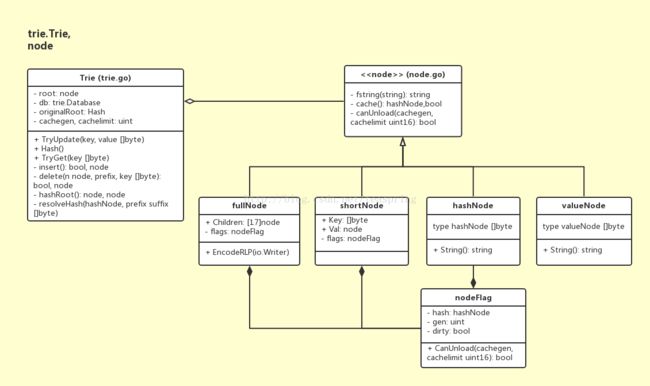
在 Trie 结构体中,成员 root 始终作为整个 MPT 的根节点;
db是后端的KV存储,trie的结构最终都是需要通过KV的形式存储到数据库里面去,然后启动的时候是需要从数据库里面加载的;
originalRoot 的作用是在创建 Trie 对象时承接入参 hashNode,通过这个hash值可以在数据库里面恢复出整颗的trie树;
-
cachegen 是 cache 次数的计数器,每次 Trie 的变动提交后cachegen 自增 1。
cachegen会被附加在node节点上面(node.nodeFlag.gen),默认等于Trie的cachegen。如果Trie每次Commit的时候node有更新,那么Trie的cachegen会重新赋值给node的cachegen。否则node的cachegen将小于Trie的cachegen。
如果当前Trie的cachegen - cachelimit大于node的cachegen,说明trie提交了cachelimit次之后,node一直没有更新。那么node会从cache里面卸载,以便节约内存。 其实这就是缓存更新的LRU算法, 如果一个缓存在多久没有被使用,那么就从缓存里面移除,以节约内存空间。 Trie 结构体提供包括对节点的插入、删除、更新,所有节点改动的提交,以及返回整个 MPT 的哈希值。
node
node 接口族担当整个 MPT 中的各种节点,node 接口分四种实现: fullNode,shortNode,valueNode,hashNode,其中只有 fullNode 和 shortNode 可以带有子节点。
fullNode 是一个可以携带多个子节点的节点。
- 它有一个容量为 17 的 node 数组成员变量 Children
- 数组中前 16 个空位分别对应 16 进制 (hex) 下的 0-9a-f,这样对于每个子节点,根据其 key 值 16 进制形式下的第一位的值,就可挂载到 Children 数组的某个位置,fullNode 本身不再需要额外 key 变量;
- Children 数组的第 17 位,留给该 fullNode 的数据部分。fullNode 明显继承了原生 trie 的特点,而每个父节点最多拥有 16 个分支也包含了基于总体效率的考量。
shortNode 是一个仅有一个子节点的节点。
- 它的成员变量 Val 指向一个子节点,而成员 Key 是一个字节数组[]byte。
- 显然 shortNode 的设计体现了 PatriciaTrie 的特点,通过合并只有一个子节点的父节点和其子节点来缩短 trie 的深度。
valueNode 承载了MPT结构中 真正数据部分的节点。
- 它其实是字节数组 []byte 的一个别名,不带子节点。
- 在使用中,valueNode 就是所携带数据部分的 RLP 哈希值,长度 32byte,数据的 RLP 编码值作为 valueNode 的匹配项存储在数据库里。
这三种类型构成了一个完整的PatriciaTrie结构。何一个[k,v]类型数据被插入一个MPT时,会以k字符串为路径沿着root向下延伸,在此次插入结束时首先成为一个shortNode,k会以自顶点root起到到该节点止的key path形式存在。但之后随着其他节点的不断插入和删除,根据MPT结构的要求,原有节点可能会变化成其他node实现类型,同时MPT中也会不断裂变或者合并出新的节点。
注意:黄皮书中把节点类型概括为了分支节点、扩展节点和叶子节点。fullNode对应了黄皮书里面的分支节点,shortNode对应了黄皮书里面的扩展节点和叶子节点(通过shortNode.Val的类型来对应到底是叶子节点还是分支节点,如果是valueNode,就是叶子节点,否则是分支节点)。
hashNode
hashNode 跟 valueNode 一样,也是字符数组 []byte 的一个别名,同样存放 32byte 的哈希值,也没有子节点。不同的是,hashNode 是 fullNode 或者 shortNode 对象的 RLP 哈希值,所以它跟 valueNode 在使用上有着莫大的不同。
在 MPT 中,hashNode 几乎不会单独存在 (有时遍历遇到一个 hashNode 往往因为原本的 node 被折叠了),而是以 nodeFlag 结构体的成员(nodeFlag.hash) 的形式,被 fullNode 和 shortNode 间接持有。一旦 fullNode 或 shortNode 的成员变量 (包括子结构) 发生任何变化,它们的 hashNode 就一定需要更新。所以在 trie.Trie 结构体的 insert(),delete()等函数实现中,可以看到除了新创建的 fullNode、shortNode,那些子结构有所改变的 fullNode、shortNode 的 nodeFlag 成员也会被重设,hashNode 会被清空。在下次 trie.Hash()调用时,整个 MPT 自底向上的遍历过程中,所有清空的 hashNode 会被重新赋值。这样 trie.Hash()结束后,我们可以得到一个根节点 root 的 hashNode,它就是此时此刻这个 MPT 结构的哈希值。上文中提到的,Block 的成员变量 Root、TxHash、ReceiptHash 的生成,正是源出于此。
明显的,hashNode 体现了 MerkleTree 的特点:每个父节点的哈希值来源于所有子节点哈希值的组合,一个顶点的哈希值能够代表一整个树形结构。
hashNode 加上之前的 fullNode,shortNode,valueNode,构成了一个完整的 Merkle-PatriciaTrie 结构。
一个MPT简单例子: