* Oozie框架基础
官方文档地址:http://oozie.apache.org/docs/4.0.0/DG_QuickStart.html
除Oozie之外,类似的框架还有:
** Zeus:https://github.com/michael8335/zeus2
** Azkaban:https://azkaban.github.io/
感兴趣的朋友可以自行查阅。
Oozie框架简介:
** Oozie单词释义:驯象人
** 一个基于工作流引擎的开源框架,由Cloudera公司贡献给Apache,提供对Hadoop Mapreduce、Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。
** 以xml的形式写调度流程,可以调度mr,pig,hive,shell,jar等。
Oozie主要功能:
** Workflow: 顺序执行流程节点,支持fork(分支多个节点),join(合并多个节点为一个)
** Coordinator,定时触发workflow
** Bundle Job,绑定多个coordinator
Oozie节点:
** 控制流节点(Control Flow Nodes):
控制流节点一般都是定义在工作流开始或者结束的位置,比如start,end,kill等。以及提供工作流的执行路径机制,如decision,fork,join等。
** 动作节点(Action Nodes):
简而不能再简的言之,就是主要就是执行一些动作,比如FS ACTION,可以删除HDFS上的文件,创建文件夹等等等等
接下来我们实际操作感受一下。
* Oozie下载
链接:http://pan.baidu.com/s/1hs85SdI 密码:1bkq
* ext依赖包下载
Oozie的工作依赖于另一个library,ExtJS,WHY?该依赖包主要是提供一个Oozie的界面,如果不需要界面,可以省略。
链接:http://pan.baidu.com/s/1nvv40B3 密码:x5n2
* Oozie部署
(与之前几节内容重复则不再赘述,比如解压,安装之类的)
1、 Hadoop已经成功安装并配置
2、 解压Oozie到指定目录
3、 配置文件
core-site.xml
添加属性:
hadoop.proxyuser.z.hosts:*,即:OOZIE_SERVER_HOSTNAME
hadoop.proxyuser.z.groups:*,即:USER_GROUPS_THAT_ALLOW_IMPERSONATION
如图:

尖叫提示:如果你的集群不是单节点状态,则需要把该core-site.xml文件scp到集群中的其他机器,此处为z02,z03机器。
尖叫提示:你还需要开启mr-jobhistory-daemon.sh服务
4、 如果HDFS已经开启,则需要重启Hadoop的DFS系统
5、解压hadooplibs
$ tar -zxf /opt/modules/cdh/oozie-4.0.0-cdh5.3.6/oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz -C /opt/modules/cdh/
注意,解压之后,你会发现hadooplibs直接在Oozie目录下了,是以内压缩包的根目录结构就是Oozie根目录。
6、在Oozie的根目录下,创建libext/目录
$ mkdir libext/
7、将hadooplibs里面的jar包,拷贝到libext目录下
$ cp -ra /opt/modules/cdh/oozie-4.0.0-cdh5.3.6/hadooplibs/hadooplib-2.5.0-cdh5.3.6.oozie-4.0.0-cdh5.3.6/* libext/
8、将ext-2.2.zip拷贝到libext/目录下
$ cp /opt/softwares/ext-2.2.zip libext/
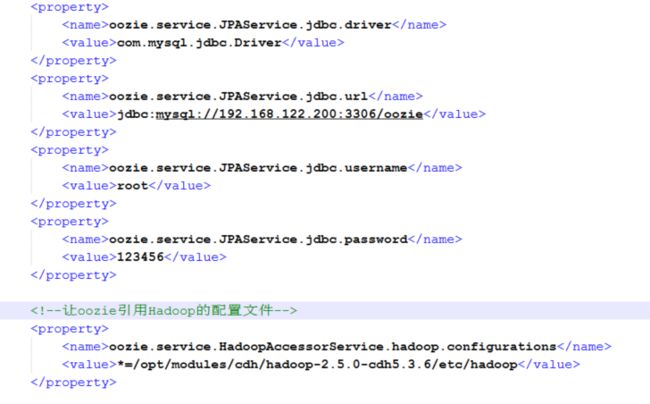
9、修改配置文件
oozie-site.xml,修改如下属性,注意,不是替换,只是修改,如图:
10、由于Oozie需要数据库支持,所以需要安装一个Mysql数据库
由于之前已经安装了Mysql了,此处不再赘述如何安装Mysql。
创建一个oozie数据库,然后把mysql驱动jar拷贝至libext,操作如下:
$ mysql -uroot -p123456
mysql> create database oozie;
exit;
$ cp /opt/modules/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar /opt/modules/cdh/oozie-4.0.0-cdh5.3.6/libext/
11、设置oozie
** 上传oozie目录下的yarn.tar.gz(会自行解压)文件到HDFS
命令如下:
$ bin/oozie-setup.sh sharelib create -fs hdfs://z01:8020 -locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz,执行后如图,注意,该指令一定要在活跃的NameNode节点执行。如果不在,请自行想办法。(方式之前小节已经讲解)

** 创建oozie.sql文件
$ bin/oozie-setup.sh db create -run -sqlfile oozie.sql,如图则成功:

** 打包项目,生成war
$ bin/oozie-setup.sh prepare-war,如图则成功:

** 启动oozie,通过浏览器访问oozie界面
$ bin/oozied.sh start
地址:http://192.168.122.200:11000/oozie,界面如图:

* 案例
例1:oozie调度shell脚本
** 解压oozie根目录下的案例
$ tar -zxf oozie-examples.tar.gz
** 创建自定义任务文件夹,并拷贝任务模板
$ mkdir oozie-apps/
$ cp -r examples/apps/shell/ oozie-apps/
** 创建脚本p1.sh,随便写一个任务啦,如图:

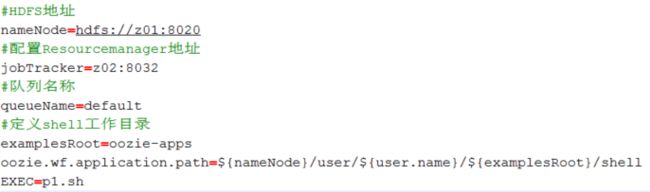
** 修改job.properties和workflow.xml文件
job.properties:
workflow.xml:

** 上传任务配置到HDFS
尖叫提示:任务配置文件每次在本地修改后,如需执行,都需要重新上传到HDFS,因为Oozie不支持本地运行。
上传:
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put /opt/modules/cdh/oozie-4.0.0-cdh5.3.6/oozie-apps/ /user/z/
** 提交执行该任务
$ bin/oozie job -oozie http://z01:11000/oozie -config oozie-apps/shell/job.properties -run,在Oozie界面可以看到:

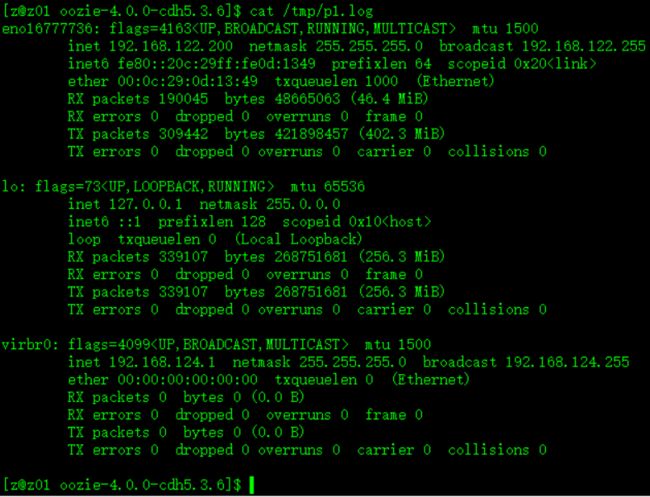
查看tmp目录下生成的p1.log文件如下:
尖叫提示:
现象:你执行了某个任务,通过shell脚本向本地tmp目录下写.log文件,然后,找不到?
原因:排除你任务执行失败之外,看一看你的其他机器对应目录是否有.log文件生成?
解释:因为shell脚本执行为当前机器节点,所以在resourcemanager调度任务给某一个NodeManager
执行时,该.log日志文件的生成会在任务执行所在的NodeManager节点上生成。
** 杀掉某个任务
当任务卡死或者无效,可以选择杀死该任务
$ bin/oozie job -oozie http://z01:11000/oozie -kill 0000004-170425105153692-oozie-z-W
例2:执行多个Job调度
** 创建两个shell脚本
此处我直接利用刚才的p1.sh复制出来一个p2.sh
$ cp -a oozie-apps/shell/p1.sh oozie-apps/shell/p2.sh
改变p2.sh如图:

对应的配置文件,修改如图所示:
job.properties:
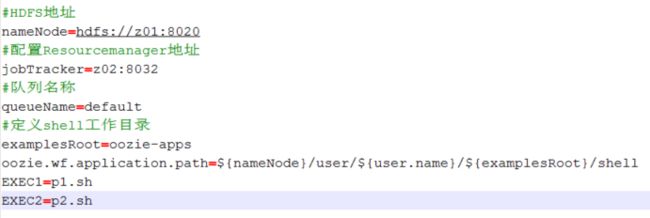
workflow.xml:
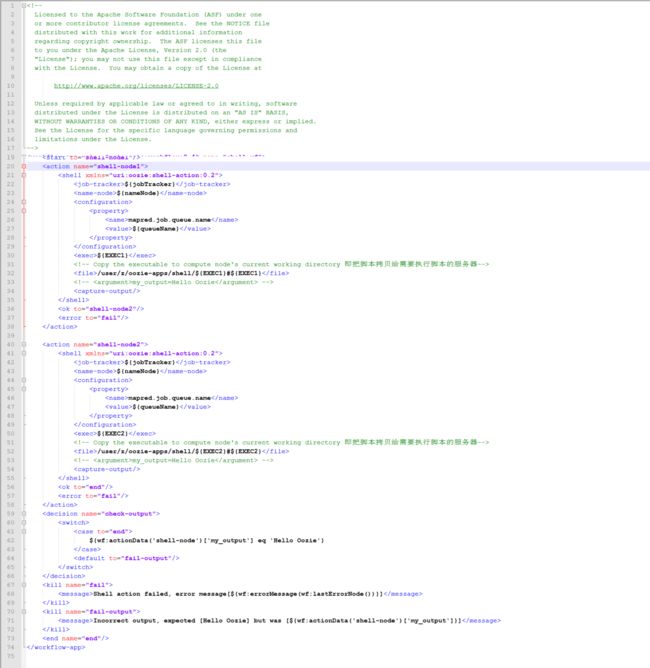
** 上传后,执行该任务,不再赘述。该任务流程为:先执行action1,如果action1成功,则执行action2,然后结束,否则直接结束。
此处可以看到,运行结果:
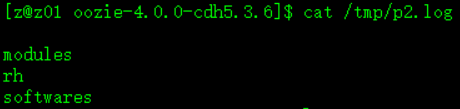
尖叫提示:重新上传前,需要先删除HDFS中的oozie-apps文件夹
例3:调度mapreduce任务
** 首先拷贝示例模板
$ cp -r examples/apps/map-reduce/ oozie-apps/
** 删除map-reduce/lib目录下示例的jar包,一会存放自己的jar
$ rm -rf oozie-apps/map-reduce/lib/*
** 在DFS系统中创建input文件夹并传入words.txt文件,然后运行测试前几节我们打包好的Jar包,即单词统计任务(这一步在之前的HDFS讲解中重复很多遍了,所以不在赘述)
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -mkdir /input/
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put /opt/modules/hadoop-2.5.0/words.txt /input/
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar /opt/modules/hadoop-2.5.0/MyWordCount.jar /input/ /output/
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -cat /output/par*,一顿操作后,结果如图:

** 配置文件
job.properties:

workflow.xml:
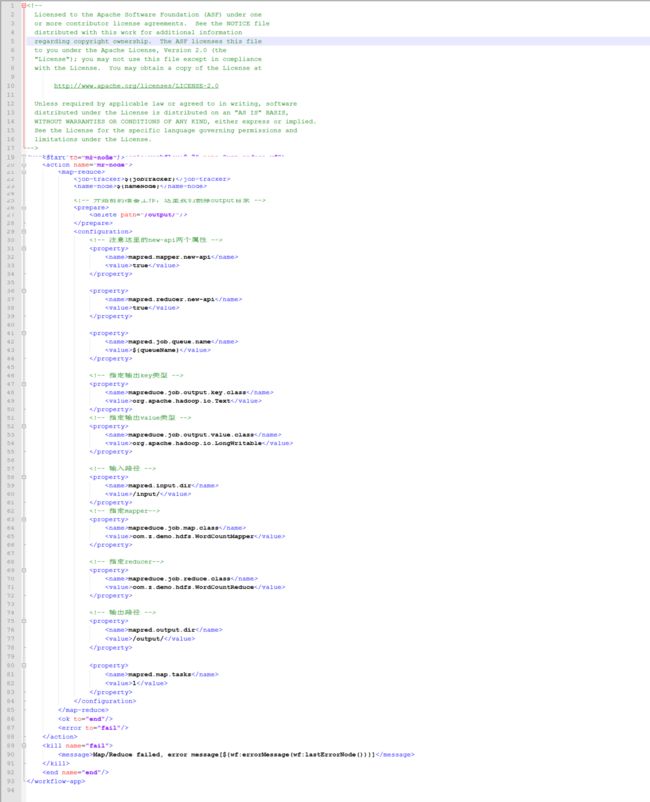
注意,配置workflow.xml文件时,里面的property属性需要结合具体情况配置,比如我刚才已经运行了一个MyWordCount任务了,我可以通过yarn平台的界面来查找相关属性,打开8088端口界面,找到刚才运行的任务,点击history:

然后出现如下界面,点击Configuration:
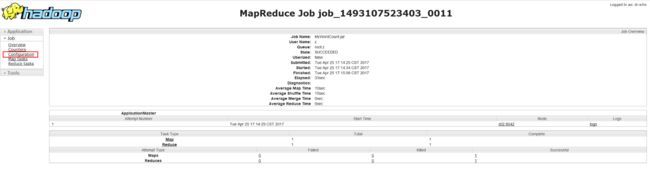
然后在右上角搜索api这个关键字:

绿色框体中的内容即为属性名,蓝色窗体即为属性值,大家自己对应查找即可,然后完成workflow.xml文件的配置。
** 拷贝MyWordCount.jar到oozie-apps/map-reduce/lib目录下
这里根据我的情况,我之前的MyWordCount.jar包存放于另外一个hadoop目录下了,所以:
$ cp -a /opt/modules/hadoop-2.5.0/MyWordCount.jar oozie-apps/map-reduce/lib/
** 上传map-reduce目录到HDFS的oozie-apps目录
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put oozie-apps/map-reduce/ /user/z/oozie-apps/
** 运行任务
$ bin/oozie job -oozie http://z01:11000/oozie -config oozie-apps/map-reduce/job.properties -run,成功结果如图:
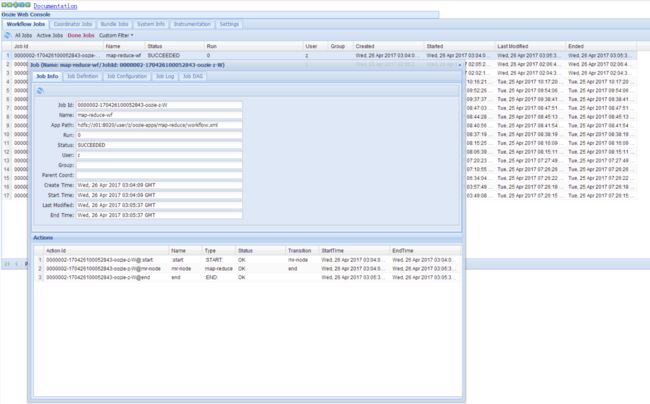

例4:使用Coordinator周期性调度任务
** 配置时区
如图:+0800是东八区区时,如果不是此时区,查询如何修改时区,在此不赘述。
** 修改oozie-site.xml文件
添加如下属性,该属性可以去oozie-default.xml文件中查找

** 修改oozie-console.js文件中的时区设定
$ cat /opt/modules/cdh/oozie-4.0.0-cdh5.3.6/oozie-server/webapps/oozie/oozie-console.js,搜索TimeZone函数,修改为如下:

** 重启oozie,并清除浏览器缓存,不放心的话,可以换另一个浏览器打开即可
$ bin/oozied.sh stop
$ bin/oozied.sh start
** 拷贝coordinator周期任务模板
首先,还是先去examples里面拷贝个任务配置模板出来
$ cp -r examples/apps/cron/ oozie-apps/
** 修改job.properties、coordinator.xml文件,workflow文件就用案例1的即可。
由于我打算让coordinator来调度案例1的workflow任务,所以,先把案例1的workflow.xml复制到cron目录下。
$ cp oozie-apps/shell/workflow.xml oozie-apps/cron/
当然了,还有那个具体的脚本p1.sh和p2.sh
$ cp oozie-apps/shell/p1.sh oozie-apps/shell/p2.sh oozie-apps/cron/
然后修改job.properties文件:

然后修改coordinator.xml文件:
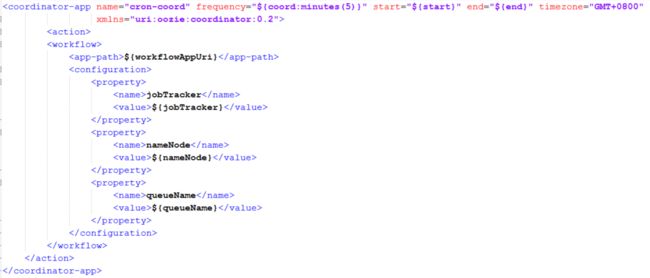
修改内容:frequency修改为5分钟执行一次,时区修改为GMT+0800,注意,coordinator执行频率最小为5分钟一次。
** 运行测试
先上传cron目录到HDFS
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put oozie-apps/cron/ /user/z/oozie-apps/
$ bin/oozie job -oozie http://z01:11000/oozie -config oozie-apps/cron/job.properties -run
请自行观察其5分钟执行一次,执行到明天结束。

* 总结
oozie调度框架的学习,如果概念不了解,可以先在似懂非懂的状态下把例子学会,再回顾知识点,自然就理解了。
IT全栈公众号:

QQ大数据技术交流群(广告勿入):476966007

下一节:Hue搭配基础