源码:https://github.com/ltoddy/rabbitmq-tutorial
工作队列

(using the Pika Python client)
本章节教程重点介绍的内容
在第一篇教程中,我们编写了用于从命名队列发送和接收消息的程序。在这一个中,我们将创建一个工作队列,用于在多个工作人员之间分配耗时的任务。
工作队列(又名:任务队列)背后的主要思想是避免立即执行资源密集型任务,并且必须等待它完成。相反,我们安排稍后完成任务。我们将任务封装 为消息并将其发送到队列。
在后台运行的工作进程将弹出任务并最终执行作业。当你运行许多工人时,任务将在他们之间共享。
这个概念在Web应用程序中特别有用,因为在短的HTTP请求窗口中无法处理复杂的任务。
在本教程的前一部分中,我们发送了一条包含“Hello World!”的消息。现在我们将发送代表复杂任务的字符串。
我们没有真实世界的任务,比如要调整大小的图像或要渲染的PDF文件,所以让我们假装我们很忙 - 使用 time.sleep() 函数来伪装它。
我们将把字符串中的点(".")数作为复杂度; 每一个点都会占用一秒的“工作”。例如,Hello ... 描述的假任务将需要三秒钟。
我们稍微修改前面例子中的send.py代码,以允许从命令行发送任意消息。这个程序将把任务安排到我们的工作队列中,所以让我们把它命名为new_task.py:
import sys
message = ' '.join(sys.argv[1:]) or 'Hello World'
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print(" [x] Sent %r" % message)
我们的旧版receive.py脚本也需要进行一些更改:它需要为邮件正文中的每个点伪造第二个工作。它会从队列中弹出消息并执行任务,所以我们称之为worker.py:
import time
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
循环调度
使用任务队列的优点之一是可以轻松地平行工作。如果我们正在积累积压的工作,我们可以增加更多的工作人员,并且这种方式很容易扩展。
首先,我们试着同时运行两个worker.py脚本。他们都会从队列中获取消息,但具体到底是什么?让我们来看看。
您需要打开三个控制台。两个将运行worker.py脚本。这些控制台将成为我们的两个消费者 - C1和C2。
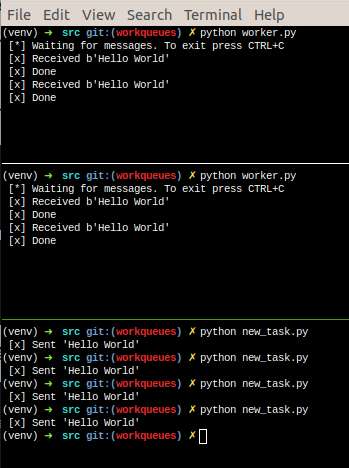
默认情况下,RabbitMQ将按顺序将每条消息发送给下一个使用者。平均而言,每个消费者将获得相同数量的消息。这种分配消息的方式称为循环法。请尝试与三名或更多的工人。
消息确认
做任务可能需要几秒钟的时间。你可能想知道如果其中一个消费者开始一项长期任务并且只是部分完成而死亡会发生什么。
用我们目前的代码,一旦RabbitMQ将消息传递给客户,它立即将其标记为删除。在这种情况下,如果你杀了一个工人,我们将失去刚刚处理的信息。
我们也会失去所有派发给这个特定工作人员但尚未处理的消息。
但我们不想失去任何任务。如果一名工人死亡,我们希望将任务交付给另一名工人。
为了确保消息永不丢失,RabbitMQ支持消息确认。消费者发回ack(请求)告诉RabbitMQ已经收到,处理了特定的消息,并且RabbitMQ可以自由删除它。
如果消费者死亡(其通道关闭,连接关闭或TCP连接丢失),RabbitMQ将理解消息未被完全处理,并将重新排队。如果有其他消费者同时在线,它会迅速将其重新发送给另一位消费者。
这样,即使工作人员偶尔死亡,也可以确保没有任何信息丢失。
没有任何消息超时; 当消费者死亡时,RabbitMQ将重新传递消息。即使处理消息需要非常很长的时间也没关系。
消息确认默认是被打开的。在前面的例子中,我们通过 no_ack = True 标志明确地将它们关闭。一旦我们完成了一项任务,现在是时候清除这个标志并且发送工人的正确确认。
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
使用这段代码,我们可以确定,即使在处理消息时使用CTRL + C来杀死一个工作者,也不会丢失任何东西。工人死后不久,所有未确认的消息将被重新发送。
消息持久性
我们已经学会了如何确保即使消费者死亡,任务也不会丢失。但是如果RabbitMQ服务器停止,我们的任务仍然会丢失。
当RabbitMQ退出或崩溃时,它会忘记队列和消息,除非您告诉它不要。需要做两件事来确保消息不会丢失:我们需要将队列和消息标记为持久。
首先,我们需要确保RabbitMQ永远不会失去我们的队列。为了做到这一点,我们需要宣布它是持久的:
channel.queue_declare(queue='hello', durable=True)
虽然这个命令本身是正确的,但它在我们的设置中不起作用。那是因为我们已经定义了一个名为hello的队列 ,这个队列并不"耐用"。
RabbitMQ不允许您使用不同的参数重新定义现有的队列,并会向任何试图执行该操作的程序返回错误。
但是有一个快速的解决方法 - 让我们声明一个具有不同名称的队列,例如task_queue:
channel.queue_declare(queue='task_queue', durable=True)
此queue_declare更改需要应用于生产者和消费者代码。
此时我们确信,即使RabbitMQ重新启动,task_queue队列也不会丢失。现在我们需要将消息标记为持久 - 通过提供值为2的delivery_mode属性。
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # 确保消息是持久的
))
公平派遣
您可能已经注意到调度仍然无法完全按照我们的要求工作。例如,在有两名工人的情况下,当所有奇怪的信息都很重,甚至信息很少时,一名工作人员会一直很忙,
另一名工作人员几乎不会做任何工作。那么,RabbitMQ不知道任何有关这一点,并仍将均匀地发送消息。
发生这种情况是因为RabbitMQ只在消息进入队列时调度消息。它没有考虑消费者未确认消息的数量。它只是盲目地将第n条消息分发给第n位消费者。

为了解决这个问题,我们可以使用basic.qos方法和设置prefetch_count = 1。这告诉RabbitMQ一次不要向工作人员发送多个消息。
或者换句话说,不要向工作人员发送新消息,直到它处理并确认了前一个消息。相反,它会将其分派给不是仍然忙碌的下一个工作人员。
channel.basic_qos(prefetch_count=1)
把它放在一起
我们的new_task.py脚本的最终代码:
#!/usr/bin/env python
import sys
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or 'Hello World'
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # 确保消息是持久的
))
print(" [x] Sent %r" % message)
connection.close()
而我们的工人 worker.py:
#!/usr/bin/env python
import time
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
channel.basic_qos(prefetch_count=1)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
使用消息确认和prefetch_count,您可以设置一个工作队列。即使RabbitMQ重新启动,持久性选项也可让任务继续存在。