到目前为止,R语言的数据操作和基础绘图部分已经讲解完毕,换句话说,大家应该已经能将数据导入R中,并运用各种函数处理数据使其成为可用的格式,然后将数据用各种基础图形展示。完成前面这些步骤之后,我们接下来要探索数据中变量的分布以及各组变量之间的关系。
在课题或者项目中,你往往会遇到这样的问题:参与本次实验的病人的年龄的分布如何(均值、、标准差、中位数等)?实验中不同组病人的生存时间有没有差异?病人性别对实验结果有无影响?接下来的几次教程内容就是为了解决这些问题,我们会逐步学习R语言中的一些统计方法,希望大家在学习新内容的同事,也可以回顾一下自己之前学过的统计学课程。本次教程将主要关注R语言中生成基本的描述性统计量和推断统计量的R函数。
写在开篇的话,本篇教程内容较多,请务必静下心来学习。
温馨提示
1、本节内容重点内容较多,
务必紧跟红色标记。
2、测试数据及代码
见文末客服小姐姐二维码。
1、连续型变量的统计描述
生成描述性统计量的R函数中,连续型变量和类别型变量的统计方法有所不同,首先介绍连续型变量的统计函数(以R中自带的mtcars数据集为例),summary()是R中基础安装的获取描述性统计量的函数。函数summary()提供了最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计。其中典型函数还有mean()、sd()、var()、min()、max()、median()、length()、range()和quantile()。同时,函数fivenum()可返回图基五数总括(Tukey`s five-number summary,即最小值、下四分位数、中位数、上四分位数和最大值)。(上述函数的使用比较基础,就不一一举例了。)不过,R基础安装中没有提供偏度和峰度的计算函数,下面是一个自定义计算偏度和峰度的函数实例。
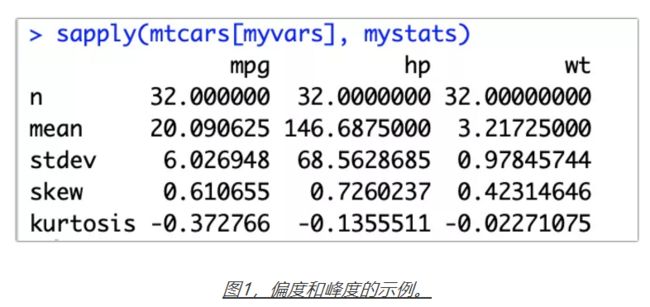
图1中,函数mystats()是自定义的函数(用于计算图中所示的五个描述性统计量),函数sapply()和函数apply()使用类似,在之前的教程中介绍过。(具体代码见后台。)
当然,除了基础安装,还有很多获取描述性统计量的方法。比如:Hmisc包中的describe()函数、pastecs包中的stat.desc()函数和psych包也拥有的describe()的函数。这里我们给出Hmisc包的例子:(两个包中的函数名称重复时,在函数名前面加上包名称即可,如Hmisc::describe())。

2、"分组"连续型变量的统计描述
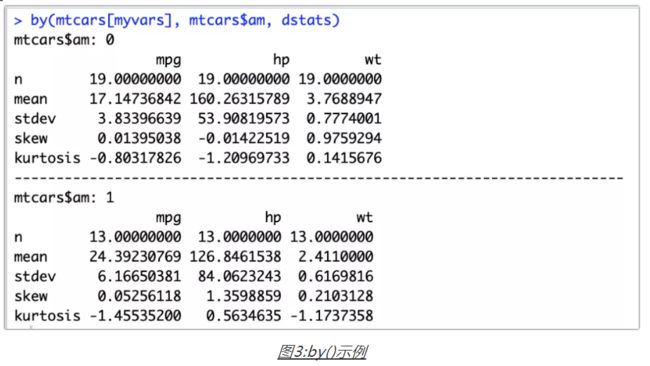
上面介绍了获取整体数据的描述性统计量的方法,更多时候我们需要将数据分组后分别计算各组的描述性统计量,函数by()或者aggregate()可以解决这个难题。下面是函数by()的一个例子,以变量am为分类标准,分别计算两组的描述性统计量。其中函数dstats()是在函数mystats()基础上定义的。
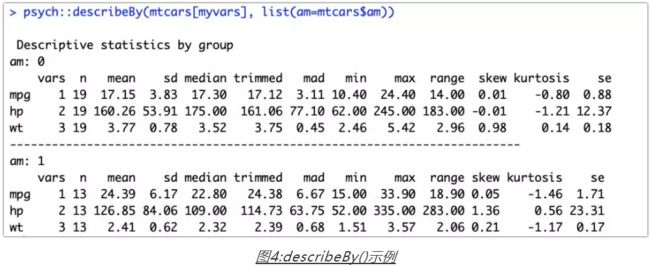
当然也有很多函数包提供了分组计算描述性统计量的方法。比如:doBy包中summaryBy()函数、psych包中的describeBy()函数。下面是psych包中的describeBy()的示例:
描述性统计量的计算是很基础的分析步骤,R中用于获取描述性统计量的方法很多,大家可以根据自己的需要或者喜好选择,或者你还可以自己写一个函数出来!
3、分类变量的统计描述
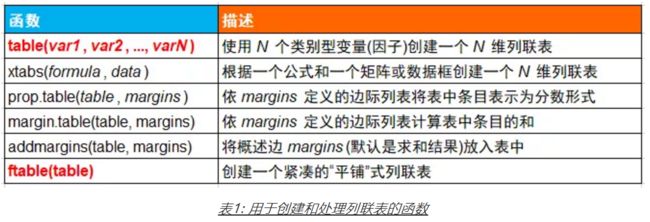
对于连续型变量,我们可以计算均值、标准差等,那么对于类别型变量该怎么办呢?频数表和列联表可以解决这个问题。(示例数据来自vcd包中的Arthritis数据集。)创建频数表和列联表的几种重要方法如下表:
具体的示例代码可以直接找客服胖雨小姐姐要(文末二维码),就不在这里一一展示了。使用gmodels包中的CrossTable()函数也是创建二维列联表的一种方法,示例如下图5.
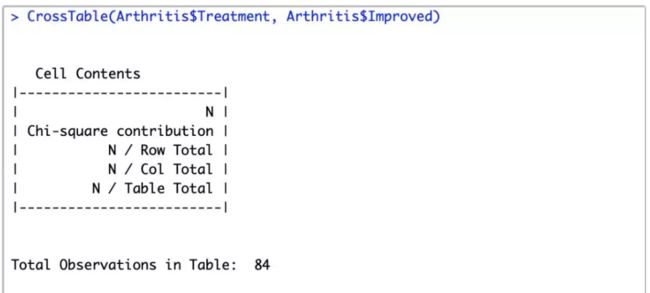
函数CrossTable()有很多选项,可以做许多事情:计算(行、列、单元格)的百分比;指定小数位数;进行卡方、Fisher和McNemar独立性检验;计算期望和(皮尔逊、标准化、调整的标准化)残差;将缺失值作为一种有效值;进行行和列标题的标注;生成SAS或SPSS风格的输出。参阅help(CrossTable)以了解详情。
当有两个以上的类别变量时,就需要生成多维列联表,table() 和 xtabs() 都 可 以 基 于 三 个 或 更 多 的 类 别 型 变 量 生 成 多 维 列 联 表 。表1中其它函数也都可以依次推广到多维的情形(考虑篇幅有限,代码见文末客服二维码)。
4、连续型变量的相关性检验
连续型变量中的相关性可以用相关系数来描述,相关系数的符号(±)表明关系的方向(正相 关或负相关),其值的大小表示关系的强弱程度(完全不相关时为0,完全相关时为1)。(示例数据来自于R基础安装中的state.x77数据集)。R可以计算多种相关系数,包括Pearson相关系数、Spearman相关系数、Kendall相关系数、偏相关系数、多分格(polychoric)相关系数和多系列(polyserial)相关系数。cor()函数可以计算Pearson、Spearman、Kendall这三种相关系数,而cov()函数可用来计算协方差。这两个函数中的use参数用来指定处理缺失数据的方式,method参数用来指定相关系数的类型。
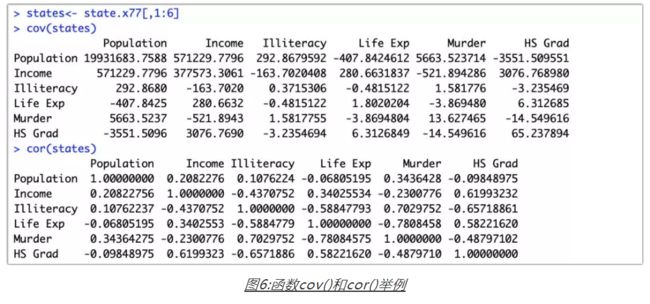
从上面的例子可以看出对角线上的相关系数都是1(变量和自身的相关性显然为1),收入(income)和高中毕业率(HS Grad)相关性很强(0.61993232)。
而偏相关是指在控制一个或多个定量变量时,另外两个定量变量之间的相互关系。你可以使用 ggm包中的pcor()函数计算偏相关系数。函数pcor()的参数为一个数值向量,前两个数值表示要计算相关系数的变量下标,其余的数值为条件变量(即要排除影响的变量)的下标,参数S为变量的协方差阵。

最后,polycor包中的hetcor()函数可以计算一种混合的相关矩阵,其中包括数值型变量的Pearson积差相关系数、数值型变量和有序变量之间的多系列相关系数、有序变量之间的多分格相关系数以及二分变量之间的四分相关系数。多系列、多分格和四分相关系数都假设有序变量或二分变量由潜在的正态分布导出。请参考此程序包所附文档以了解更多。
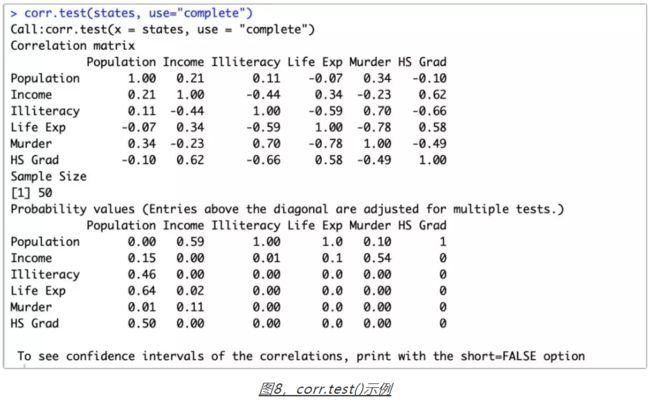
在计算好相关系数以后,如何对它们进行统计显著性检验呢? 函数cor.test()可以对单个的Pearson、Spearman和Kendall相关系数进行检验。其中的参数x和参数y为要检验相关性的变量,参数alternative则用来指定进行双侧检验或单侧检验(取值为"two.side"、"less"或"greater"),而参数method用以指定要计算的相关类型("pearson"、" kendall"或"spearman" )。当研究的假设为总体的相关系数小于0时,使用alternative="less"。在研究的假设为总体的相关系数大于0时,应使用alternative="greater"。在默认情况下,假设为alternative="two.side"(总体相关系数不等于0)。cor.test()每次只能检验一种相关关系。但幸运的是,psych包中提供的corr.test()函数可以一次做更多事情,并且用法类似。psych包中的pcor.test()函数可以用于偏相关性系数的显著性检验。另外,psych包中的r.test()函数提供了多种实用的显著性检验方法。
5、分类变量的相关性检验
列联表可以告诉你组成表格的各种变量组合的频数或比例,不过你可能还会对列联表中的变量是否相关或独立感兴趣。R提供了多种检验类别型变量独立性的方法,接下来给大家介绍的三种检验分别为卡方独立性检验、 Fisher精确检验和Cochran-Mantel-Haenszel检验。
图6是用chisq.test()对示例数据做的卡方检验示例,说明了治疗效果和性别是否独立。但是下面的warning message是怎么回事呢?因为在表中一个有一个小于5的值, 这可能会使卡方近似无效。

可以使用fisher.test()函数进行Fisher精确检验来解决卡方检验无效的问题。

那么这里治疗效果和性别是否独立呢?mantelhaen.test()函数可用来进行Cochran-Mantel-Haenszel卡方检验,其原假设是,两个名义变量在第三个变量的每一层中都是条件独立的。用法和之前的两个函数完全类似。

从上面的独立性检验结果可以看出我们关注的变量之间并不独立,那自然可以考虑检查变量之间的相关性。对于类别型变量,vcd包中提供了函数assocstats()用来计算二维列联表的phi系数、列联系数和Cramer’s V系数(由于用法与前面三个函数太类似,不再赘述)。
6、连续型变量的比较检验
变量之间的关系除了独立性、相关性之外,还可以进行比较,对于符合正态分布的连续型变量组间比较,我们一般采用t检验(示例数据为MASS包中的UScrime数据集)。T检验的函数为t.test(),有两种调用格式:
t.test(y~x, data) 其中的y是一个数值型变量,x是一个二分变量。
t.test(y1, y2) 其中的y1和y2为数值型向量(即各组的结果变量)。
从下面的图12,大家能不能看出group 0和group 1比较的结论呢?
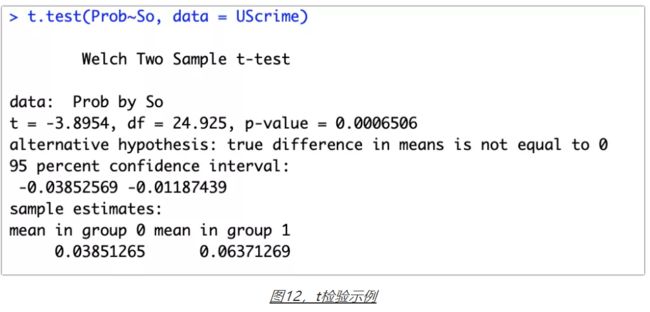
函数t.test()也可以利用参数进行有方向的检验,不妨查看一下帮助文档。
上面的例子是对于两组独立样本的t检验,如果是非独立样本,将函数t.test()的参数paired设置为TRUE即可。如果是多于两组的比较,需要用到方差分析,我们下一次再讨论这部分内容。
当变量明显不符合t检验或者方差分析的条件(比如非正态分布或者呈现有序关系),我们可以用非参数检验。若两组数据独立,可以使用Wilcoxon秩和检验。函数wilcox.test()就派上用场了。用非参数检验重复一下前面图12中的比较。该函数调用方式与t.test()类似。这次的结论是否和图12的结论一致呢?

有没有多于两组的非参数检验方法呢,答案是肯定的,如果各组独立,则Kruskal-Wallis检验(函数kruskal.test())将是一种实用的方法。如果各组不独立(如重复测量设计或随机区组设计),那么Friedman检验(函数friedman.test())会更合适。(示例数据来自于R基础安装中的state.x77数据集。)

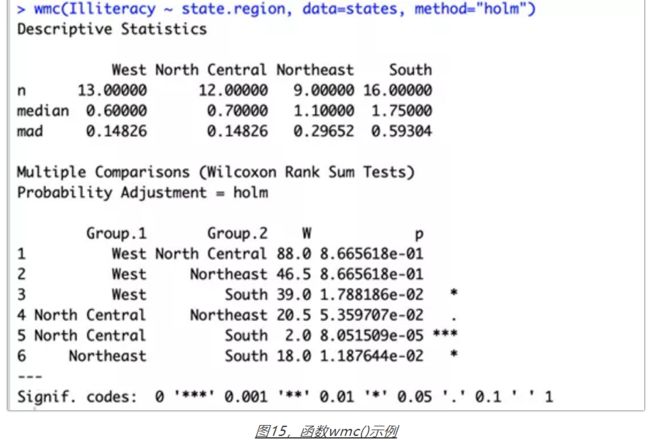
如果要回答多组间的差异的细节,这里有一个来自于网络的文件wmc.txt,包含了函数wmc(),可以解决这个难题(已经下载好放在后台)。结果如下。
小结
这次的课程内容可以说是目前整个《R语言从入门到精通》系列课程中内容最多的一篇,而且涉及统计,理解上难度也比较大。希望大家能够认真看,认真练,不要辜负老师的一番苦心啊~ 还是那句话:编程是不会把电脑编坏的,不要把电脑当作娇花嫩草,多上手多练习才能记忆深刻。还在坚持学习的各位,要加油哦~

本期干货
!R语言统计入门代码大全 !
关注“科研猫”公众号,联系客服
胖雨 or 折耳猫小姐姐 领取资料
讲师简介
上海交通大学硕士,MIT博士,长期从事医学与生物信息学研究,主要研究方向为高通量测序在肿瘤早期筛查和无创产前诊断中的临床应用,独立开发多个数据分析软件并发表相关文章(影响因子≥5分6篇,≥10分2篇),熟知R、Python、Perl及C语言等多种编程语言及程序设计,曾累计书写R代码超过5万余行。
下期推文预告
R语言统计-方差分析(ANOVA)
往期干货链接
R语言从入门到精通系列
从今天开始,每天学点R语言~
R语言从入门到精通:Day1
R语言从入门到精通:Day2
R语言从入门到精通:Day3
R语言从入门到精通:Day4
R语言从入门到精通:Day5
R语言从入门到精通:Day6
R语言从入门到精通:Day7
R语言从入门到精通:Day8
R语言从入门到精通:Day9
科研作图系列
【科研猫·绘图】今夏最热的“热图”(带R代码分享)
【科研猫·绘图】看·箱线图·如何美丽动人(代码分享)
【科研猫·绘图】优雅版·小提琴图(带R代码分享)
【科研猫·绘图】缤纷版·韦恩图(带R代码分享)
【科研猫·绘图】朋友圈最火热的“火山图”(带R代码分享)
【科研猫·绘图】bar(霸)图绘制之霸气满屏
【科研猫·绘图】GSEA分析全攻略,带视频分享
网络图
从网络图探寻基因互作的蛛丝马迹(1)
【科研猫·绘图】从网络图探寻基因互作的蛛丝马迹(2)
从网络图探寻基因互作的蛛丝马迹(3)
从网络图探寻基因互作的蛛丝马迹(4)
从网络图探寻基因互作的蛛丝马迹(5)
生存分析系列
【科研猫】生存分析的正确姿势(1)视频+R代码分享
【科研猫·出品】TCGA超大批量生存分析教程
GEO数据挖掘系列
GEO数据库挖掘(1)--SCI文章速成
GEO数据库挖掘(2)--快速锁定目标数据
挖掘GEO速成SCI文章系列教程(3)-R语言基础
重磅:GEO数据库挖掘教程(4)一体化分析代码(带视频+R代码分享)
GO/KEGG功能富集系列
3分钟了解GO/KEGG功能富集分析
干货预警:3分钟搞定GO/KEGG功能富集分析(2)
终极篇:3分钟搞定GO/KEGG功能富集分析-柱状图
终极篇:3分钟搞定GO/KEGG功能富集分析-气泡图
TCGA数据挖掘系列
隔壁实验室的“秃鹫”师兄又发SCI啦--TCGA数据挖掘实战
TCGA数据挖掘终结者:cBioPortal
生物信息入门系列
大咖聊“生信”—生物信息系列(1)
生物信息系列课程-R语言入门
更多科研新鲜资讯、文献精读和生物信息技能,请关注科研猫公众号
下方点好看,更多好看。