分布式缓存概念已经出现很久了,目前也有很多经典的应用,比如Memcached, Redis和笔者工作中用到的Infinispan。其背后的实现原理是怎么样的?例如:对象是如何分配到多个节点的?如果增加或删除一个节点,已有的缓存数据要重新排列吗?笔者带着这些问题查找资料后形成此文。
此文包括以下3个部分:
1. 为什么要用分布式缓存
2. 分布式缓存依赖的算法
3. Infinispan对分布式缓存实现
一,为什么要用分布式缓存
要回答为什么用分布式缓存之前,要回答为什么要缓存?缓存的目的是通过数据放入内存加快数据访问速度,并且降低对瓶颈资源的访问压力。为什么要用分布式缓存呢?当缓存不够用时,需要增大缓存,其中一个方向是增加内存条,但是受制于主板和CPU等硬件的限制,增加内存条必然是有限的。另一个方向就是分布式缓存,即把缓存分布到多台机器上,缓存容量和节点数量呈线性关系增长。
二,分布式缓存依赖的算法
既然数据存到多台机器上,那么怎么合理均匀地讲数据分布到多台机器呢?一个直观的思路是类似Hashtable的算法,每个节点作为一个hash槽,按照对象的Hash code对节点取余数,然后存入或获取相应的节点。简短描述如下:
Hash(o) mod n
- o 是数据对象
- n 是节点数量
举个例子,假设Hash code为1-12这12个数字,存放到4个节点。如果按照上述算法,余数分别是0,1,2,3. 存储结构如下图所示:

存取和数据分布都很完美,但是当一台机器坏了的话,问题就来了。4个节点变成3个节点。按理应该对3取余数,存储结构变成下图所示:

旧节点上的数据几乎全部都失效,意味着需要重新转移数据,当存放数据的数据量很大,转移数据会用很好时间,在此期间,应用无法使用缓存,对应用的影响就很大。如果有一种算法能够达到下图所示,那么就完美了,即正常节点上的数据不动,后续把坏节点的数据均匀地缓存到正常节点上。还有个前提,存在一种算法,保证缓存的对象能正确地获取:

可惜,事实证明,按照旧的取余数思路无法达到上述效果。
于是为解决分布式问题的另一种算法出现了:Consistent hashing,中文名一致性哈希。
看看Consistent hashing描述:
当hashtable变化时,只有K / n 个数据需要重排。 K是数据的总数,n是Hash 槽的数量。
对照上面的例子,恰好12/4=3个节点需要重排。
顺便说一下,它是MIT的Karger教授在1997年发明的。那么它在技术上是如何实现的呢?
1,将真实的机器节点名虚拟成多个虚拟节点。例如节点A,虚拟为A1,A2,A3,A4等。
2,对数据和虚拟节点都按照某Hash方法取得Hash code。
3,将Hash槽安排成一个0 到 2的32次方-1的环。
4,按照第2步中的数据和虚拟节点。按照Hash code值安排到第3步的Hash槽上。
举例:有A,B,C三个物理节点,分别虚拟为4个虚拟节点。缓存对象用点表示,节点用小圆圈表示。

5,如何获取数据所在的机器节点呢?找到数据的hashcode,顺时针查找下一个虚拟节点,这样就找到了所在的物理节点。
6,如果某个物理节点损坏了,怎么办?顺时针找已损坏节点的下一个节点,把损坏节点上的数据存入它。
举例:当C损坏,B1-C1上的所有数据,后续将存入A2;A2-C2的所有数据,后续将存入B2;A3-C3的所有数据都存入B3;B4-C4的所有数据将存入A1。相当于C节点的所有数据被A和B分担了。

7,如果向集群加一个物理节点,恰好和6是反向操作。也就是说新节点将从已有的若干个节点上,各分担一部分数据。
总结Consistent hashing:当节点变化后,它实现了只动K/n个数据的关键是什么呢?第一,虚拟化物理节点;第二,可靠的Hash算法,即能将虚拟节点和数据均匀分布在Hash环上。
三,Infinispan对分布式缓存实现
Infinispan是什么?下面是官方介绍:

Infinispan 用JGroups作为集群管理设施,可以发现集群节点,向各节点传输数据。
Infinishpan是如何实现上述consistent hash的算法呢?

Consistent hash将1到2的32次方-1的空间划分为若干Segment(numSegments由设置缓存的人定义),每个Segment分配Owner,即分配物理节点。分配好之后,这个Segment上的数据都存储在这个Owner里。
当拓扑结构变化后,如何重新计算各个Segment的Owner呢?
分析下面代码(在SyncConsistentHashFactory类里):

输入参数numberSegments就是Segment的数量。
共两层循环,外层循环:只要存在Segment没有Owner,就执行内循环。内循环是逐个遍历物理节点,用物理节点名结合VirtualNode计算出一个segment,然后将当前的物理节点设置为Segment的Owner。如何计算Segment呢?

用到一个HashFunction,实际用的就是MurMurHash,他是Austin Appleby在2008年发明的。具备更好的hash分布和更好的性能。
再来看看addPrimaryOwner是如何实现的?
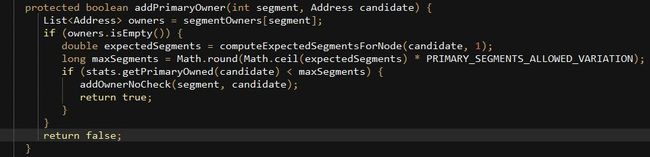
有两个If判断,1. 当前segment没有owner才往下走;2. 当前节点允许分配的segment小于它承担的Segment数量才把当前节点分配给Segment。
如何知道Node该承担多少Segment呢?再看看这里的computeExpectedSegmentsForNode函数

这里做了一些什么事呢?就是要计算当前节点能承担多少个Segment。为什么做这件事呢?因为现实中,物理机器之间是有差别的,有些物理机器内存多,有些内存少,所以,内存多的节点理所当然要分担多一点内存。这也就有了第一行取节点的CapacityFactor。像下面这一行,实际就是算权重。
nodeSegments = nodeCapacityFactor / remainingCapacity * remainingCopies;
上面有addPrimaryOwner函数,那么是不是有其他Owner呢?确实是的。考虑到数据的节点的可靠性,给每个Segment分配了多个Owner,除了PrimaryOwner,可以有多个BackupOwner。doCopyOwners实现了如何分配backupOwner:逐个Segment扫描他们的Owner,如果和当前的Owner不一样,就可以分配为backupOwner。

将Infinispan的源代码用图形方式再描述一遍。当某个节点损坏后,数据将如何转移?
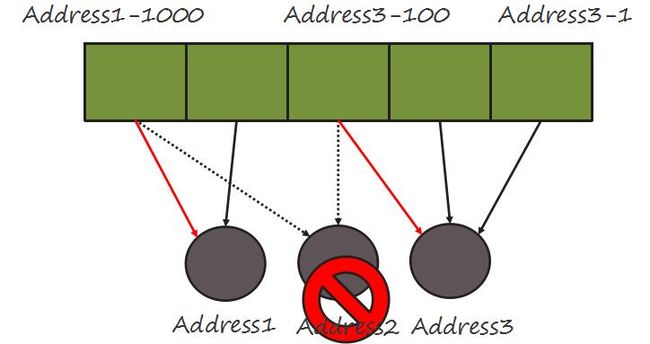
原先Address2节点是第一块和第三块Segment的owner。当Address2移除后,意味着第一块和第三块Segment上缺少Owner,所以要重新分配owner。AddPrimaryOwner函数中,假设当虚拟节点循环到100的时候,当前正好是Address3,所以,将Address3作为第三块的PrimaryOwner。与此类似,当virtual节点循环到1000的时候,将address1分配为第一块Segment的Owner。可以想象,还有其他原先属于Address2的Segment会被分配到其他节点上。
当一个新节点加入到集群后,如何分配segment的Owner呢?
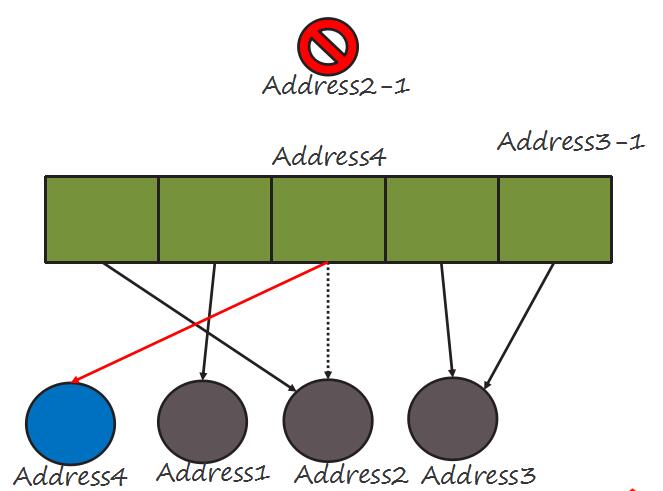
当新节点Address4加入后,重新计算Owner当Address1,Address2,Address3都被作为Owner后,轮流到给Address4找Segment,假设第三块的Segment恰好被找到,那么就可以更新它的PrimaryOwner值为Address4,原先的Address2-1就被冲掉了。可以想象,原先属于其他节点的其他Segment也可能会选Address4作为PrimaryOwner。
对比Consistent Hash的技术描述,Infinispan的segment实际就是hash环上虚拟节点之间的地址段。Segment数量就是所有虚拟节点的数量。不同点是Infinispan的寻址方式不是靠顺时针扫描,而是通过Owner映射表。
另外Infinispan考虑到数据可靠性,处理了backup数据的问题。考虑到各个机器的容量,分配更加合理的Segment数量。
全文总结:通过对ConsistentHash和Infinispan对此的实现分析,基本弄懂了分布式缓存背后的原理。通过Consistent Hash达到了两个目标:1. 数据在节点上均匀分布;2. 当拓扑结构变化后,K/n个数据被重新分布。