数据分析50图(四) —— 热点计数图
前言
华罗庚说过
数缺形时少直观,形少数时难入微.
这句话第一次听还是初中数学老师上二次方程课时说的.最近看到了3blue1brown对线性代数的直观解释感觉豁然开朗,于是我又捡起了儿时对美妙数学的兴趣. 发现一个博客,数据可视化很好的例子,决定花些时间和大家一起解读一下
例程来自:https://www.machinelearningplus.com/plots/matplotlib-histogram-python-examples//
感谢b站UP "菜菜TsaiTsai" 分享这个博客.
接着上期留下的问题,我们把不同的气缸数和百公里加速作为平面图的x,y轴以此观察他们的关系。但是许多车型会有相同的参数,比如有3种车型都是2.0L排量,4秒百公里时速。这时画出的点就会重合在一起,那么我们怎样才能把这个热度在图标上体现出来呢?
数据表地址https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv
例5
from matplotlib import patches
from scipy.spatial import ConvexHull
import warnings; warnings.simplefilter('ignore')
import seaborn as sns
sns.set_style("white")
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
sns.stripplot(df.cty, df.hwy, jitter=1, size=8, ax=ax, linewidth=.5)
# Decorations
plt.title('Use jittered plots to avoid overlapping of points', fontsize=22)
plt.show()
解析
先看下原始数据,我们选用城市道路油耗(cty)和高速道路油耗(hwy)作为要画的平面点。复习一下怎么选取表格中的列:df[["cty",'hwy']]
| cty | hwy | |
|---|---|---|
| 0 | 18 | 29 |
| 1 | 21 | 29 |
| 2 | 20 | 31 |
| 3 | 21 | 30 |
| 4 | 16 | 26 |
| 5 | 18 | 26 |
| 6 | 18 | 27 |
| 7 | 18 | 26 |
| 。。。 | 。。。 | 。。。 |
解析下代码流程
- 导入数据表
- 设置画布尺寸等
- 画图
- 标注 图表的头和轴的名字等等信息
方法参数解释
-
stripplot() 散点图方法
这次代码不多我们不妨先不急着运行例子。sns.stripplot() 中有一个不太明白意思的参数 jitter 可以删掉他看看会怎么样【图1】我们观察x轴为20的列 明显有些点颜色深,这就是因为重叠了。然后我们看看 jitter 参数怎么解决这个问题的【图2】就像他的意思“抖动”一样,就好像这个图是一个手脚不利索的老人画的,他总是不能精确的把点画在同一个地方。可是这并没有解决问题,我们只是很明显的知道这里有许多同样的点,并不能帮助们进一步分析数据。我们需要更加定性的分析,所以接下去再看一个例子。
图像

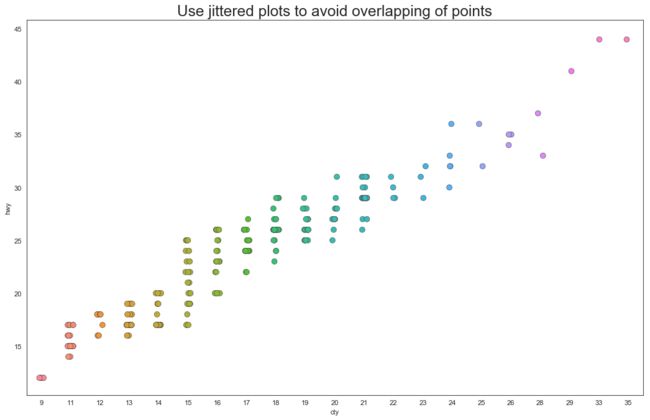
例6
df_counts = df.groupby(['hwy', 'cty']).size().reset_index(name='counts')
# Draw Stripplot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
sns.stripplot(df_counts.cty, df_counts.hwy, size=df_counts.counts*2, ax=ax)
# Decorations
plt.title('Counts Plot - Size of circle is bigger as more points overlap', fontsize=22)
plt.show()
解析
这2个图的关联很大,所以我决定把2期放在一起,更能保持读者的思维。
解析下代码流程
- 把重复的参数次数提取出来
- 设置画布尺寸
- 画图
- 标注信息
方法参数解释
没有新参数引入,简单介绍下 df.groupby() 和数据库的 groupby 相同,他把表按关键字中值相同的分成一组。 比如:运动会上按身高分组,把同样是155cm的10个人分一组,160cm的7个人分一组等等。
df_counts = df.groupby(['hwy', 'cty']).size().reset_index(name='counts') 看下这句话不禁的感叹 python 的易用性,这句话就好像是口述说明一样:把 df 按 hwy、cty 分组计算出个数(每组的长度)并把这个新的列命名为 counts。
图像
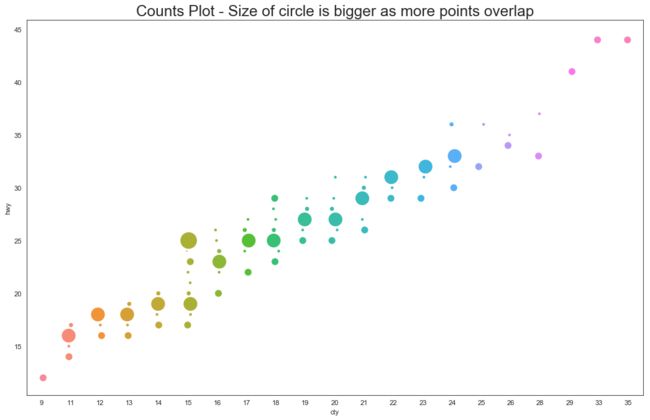
应用
刚才我们能看到重合的点了,但是不能定量的分析他。这里我的解决办法是引入一个新的维度来展现重复次数(热度)。
先思考一个问题平面图上可以利用的维度有那些? 你可别急着看下去,提示下我们曾经在平面上表示三维物体的坐标。
平面相交直线确定一点,所以显然的 x,y 坐标是2个,我们需要表达第三个变量时还能想到等高线图,在一个平面图像上表示高度,还有颜色也可以利用。还有什么呢?我暂时还没想到。回到正题上这里作者巧妙的用点的大小来表示同一个型号热度,图像既美观有直观。可是我们需要更加具体的分析热度大小这还是不够的。下期我们将结核直方图和着张图来更深入的分析给出更好的热点图。
下期预告
例7 带频次统计的散点图 —— 中值计算