
论文通读
Abstract
在此之前的CNN的输入必须是固定大小的图片。而SPPnet能接受任何大小的图片,并都能产生同一个尺寸的特征向量。SPPnet还有一个很大的好处就是快速并且检测精度高。快速在于:对于全部的图片,我们只需要计算一次Feature map,然后在任意一个区域(子区域)池化这个Feature得到同一个大小的表达式。最后进入训练的探测器。这一步,避免了重复计算卷积特征。这篇文章介绍的方法在Pascal VOC 2007,和ILSVRC上都取得了很好的效果。
1.Introuction
是在卷积层和全连接层之间添加spatial pyramid pooling层。
之前SPM(spatial pyramid matching)作为Bag-of-Words (BoW) 模型的衍生版在机器视觉的领域中十分成功。
SPPnet有一下三点很好的性质:
1.不管输入的尺寸大小,输出总是固定尺寸的特征向量。
2.使用多尺度容器,这时滑窗池化只用单一尺寸。多尺度的池化可以提高精度。
3.可以在不同的尺度上对特征进行池化。
我们采用多个共享权重的网络结构,来处理不同尺寸的输入,但是对于某一个网络我们采用固定大小的输入。
文章中在不同的4个CNN的构架上使用SPP结构,发现效果都有了很大的提升。
R-CNN不行在于对于一个未处理过的来自图片的像素,他总是重复的调用卷积神经网络进行计算。
2 DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
2.1 Convolutional Layers and Feature Maps
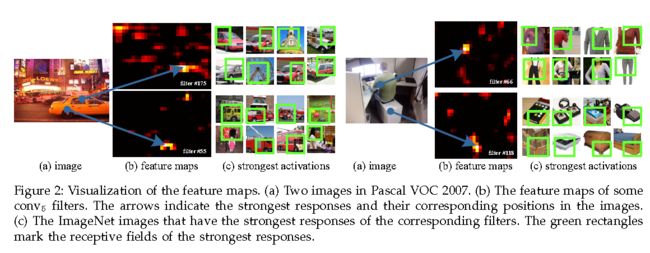
文章之前也讨论过,真正需要固定大小输入的是全连接层,卷积层是不需要固定大小的输入(因为滑动窗口的存在)。卷积层的输出称之为Feature map ,它不仅包括对目标的反映的强度,而且还包含位置信息。具有很丰富的语义信息。
2.2 The Spatial Pyramid Pooling Layer
因为这个卷积层可以接受任意尺寸的输入,那么卷积层的输出也是任意结构的。但是后面的全连接层确是需要固定大小的尺寸。为此我们在卷积层的最后一层中,把pooling层用空间金字塔pooling层代替。
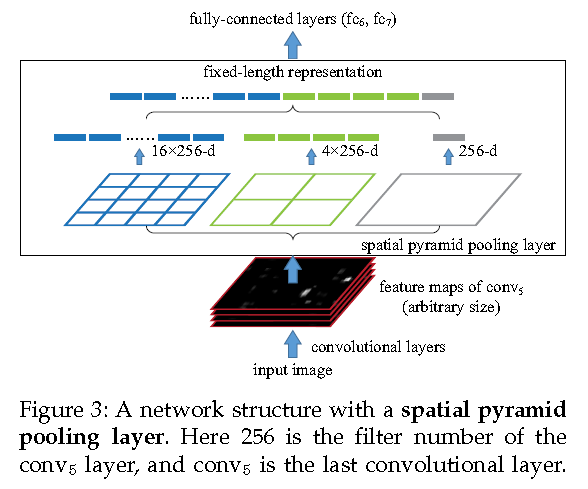
具体地,在一个CNN里,把最以后一次池化层去掉,换成一个SPP去做最大池化操作(max pooling).如果最后一次卷积得到了k个feature map,也就是有k个filter,SPP有M个bin,那经过SPP得到的是一个kM维的向量.我的理解是,比如上图中第一个feature map有16个bin,一共有256个feature map,每一个经过16个bin的max pooling得到16个数,那256个feature map就是16x256的向量了.SPP的bin大小可以选择多个,所以经过SPP还能产生4x256,1x256维的向量.
bin的size是和输入图像size成比例的,而bin的个数是不变的。如果我们把bin当成另一种滑窗来看待的话,比较好理解。
我们可以对不同比例,不同大小的图片进行处理,而且使用同一个CNN,只是对不同大小的图片,在最后的SPP里,bin的大小不同,但最后得到的特征确实相同维度.
这样,我们把一张图片resize成不同尺度,放到同一个CNN里训练,就能得到不同尺度下的特征,就和SIFT类似了.
上图中单独的Bin起到了全局信息的作用,从另一方面也减少了过拟合的问题。
2.3 Training the Network
如何在GPU上实现空间金字塔的卷积层。
Single-size training
对于一张给定尺寸的的输入图片,我们可以提前计算Bin的尺寸。


Multi-size training
对于多尺寸的训练,我们依据输入的大小来更改spp-net的size大小,使得输出的特征向量size相同。
文中多尺度训练采用的是在一个epoch内采用同一尺度(如224),在另一个epoch使用另外一个尺度(如180)。
把单个size中的224*224图片,缩小到180*180,而不是在原图上从新提取一个新的180*180的图片,这样可以保证两张图片内容一致。通过调整SPP的pooling 窗口和间隔距离得到相同的输出。
在训练中为了避免频繁更换网络的麻烦,采用先用224*224迭代训练一遍,然后复制参数用180*180的网络训练,如此循环。
3 SPP-NET FOR IMAGE CLASSIFICATION
3.1 Experiments on ImageNet 2012 Classification
本文实在整个图片上取4个角和中心,进行网络训练(和Alex-net中在256*256上去法不同)。
本文采用的是以ZF fast作为基本框架,具体结构如下:
Input(224,224,3)→96F(7,7,3,2)→LRN→max-p(3,3,2)→256F(5,5,96,5)→LRN→max-p(3,3,2)→384(3,3,256,1) →384F(3,3,384,1) →256F(3,3,384,1) →max-p(3,3,2) →4096fc→4096fc-1000softmax
测试阶段采用10-view方法:
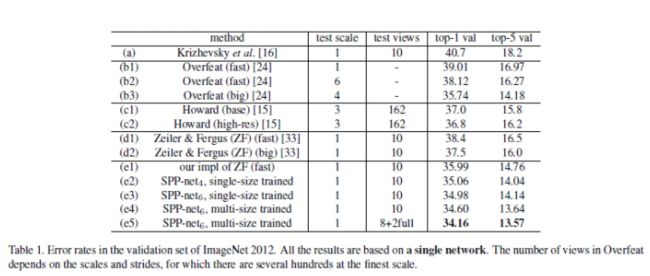
e2采用SPP-4,4个分级,分别为4*4,3*3,2*2,1*1 共计30维
e3采用SPP-6,,4个分级,分别为6*6,3*3,2*2,1*1 共计50维
结果分析:
1:(e1)获得了top-1 35.99%的错误率;比原论文中报告的38.4%降低了近3%,说明这种在原图像上截取224*224训练图片的方法比较好。
2:top-1,e3>e2>e1 ;top-5,e2>e3>e1;说明spp结构确实很有用,而且对比ZF-net,spp-4有更少的参数,最后一个特征层特征图,ZF为6*6=36,spp-4为30个,说明spp结构对于物体的空间位置和形变具有鲁棒性。
3:e4在180*180和224*224两种scale上训练网络,在224*224上测试分类,top-5结果达到了13.64%。所以multi-scale训练的方式很重要;根据ZF可视化论文中对平移和缩放不变形的探讨中,使用multi-scale可以增加网络对于平移和缩放的不变性。
4:e5,作者用原始整个图像(水平翻转)替换10-view中的连个中心剪裁图片,使得top-5达到了13.57%,这说明输入图片和物体的匹配程度确实影响分类结果(和OverFeat中使用offset和sliding window的原因相同,匹配的越好,分类月准确)
5:对比OverFeat中的fast和accurate两个模型对比来看,仅仅就分类来说,本文在没有采取更加复杂的网络情况下,没有使用sliding window和offset的情况下,利用一些相对简单的方法获得了较好的结果。
3.2 3.3在Pascal VOC 2007和Caltech 101上实验
通过在ImageNet上训练的特征提取器,应用在其他数据及上,在新的训练集上用SVM作为分类器,进行训练。作者刷新了这两个数据集VOC 2007上结果是80.1%,Caltech101上结果是91.44%
实验结果证明网络越深越好,SPP结构比一般的网络结构好;在全图上结构比剪裁的结果好;在不同比例上图片上训练会有不通过结果。说明卷积网络对于图像的scale有些敏感,SPPnet能够部分地解决问题。
4 SPP-NET FOR OBJECT DETECTION
传统的R-CNN慢的原因在于:对于与每一张输入图片,我们都会产生2000张的候选区域,对于每一个候选区域,我们都要喂进我们的cnn模型中进行特征的抽取。换句话说,对于每一张输入图片,我们都要进行2000次的cnn。这个大大增加了实践的消耗。
SPP-net比较快的原因在于:对弈每一张的输入图片,我们只需要进行一次的cnn,抽取到一个featuremap即可。而在spatail pyramid pooling层,我们再对2000个候选区域的feature map进行处理即可。
4.1 Detection Algorithm
模型
1.用了快速选择性搜索对于每一张图片都产生2000个候选区域。
2.然后我们调整图片使得min(w,h)=s,然以对于一整张图片我们进入卷积层抽取他的feature map.
3.对于每个候选窗,我们使用四阶空间金字塔(1+2*2+3*3+4*4=50)50个bin去池化这个feature map 。来产生12800(256*50)维的表达式。
4.进入全连接层.
5.对于每一个类别,我们都训练一个二值的线性SVM的分类器。
训练
1.我们用真实的框,来产生正负候选区域的样本。(IoU)
2.我们用standard hard negative miming的方法来训练SVM.
测试
SVM用于给每一个类别一个分数。然后用非极大值抑制来判定。
多尺度特征抽取
对于每一个候选窗口我们都在集合{480,576,688,864,1200}中选一个尺度s.使得min(w,h)=s,使得这个窗口的像素个数接近224*224。
对于传统的R-CNN,SPP-net对其进行了结构的微调和bounding box regression 的处理。
4.2 Detection Results
4.3 Complexity and Running Time
4.4 Model Combination for Detection
对于不同的初始化方式(其余相同),在训练一个网络。SPP-net(2)。发现性能和(1)差不多。在测试时,用分别来自两个网络的分数,采用非极大值抑制的方法来最终采取判断。发现,结果有了显著的提升。

4.5 ILSVRC 2014 Detection
总之通过spp-net的方法比R-CNN的方法要快很多,但是和OverFeat比较作者没有给出,此外本文是在VOC 2007数据集上做的测试,OverFeat实在ILSVRC 2013的数据集上做的测试。两种方法都是使用回归的方法来预测bounding box。