Tips:未进行说明的符号主要参照Lec 1 ,部分参照其他Lec.
上一节介绍了ML中非常重要的工具VC Dimension,说明了learning发生的理论保障和一些条件:当dvc有限、N足够大、Ein较低时,learning 可行。
这节将从data出发,介绍存在noise和error时会是怎样的情况?之前的理论是否可以放宽到这种情况?
Lec 8:Noise and Error
1、Noise and Probabilistic Target
之前Pocket里面有提到noise,noise来源有三点:1)来自错误标记y;2)同一个x有两个不同的y;3)x不正确;
存在Noise的时候,VC Bound是否还有效呢?
回顾一下小球问题,小球x~P(x),抽出小球的颜色是确定的,橘色代表 f(x)≠ h(x);绿色代表 f(x)= h(x);
现在有noise是怎么样的?小球x~P(x),不同的是当抽出小球时,小球的颜色并不是确定的,但颜色也会存在一种分布distribution,如何获得?sample!表示为 y~P(y|x);
在x~P(x),y~P(y|x)的情况下重新证明VC Bound,任然会是成立的,不给出证明。
实际上,只要训练&测试的(x,y)来自同一个P,则VC Bound可以work.
现在学习的目标不是target function,而是target distribution P(y|x),可以看做是 ideal mini-target + noise. 例如:结果给出P(1 | x)= 0.7,P(0 | x) = 0.3,自然会选择0.7那个结果,而0.3就可以看做是Noise的level.
到这里就可以看出,之前学习 f 的情况是学习target distribution的特例。
(注:"predict ideal mini-target (w.r.t. P(y|x))on often-seen inputs(w.r.t. P(x))" 这个结论感觉自己还没有理解好,所以也不知道怎么解释好,希望可以得到大家的指点 )
2、Error Measure
我们的学习目标是得到一个接近f的g,g≈f. 之前也多数在围绕这个目标讨论,什么样是接近的?前面是用Eout(g)来衡量,Eout(g)越小越好。

Eout这个衡量标准有3个注意点:out-of-sample,对未来的预测;pointwise,可以在单个data上衡量;二元分类,“对”or“错”,又叫 0/1 error.
更一般的衡量标准可以用 E(g,f)表示,在一个点上判断对错再对多个点平均, E(g,f) = averaged err(g(x),f(x)),err叫做 “Pointwise Error Measure”. 所以可以表示Ein(g)和Eout(g)为:
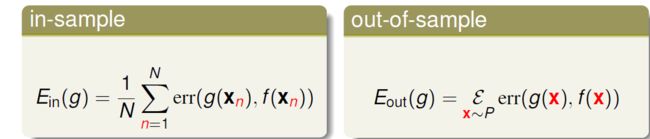
之后的课程中主要使用 pointwise err 作为衡量,当然实际中也存在更复杂的衡量。
Pointwise Error Measure主要有两种:0/1 err 和 squared err

类别型:0/1 err 是判断对错,主要用在分类,选择对应的错误概率最低的y作为结果;
数值型:squared err 是判断“距离”,主要用在回归(后续会有介绍),y是加权平均值(可以证明得到),如下图:
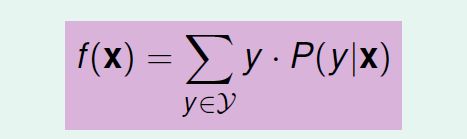
到这里,对learning的理解已经深入一些了,这里再附一张更详细的learning flow的图,可以和Lec 1的比较一下:

直接给出拓展:vc theory / philosophy 对大部分H和err都可以成立!
3、Error Measure in Algorithm
结合实际应用,err存在两种错误情形:false reject 和 false accept,比如设备的指纹识别,错误的拒绝了用户 和 错误的接受了攻击者。

在 0/1 err中对这两种情形的penalty(惩罚)是同等的,但是在实际中,对于不同的应用场景、不同的使用者等来说,err两种错误情形的惩罚标准应该不同。比如 超市顾客认证系统 和 CIA认证系统,不同错误产生的后果差异巨大。所以,在设计学习算法的时候,应该考虑这一点,但是……但是……通常很难确定惩罚标准,1000?5000?or?不好说惩罚多少。通常会选择一种err的 替代品 或 容易最佳化的&合理的 err^.设计合适的err^是学习算法设计中的核心部分!
后面的章节会看到,不同的学习算法A的err^设计各异,各有千秋,自然可以理解这里说的意思,嘿嘿。选择一个right的err^非常重要!最后就会发现,大部分学习算法就是对err^的最佳化,最后都是数学问题。 个人觉得,理解了算法的err^设计,就差不多理解了算法的 philosophy.
4、Weighted Classification
给二元分类的err加上权重的分类称为weighted classification.
给出一个名词:cost或error或 loss matrix,表示不同错误情景的代价。下图展示了对应超市和CIA认证的cost matrix.

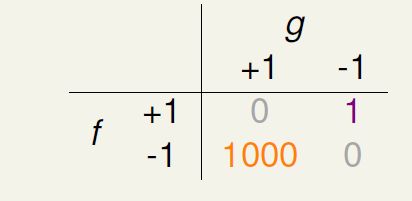
此时Ein和Eout形式为:

VC理论对于这种理论还是适用的,那么希望Ein越小越好,带weight的Ein如何解?
1)对于PLA来说,Ein = 0,weight不影响什么;
2)对于pocket来说,需要modify一下。很简单,只需在比较Wt+1和Wt时,比较加权错误的大小?!真的这么简单吗?可是考虑一下,pocket的理论保障是对于 0/1 err,这样简单的修改也许会破坏之前的理论保障?保持怀疑。
其实有一种巧妙方法可以把 weighted Ein 变换成 0/1 Ein:把y = -1 的data 复制1000倍!嗯哼~这时error matrix就和0/1 error matrix一样,可以使用 pocket 了,但其实应该modify两点(更严谨,也很巧妙):
1)其实实现copy的时候,并不需要真的复制1000倍并存储下来,称为“virtual copy”。所以应该频繁地(1000倍)check y = -1 的data;
2)比较Wt+1和Wt时,比较加权错误的大小;
这个转化思路可以应用在很多其他的algorithms上,叫做 “reduction”。
Fun Time 值得提一下:

这个题目体现了data的unbalanced的情况,properly设置weight可以避免这种情况。
至此why部分结束,下面将主要进行各种Algorithm的介绍~