
整理 | Jane
责编 | Jane
出品 | AI科技大本营(公众号id:rgznai100)
【编者按】这篇文章的起意有两点:一是由刚刚过去的 315 打假日,智能语音机器人在过去一年拨出的超 40 亿电话,联想到前一段时间引起大家热烈讨论的 StyleGAN 生成假脸,明年的打假日 AI 是否又会有“新作品”?二是即将到来的 April Fool's Day,随着 AI 不断智能化,那天是不是也可以捉弄一下 AI?要如何攻击强大又复杂的神经网络呢?有什么方法和策略?由此,营长就想在本文中与大家一起探讨关于“机器学习 Adversarial Attack”的那些事儿。
视觉有多重要?对于我们人类来说,获取的外界信息中有 80% 都是通过视觉通道接收的,是第一大感觉信息通道。可是,人的视觉不仅能为我们带来这些信息,也容易让我们受到欺骗,有一些错觉是我们无法避免的。现在,除了要被自己的错误知觉“欺骗”,还要被 AI 欺骗。
前一段时间,一项AI 成果让不少国内外的小伙伴都觉得非常的 “Amazing”、“Unbelievable”,甚至有些“Creepy”、“Terrible”,没错就是那个利用 StyleGAN 做的网站,俗称“没有这个人”。你在这个网站上每刷新一次,都会显示一张人脸,但是每张脸都是假的。比如:

(来源:https://thispersondoesnotexist.com/)
这么帅的小哥哥真的是假的吗?怎么就是觉得“似曾相识”呢!
一些照片还是有明显的穿帮痕迹,也有一些照片非常逼真,看多了真是觉得“神奇”又“瘆得慌”。得益于 GAN 模型的发展,除了假人像,还有假视频、假画,都让我们难以分辨,难道只有我们被骗的份儿?想要在机器视觉现有的能力范围内欺骗 AI,可以怎么做?
一个最经典的例子:
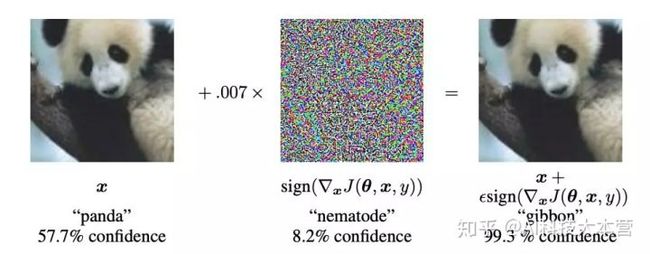
一开始给模型识别左图,AI 的模型可以判别是“panda”,置信度 57.7%,然后加一点“干扰”,把右面的图再让模型判别(哈哈哈~)这只萌萌哒的熊猫就变成了“gibbon”(长臂猿),天呐,对这样的结果还自信心爆棚呢,置信度有“99.3”,这还真是惊呆了营长。
还有这只”会飞的猪“~

Pig 变飞机,看到这个结果,天蓬元帅怕是要来找你了~
这样迷之自信的例子还有很多,营长略加分类整理了一下,下面的这些内容很“逗乐”,建议反复观看
一、不同领域/场景下的
Fool Time
计算机视觉领域
最开始这类有趣的例子多是在图像分类任务中发现的,后来拓展到分割与检测任务研究中,再到一些重要的应用场景中,都发现了漏洞。
1、图像分类:Attacks for classification

左图:给 Origami 列的图像加上一点 Perturbation(干扰),结果就变成了 Adversarial 列中红字的结果:“ostrich, Struthio,camelus”(鸵鸟和骆驼)。
右图:每个图像下方都标注了原始标签和处理后的分类结果,真是五花八门,刷新了认知。

上面的每个图处理后分别让 CaffeNet、VGG-F 和 GoogLeNet 三个网络模型做判别得到的结果。
2、语义分割与目标检测:Attacks on Semantic Segmentation and Object Detection
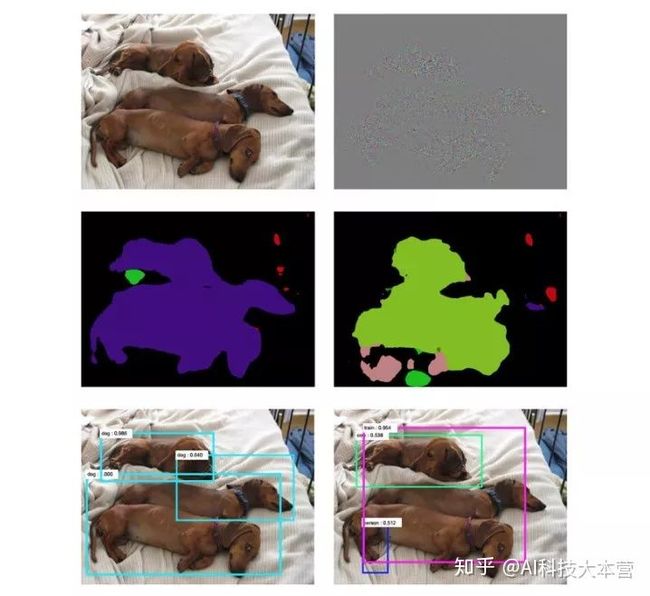
用于分割和检测的模型:FCN 和 Faster-RCNN 。左列第三个图的分割和检测识别的结果都非常好,加入干扰后的样本,无论是分割还是识别结果都出现了悬殊差异,有“人”,有“火车”......
3、3D 打印
2017 年,MIT 通过一只 3D 打印乌龟的不同姿势,彻底骗倒了 ImageNet 模型。被识别成 rifle(手枪),也是没谁了!

前一段时间,Google Brain 的研究员发现,在一根香蕉的旁边放了一张贴纸,模型就不认识这根香蕉了,硬要说人家是面包机。
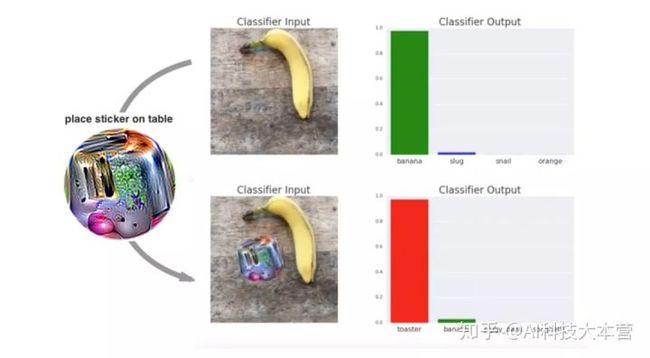
4、自动驾驶
试想上面的这些如果应用到我们实际生活中,这样的“error”可不是玩笑,儿戏了。例如,在自动驾驶中,最常见的场景:识别交通路牌。不同距离、不同角度这些都还算不上特殊情况,但仅在分类模型上取得高精准度是远远不够的。

5、人脸识别攻击:FaceID
现在的手机都有面部识别功能,尤其是用 FaceID 支持一系列涉及安全与隐私等功能时,如支付、转账。如果这么容易被攻击.......

还有,在医疗影像辅助诊疗系统中,一个小阴影会产生怎样的结果,不敢深想。(内心充满了拒绝)
除了计算机视觉领域,还有在其他技术领域不同场景的研究:
NLP 领域: QA 对话
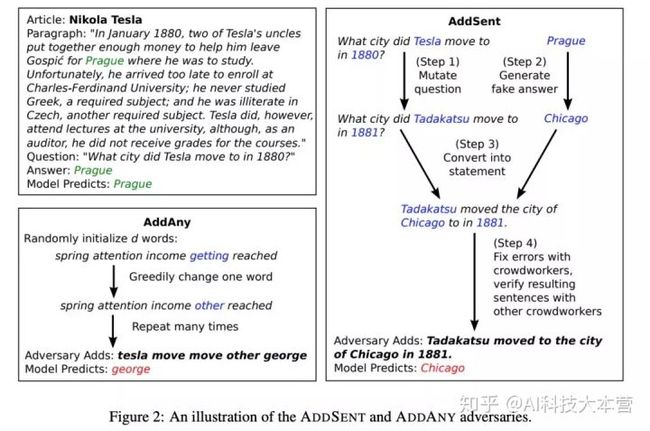
论文:《Adversarial Examples for Evaluating Reading Comprehension Systems》
语音识别的攻击
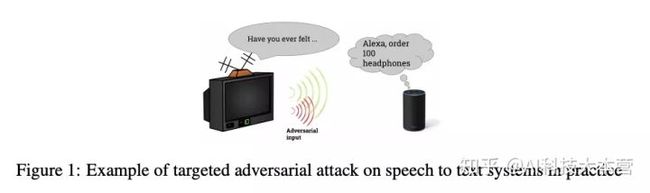
论文《Targeted Adversarial Examples for Black Box Audio Systems》:对语音识别系统进行黑盒、定向样本攻击

论文《Audio Adversarial Examples: Targeted Attacks on Speech-to-Text》:对百度 DeepSpeech 进行白盒、定向攻击。
对图网络、知识图谱领域的攻击

《Adversarial Attack on Graph Structured Data》(ICML 2018)
《Adversarial attacks on neuralnetworks for graph data》
安全领域
在 AAAI 2019 安全领域接收论文中, Adversarial Attacks 的研究成果也比以往有所增加,如《Distributionally Adversarial Attack 》《Non-Local Context Encoder: Robust Biomedical Image Segmentation against Adversarial Attacks 》等。
二、什么是对抗攻击
GAN 的不断发展,创造了很多让我们难辨真伪的神奇、虚假的结果,同样,GAN 也是机器学习与深度学习中网络模型的“试金石”。这就是我们上面那些例子发挥的作用:对抗攻击。
什么是对抗攻击?上面列出的例子中大多属于有目标攻击,通过对抗性样本进行攻击模型,导致模型出错,进而产生潜在危险。2014 年 Szegedy 等人[1]率先在图像分类任务中发现了深度学习的一些弱点,论文中通过一些“有趣的例子”,向大家阐述即使再鲁棒,准确性再高的神经网络,也都是非常容易受到攻击的。([1]论文《Intriguing properties of neural networks》可以说是对抗攻击领域的开山之作了)
除了不同场景下,通过对抗性样本进行攻击方法,还有对模型本身的攻击,如对 RNN、强化学习等模型的攻击。ICML 2018 的一篇论文《Adversarial Attack on Graph Structured Data》试图探讨对 GNN 网络进行对抗攻击,并尝试了多种算法。
虽然深度学习在计算机视觉、语音识别、NLP等领域中的很多任务都取得了显著的突破性成果,深度神经网络模型也越来越完善,但是这些技术是否真正成熟,产品是否足够安全、可靠?这些将成为以后越来越被重视的问题,这也是对抗攻击越来越重要的原因。
重要术语
为了便于大家在接下来的阅读过程中容易理解,这里先提前为大家对一些重要的术语做简单解释:
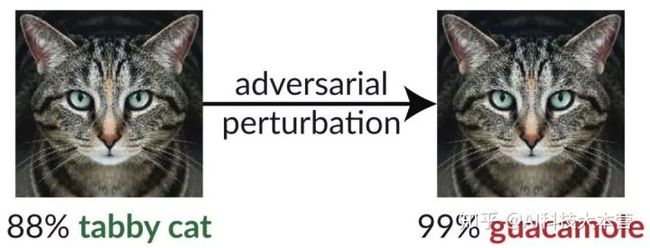
1、对抗样本:上面营长做了简单、通俗的解释。在原本图像中(Origanal)加入一些 Perturbation(扰动),这些干扰,或是噪声都是极小、轻微的,我们人眼是无法觉察到的,机器模型接收这些数据作为输入,产生错误的结果。构造攻击性样本分为定向和非定向两种类型。
非定向对抗性样本攻击:模型识别错误即为攻击成功,如将猫识别成鳄梨酱……
定向对抗性样本攻击:目标更明确,让模型错误识别到某结果;如目标是让模型把猫识别成狗,只有这种情况才算攻击成功。
2、攻击模型:主要分为黑盒攻击与白盒攻击两种方法
黑盒攻击:攻击者并不知道模型所使用的算法和参数,但仍能与深度模型网络有所交互。比如可以通过传入任意输入观察输出,判断输出。
白盒攻击:攻击者知道模型所使用的算法,以及算法所使用的参数。如果给定一个网络参数,白盒攻击是最成功的方法,如 L-BFGS、FGSM。
3、防御方法:有三个主要方向,其中为大家重点介绍两个思路:
混淆梯度(Obfuscated gradients):让攻击者找不到有用的梯度。
胶囊网路(Capsules network):CapsNet 模型的原作者有 Sabour、Frosst 以及 Hinton。
三、攻击算法的发展
根据采用黑盒/白盒攻击、定向/非定向等分类,将生成对抗性样本的方法归纳总结了 12 类:
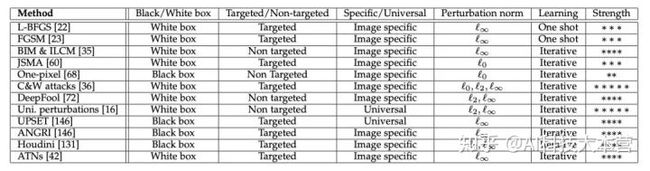
L-BFGS 方法是 Szegedy等人率先提出的,随后,Ian Goodfellow 在论文《Explaining and Harnessing Adversarial Examples》中提出 FGSM(Fast Gradient Sign Method),一种白盒、定向攻击方法,通过发现对抗样本扰动的线性解释,提出对扰动进行有效计算。
One Pixel 提出的差分进化方法不同于以往通过改变像素值来进行攻击,采用黑盒攻击方法,在不知道网络参数等信息下,通过迭代择优进行攻击,达到了显著的效果。DeepFool是一种白盒、非定向的攻击方法,作者在研究中表示比 FGSM 方法生成的扰动更小。论文《Breaking High Performance Image Classifiers》中提出两种黑盒、定向的攻击方法:UPSET 和 ANGRI,UPSET 可以生成为特定类别生成对抗扰动。
而 ICLR 2018 的最佳论文《Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples》提出了 Backwards Pass Differentiable Approximation(BPDA),攻击了 7 篇论文中提出的基于混淆梯度防御方法,并表示成功攻击了 6 篇,另外一篇部分被攻击。
四、防御方法
“来而不往非礼也”,你攻我守。随着对抗攻击的不断深入研究,防御方法也需要不断的研究。NIPS 2017 会上,由 Ian Goodfellow 牵头举办了第一届 Adversarial Attacks and Defences(对抗攻击防御)比赛。在这次比赛中,清华组成的团队在三个比赛项目中得到了冠军。
在防御上的主要思路、方法有下面这三类:在学习中修改训练过程或输入样本数据,例如把对抗样本加入模型训练中,修改网络,或者利用附加网络。

其中,针对利用梯度下降方法生成对抗性样本的进行防御的混淆梯度(Obfuscated gradients)方法主要分三类:离散梯度、随机梯度与梯度爆炸(或梯度消失)。
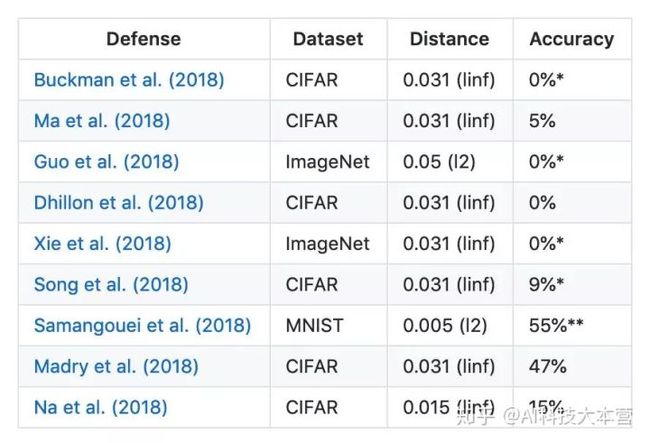
BPDA 方法作者称已经成功攻击了上面的大多数方法。这项结果的发表也引起了 Ian Goodfellow 的回应与质疑,“在《Ensemble Adversarial Training: Attacks and Defenses》研究中已经解决相关问题”,但攻击之法不断,对抗样本防御方法也还有很长的路要走。
而胶囊网路(CapsNet 模型的原作者有 Sabour、Frosst 以及 Hinton,论文《Dynamic Routing Between Capsules》)近期在此方面也有新进展,论文《DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules》(Nicholas Frosst、Sara Sabour、Geoffrey Hinton 等人)指出,CapsNet 不仅可以对图像分类,还可以结合重建过程,利用 DARCCC 技术有效地检测对抗攻击样本。(准确来说,这是一种自动检测技术,还不等同于防御方法。)不过,这种方法在黑盒攻击方法,以及白盒攻击方法 FGSM 上的检测效果都还不错,但在更强大的白盒攻击方法上还不能攻破。

五、未来研究新趋势
2018 年 GeekPwn CAAD(对抗样本挑战赛)上,战队[IYSWIM] 用传统的黑盒攻击方法,仅 21 分钟就破解了亚马逊名人鉴别系统 Celebrity Recognition。AI 模型本身以及应用模型的产品的安全性问题再一次引发我们的深思与更深入的研究。
现在 AI 在各领域不断取得研究突破,并被广泛应用,之前便有言论称“AI 已经超越人类”?此时也许还不是给“ !”的时候,越是在看似已经取得良好成果的时候,越是要深思是否真的这么好?接下来要做什么?深度学习网络模型需要对抗攻击更完善自己,进一步提高安全性。语音助手也不该是 Liar,自动驾驶更不能是 Killer。我们可以针对特定的场景进行对抗样本攻击与防御,但是一张图片可以放到不同模型中,如何用新算法对抗不同领域、不同场景、不同模型的攻击?机器学习的下一城,相信有 Adversarial Attack!
注:本文论点与材料主要依据综述论文《Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey》,阅读提取后整理,并参考文中引用的一些重点论文;后续内容主要参考 ICLR 2018 相关接收论文整理。
主要参考链接:
https://arxiv.org/pdf/1801.00553.pdf
https://arxiv.org/pdf/1705.07204.pdf
https://www.ieee-security.org/TC/SPW2018/DLS/
想要了解 Adversarial Attack 领域可以先从这一百多篇论文入手,够读好久好久的了,加油!也欢迎大家与我们分享、交流,深度解读可投稿给 AI科技大本营。
(本文为AI科技大本营整理,转载请微信联系 1092722531)
「2019 Python开发者日」7折票限时开售!这一次我们依然“只讲技术,拒绝空谈”,除了10余位一线Python技术专家的演讲外 ,大会还安排了深度培训实操环节,为开发者们带来更多深度实战的机会。扫描海报二维码,即刻抢购7折票!
