MapReduce编程重点把握
MapReduce核心概念
中心思想:分而治之,分布式计算模型
Map(映射)
分布式的计算模型,处理海量数据
一个简单的MR程序需要指定:
map()、reduce()、input、output
处理的数据放在input中,处理的结果放在output中 
MR有一定的格式如下:

以
input -> map() -> reduce() -> output
思考几个问题
1. 对处理的文件转化成什么样的?
2. map()输出结果变成什么样的?
3. reduce()是怎么处理的,输出的又是什么样的?
词频统计wordcount的具体执行过程

默认是把每一行当成一个
hadoop hdfs -> <0, hadoop hdfs>
hadoop mapreduce hadoop yarn
hadoop hello
mapreduce hadoop
yarn hadoop
比如我们要统计单词 (1) 分割单词 ,按照空格进行分词
hadoop hdfs -> hadoop hdfs
记录出现的次数,每出现一次记录为:
Map()
reduce的输入就是map的输出
reduce() 将相同key的value累加到一起
方法的重写shift+Alt+S

MapReduce代码逻辑主干初写
package com.beifeng.bigdata.senior.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class WordCountMapReduce {
//Step 1: Mapper Class
public static class WordCountMapper extends Mapper
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub } }
//Step 2: Reducer Class public static class WordCountReducer extends
Reducer
@Override
protected void reduce(Text key, Iterable
values, Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub }
public int run(String[] args) {
// TODO Auto-generated method stub return 0; }
}
//Step 3: Driver public int run(String[] args) throws Exception {
//read configuration file
Configuration configuration = new Configuration();
//create job
Job job = Job.getInstance(configuration, this.getClass().getSimpleName()); job.setJarByClass(this.getClass());
//set job
//input:
Path inpath = new Path(args[0]); FileInputFormat.addInputPath(job, inpath);
//mapper
job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class);
//reducer
job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
//submit job
boolean isSucess = job.waitForCompletion(true);
return isSucess ? 0:1;
}
public static void main(String[] args) throws Exception { args = new String [] {
"hdfs://bigdata-senior01.beifeng.com:8020/user/beifeng/input/",
//
"hdfs://bigdata-senior01.beifeng.com:8020/user/beifeng/output9"
};
//run job
int status = new WordCountReducer().run(args);
System.exit(status);
}
}
对在map和reduce阶段的处理
package com.beifeng.bigdata.senior.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class WordCountMapReduce {
//Step 1: Mapper Class
public static class WordCountMapper extends
Mapper
private Text mapOutputKey = new Text();
private final static IntWritable mapOutputValue = new IntWritable();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//line value
String lineValue = value.toString();
//split line words into separated word
String [] strs = lineValue.split(" ");
//record each value by "for" iterator to build
for (String str : strs) {
}
}
}
//Step 2: Reducer Class
public static class WordCountReducer extends
Reducer
private IntWritable outputValue = new IntWritable(); @Override
protected void reduce(Text key, Iterable
Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum = 0;
//Iterator
for(IntWritable value : values){
sum += value.get();
}
//set output value
outputValue.set(sum);
//output
context.write(key, outputValue);
}
public int run(String[] args) {
// TODO Auto-generated method stub
return 0;
}
}
//Step 3: Driver
public int run(String[] args) throws Exception {
//read configuration file
Configuration configuration = new Configuration();
//create job
Job job = Job.getInstance(configuration, this.getClass().getSimpleName()); job.setJarByClass(this.getClass());
//set job
//input:
Path inpath = new Path(args[0]); FileInputFormat.addInputPath(job, inpath);
//mapper
job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //reducer
job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
//submit job
boolean isSucess = job.waitForCompletion(true);
return isSucess ? 0:1;
}
public static void main(String[] args) throws Exception { args = new String [] {
"hdfs://bigdata-senior01.beifeng.com:8020/user/beifeng/input/",
"hdfs://bigdata-senior01.beifeng.com:8020/user/beifeng/output"
};
//run job
int status = new WordCountMapReduce().run(args); System.exit(status);
}
}
尝试使用mapreduce来处理wordcount
package com.beifeng.bigdata.senior.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMapReduce {
//Step 1: Mapper Class
public static class WordCountMapper extends Mapper
private Text mapOutputKey = new Text();
private final static IntWritable mapOutputValue = new IntWritable(1);
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub System.out.println("map-in-0-key" + key.get() + " -- " + "map-in-value" + value.toString());
//line value
String lineValue = value.toString();
//split line words into separated word
String [] strs = lineValue.split(" ");
//record each value by "for" iterator to build
//set map output key mapOutputKey.set(str);
//output
context.write(mapOutputKey, mapOutputValue); }
}
}
//Step 2: Reducer Class
public static class WordCountReducer extends
Reducer
private IntWritable outputValue = new IntWritable(); @Override
protected void reduce(Text key, Iterable
// TODO Auto-generated method stub
int sum = 0;
//Iterator
for(IntWritable value : values){
sum += value.get();
}
//set output value
outputValue.set(sum);
//output
context.write(key, outputValue);
}
}
//Step 3: Driver
public int run(String[] args) throws Exception {
//read configuration file
Configuration configuration = new Configuration();
//create job
Job job = Job.getInstance(configuration, this.getClass().getSimpleName()); job.setJarByClass(this.getClass());
//set job
//input:
Path inpath = new Path(args[0]); FileInputFormat.addInputPath(job, inpath);
//output
Path outPath = new Path(args[1]); FileOutputFormat.setOutputPath(job, outPath); //mapper
job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //reducer
job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
//submit job
boolean isSucess = job.waitForCompletion(true);
return isSucess ? 0 : 1;
}
public static void main(String[] args) throws Exception { args = new String [] {
"hdfs://bigdata-senior01.beifeng.com:8020/user/beifeng/input",
"hdfs://bigdata-senior01.beifeng.com:8020/user/beifeng/output13"};
//run job
int status = new WordCountMapReduce().run(args); System.exit(status);
}
}
打成jar包在yarn上运行
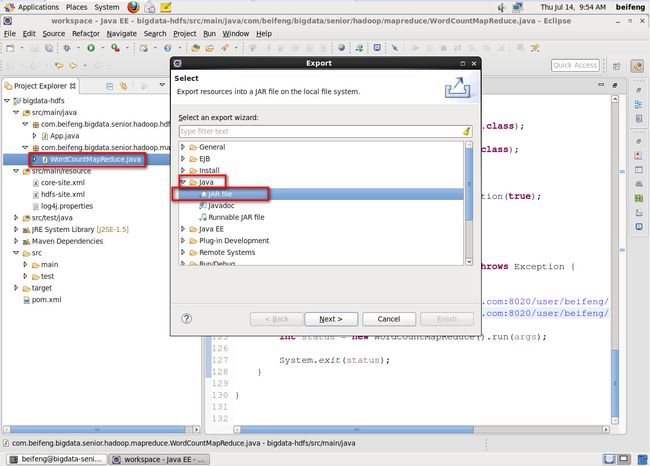
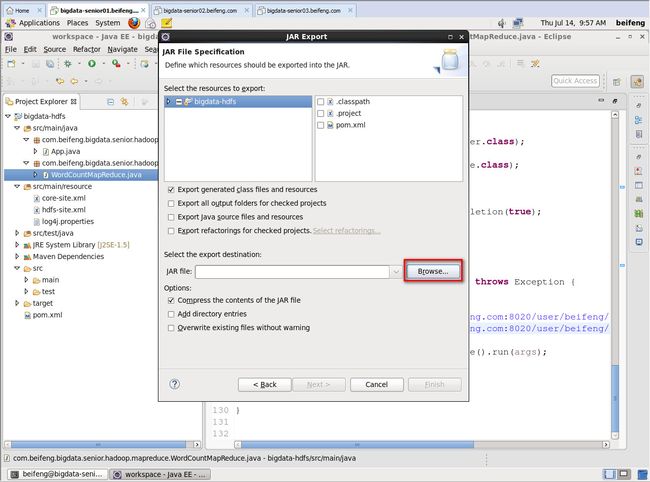
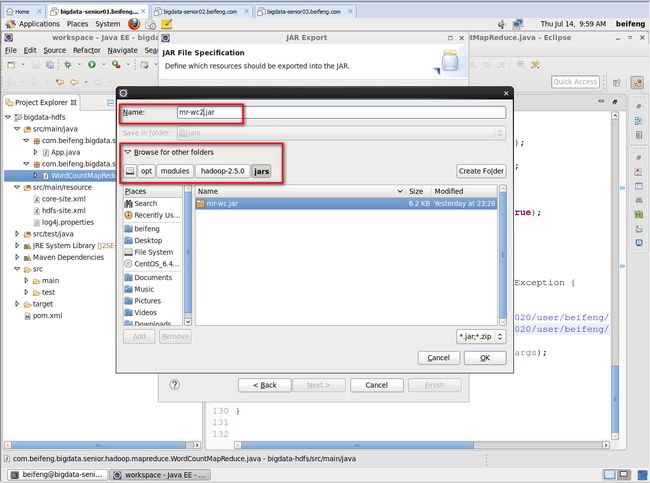
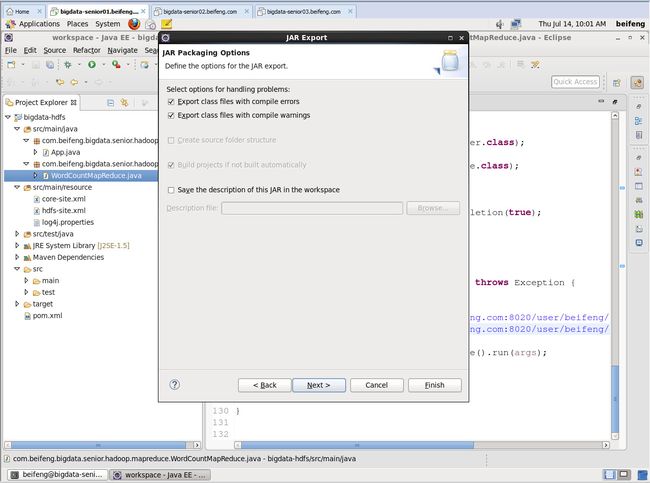
bin/yarn jar jars/mr-wc2.jar /user/beifeng/input /user/beifeng/output121
