Kafka简介
Kafka由scala编写,提供java.scalaAPI,它是一个分布式消息队列,一般用来缓存数据,还可以实现拦截器的功能,过滤某些自定义数据, 而Storm / Streaming通过消费Kafka内的数据进行计算. 内部有序,外部分区无序,消费者也有可以有组.
1.Kafka允许您发布和订阅流记录。在这方面,它类似于一个消息队列或企业消息传递系统。
2.Kafka能让你以容错方式进行流记录的存储。
3.数据产生时你就可以进行流数据处理。
Kafka架构
Kafka有自己的一套API: Consumer;
Kafka对消息保存时根据 Topic(可以理解为一个队列) 进行归类,发送(消息)者称为 Producer,消费(消息)者称为 Consumer,此外kafka集群有多个kafka实例组成,每个实例 (server)成为 broker。
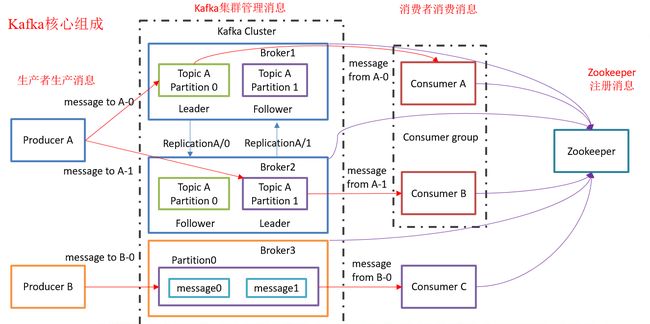
1. Producer :消息生产者,就是向kafka broker发消息的客户端。 B配置的是1个分区
2. Consumer :消息消费者,向kafka broker取消息的客户端
3. Topic:可以理解为一个队列
4. Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic
5. Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic
6. Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
7. Offset:(一个角标,找文件的角标)kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
Kafka环境搭建
Kafka是集群,所以节点上都要安装.
Kafka依赖zookeeper来保存一些meta信息,依次来保证系统的可用性.
注: 面对JDK.Hadoop.zookeeper都默认好的
1. 官网下载Kafka kafka.apache.org/downloads.html
2. 解压包到modules路径下
3. cd进入kafka目录下,且在此目录下创建logs文件夹
4. 进入config目录下,编辑server.properties,编辑内容如下:
briker.id=0 //broker的全局唯一编号,不能重复,每个节点要一个唯一标识id
delete.topic.enable=true //删除topic的功能使能
log.dirs=/opt/modules/kafka_2.11-0.11.0.0/logs //Kafka运行日志存放的路径
//下面是配置连接zookeeper的集群地址,端口号2181
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181
5. 修改vi /etc/profile
export KAFKA_HOME=/opt/module/kafka //配置KAFKA_HOME
export PATH=$PATH:$KAFKA_HOME/bin
6. 分发安装包 xsync profile //xsync是我写的分发脚本,没有的就用命令一个个分发..
7. 在分发的节点上修改brokerid=1 / brokerid=2 //不得重复
server.properties下的参数解读
num.network.threads=3 //处理网络请求的线程数量
num.io.threads=8 //用来处理磁盘IO的现成数量
socket.send.buffer.bytes=102400 //接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400 //接收套接字的缓冲区大小
socket.request.max.bytes=104857600 //请求套接字的缓冲区大小
num.partitions=1 //topic在当前broker上的分区个数
num.recovery.threads.per.data.dir=1 //用来恢复和清理data下数据的线程数量
log.retention.hours=168 //segment文件保留的最长时间,超时将被删除
Kafka命令行操作
启动kafka: bin/kafka-server-start.sh config/server.properties //所有节点都要启动
查看服务器中所有topic: bin/kafka-topics.sh --list --zookeeper hadoop101:2181
创建topic: bin/kafka-topics.sh --create --zookeeper hadoop101:2181 --replication-factor 3 --partitions 1--topic first //有多少个节点就最多创建多少个副本
分组: bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first --consumer.config config/consumer.properties
注: --topic定义topic名 --replication-factor定义副本数 --partitions定义分区数 //针对以上两个
删除topic: bin/kafka-topics.sh --delete --zookeeperhadoop101:2181 --topic first
Kafka生产过程分析
写入流程

1. producer先从zookeeper的"/brokers/.../state"节点找到该partition的leader
2. producer将消息发送给该leader
3. leader将消息写入本地log
4. followers从leader pull消息,写入本地log后向leader发送ACK
5. leader收到所有ISR中的replication的ACK后,增加HW(highwatermark,最后commit的offset)并向producer发送ACK
Kafka的存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
1. 基于时间:log.retention.hours=168
2. 基于大小:log.retention.bytes=1073741824
Kafka Stream
Kafka Streams是什么: Apache Kafka开源项目的一个组成部分。是一个功能强大,易于使用的库。用于在Kafka上构建高可分布式、拓展性,容错的应用程序。它建立在流处理的一系列重要功能基础之上,比如正确区分事件和处理时间,处理迟到数据以及高效的应用程序状态管理。
特点1: 功能强大
高拓展性 / 弹性 / 容错 / 有状态和无状态处理 / 基于事件时间的Window,Join,Aggergations
特点2: 轻量级
无需专门的集群 / 一个库,而不是框架
特点3: 完全集成
100%的Kafka 0.10.0版本兼容 / 易于集成到现有的应用程序 / 程序部署无需手工处理(这个指的应该是Kafka多分区机制对Kafka Streams多实例的自动匹配)
特点4: 实时性
毫秒级延迟 / 并非微批处理 / 窗口允许乱序数据 / 允许迟到数据
它的缺点: Kafka Stream能做的东西Storm和Spark Streamin已经完美解决了,况且Streamin有一个Saprk这么好的生态圈,要Kafka Stream是锦上添花,增加学习成本(其实使我不会Kafka Stream)...