
用readelf实验一下
我们终于可以开始readelf部分的实验了。 在我们开始之前,请修改S2E配置文件,仅启用以下的插件:
BaseInstructions
HostFiles
VMI
TranslationBlockCoverage
ModuleExecutionDetector
ForkLimiter
ProcessExecutionDetector
LinuxMonitor
我们还必须修改bootstrap.sh。
在${S2EGET} “readelf”下添加$
{S2EGET}“small_exec.elf”以便将测试用例复制到客户机。为了使用我们的测试用例,在prepare_inputs函数中,将truncate
-s 256 $ {SYMB_FILE}替换为cp small_exec.elf $ {SYMB_FILE}。
还不用替换symbfile命令; 让我们先来看一下readelf如何在一个完全符号化的文件上执行。
运行S2E一分钟左右,然后结束进程。 你应该看到很多分叉的情况(我这里是136种情况)。 让我们生成代码覆盖信息:
# The actual disassembler isn't important
s2e coverage basic_block --disassembler=binaryninja readelf_kaitai
这些分支情况发生在哪?
由于readelf调用在符号化数据时调用了printf,所以libc中有很多。 readelf 自身的分支呢?
下面的图片显示了readelf中的两个函数的片段:process_section_headers和init_dwarf_regnames。
绿色的部分表示由S2E执行的块。 分支节点受到的约束已由注释说明(KLEE中的KQuery格式):
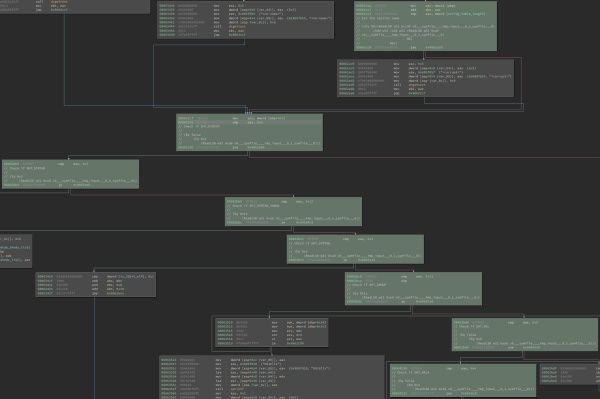
readelf's process_section_headers 代码覆盖
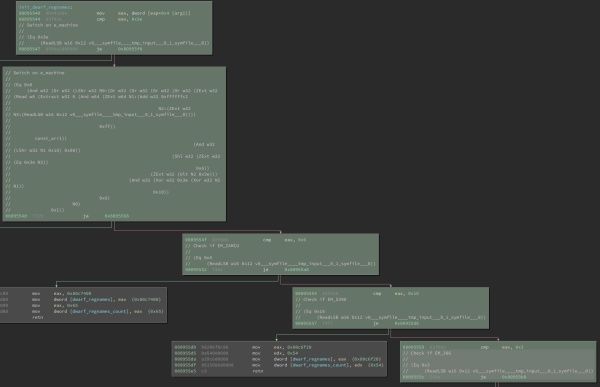
readelf's init_dwarf_regnames 代码覆盖
当检查到下列情况也会发生分叉:
如果输入文件是一份存档
数据编码(小端或大端字节序)
section header 表的文件偏移量
如果每个部分的sh_link和sh_info值都是有效的
还有许多其他的地方!眼下只对留下那些与ELF头部的e_machine字段有关的程序路径。编辑bootstrap.sh并用./s2e_kaitai_cmd
${SYMB_FILE}替换${S2ECMD} symbfile
${SYMB_FILE}。现在重新运行S2E一分钟。在运行期间,分支情况仅限于get_machine_name和init_dwarf_regnames函数,这两个函数都是取决于e_machine的值的switch语句。成功了!
让我们尝试在ELF文件中换一个不同的字段 -section header 的sh_type字段。不像e_machine字段,只会在ELF文件中出现一次。sh_type可以在整个文件中出现多次(取决于ELF文件中section的数量)。
我们必须将S2E执行状态和输入文件的起始地址传播到ELF声明中的相对应的属性中。这次我们必须将params
spec添加到section_header类型中。
type属性定义为无符号的4字节枚举类型,因此我们必须将其更改为4字节的数组类型,以便我们可以使用s2e_make_symbolic:
# Elf(32|64)_Shdr
section_header:
params:
- id: s2e_state
- id: start_addr
seq:
# sh_name
- id: name_offset
type: u4
# sh_type
- id: type
size: 4
process: s2e_make_symbolic(s2e_state, start_addr, _io.pos, "sh_type")
# ...
我们还必须确保将这两个参数传递给SectionHeader的构造函数。 section头可以在section_headers实例下找到:
# The original section_headers
section_headers:
pos: section_header_offset
repeat: expr
repeat-expr: qty_section_header
size: section_header_entry_size
type: section_header
# Redefined for symbolic execution
section_headers:
pos: section_header_offset
repeat: expr
repeat-expr: qty_section_header
size: section_header_entry_size
type: section_header(s2e_state, start_addr)
注意section_headers被声明为“实例规范”。
这意味着section_headers只能根据需要将要解析section头部的函数编译为一个函数。
因此,我们必须访问section_headers以强制解析它们。
为此,我们必须修改s2e-config.lua中的make_elf_symbolic函数:
function make_symbolic_elf(state, start_addr, buffer)
-- ...
-- This will kick-start the parser. However, now we do care about the final
-- result, because we must access the section headers to force them to be
-- parsed
local elf_file = Elf(state, start_addr, KaitaiStream(ss))
-- This will kick-start the section header parser
_ = elf_file.header.section_headers
end
运行ksc再次重新生成elf.lua。 在我们重新运行S2E之前,我们来看下elf.lua。 特别是在section_headers中的get方法中解析的section头部:
function Elf.EndianElf.property.section_headers:get()
-- ...
for i = 1, self.qty_section_header do
self._raw__m_section_headers[i] = \
self._io:read_bytes(self.section_header_entry_size)
local _io = KaitaiStream(stringstream(self._raw__m_section_headers[i]))
self._m_section_headers[i] = Elf.EndianElf.SectionHeader(self.s2e_state,
self.start_addr,
_io, self,
self._root,
self._is_le)
end
-- ...
end
注意到ksc创建一个局部变量_io,它被传递给SectionHeader构造函数。 这个_io变量包含最终将被转换成SectionHeader对象的原始数据。 不幸的是,这会导致s2e_make_symbolic出现处理规范方面的问题。
回想一下,解析器的当前位置(_io.pos)被传递给s2e_make_symbolic处理规范。 但是糟糕的是当创建本地_io流时,这个地址将清零,因此符号化的时候使用这个地址会造成错误的内存地址。 不过,我们可以通过对稍微修改下Lua代码来解决这个问题:
for i = 1, self.qty_section_header do
-- Get the absolute start address of the section header before it is parsed
local _sec_hdr_start_addr = self.start_addr + self._io:pos()
self._raw__m_section_headers[i] = \
self._io:read_bytes(self.section_header_entry_size)
local _io = KaitaiStream(stringstream(self._raw__m_section_headers[i]))
-- Use the section header's start address instead of the ELF's start address
self._m_section_headers[i] = Elf.EndianElf.SectionHeader(self.s2e_state,
_sec_hdr_start_addr,
_io, self,
self._root,
self._is_le)
end
是的,修改生成的Lua代码是令人厌恶的。但是,它确保了符号化时的内存地址是正确的。当我重新编译S2E时,分支被限制在process_section_headers函数中的sh_type比较部分。
总结和未来的工作
在这篇文章中,探讨了如何更有针对性的执行文件解析器的符号执行问题。我们可以使用Kaitai Struct来定位输入文件的特定部分来进行符号化,而非给解析器一个完全符号的输入文件(这会很快导致路径爆炸问题)。这种方法似乎奏效,但还是有些问题。
首先,首先,它依赖于用户有一个有效的样例文件来执行符号执行。
。这个样例文件还必须包含我们希望运行的解析器部分的数据。比如,假设我们想将此技术应用于PNG解析器。如果我们拿这个PNG文件的定义,并希望看到当bkgd_truecolor属性符号化时发生了什么,我们的PNG文件也必须包含一个背景颜色块。否则我们的解析器将没有符号化的东西。
由于类似的原因,我们不能仅仅使用S2E引导脚本创建的“空”的符号文件。为当Kaitai Struct解析器执行时,它运行在文件中的具体数据上。 S2E创建的默认符号文件用NULL字符填充,因此解析器无法解析。如果我们可以凭空创造出文件,是不是会很酷?
其他问题取决于我们如何使用Kaitai
Struct。这不是Kaitai Struct的错误;实际上,Kaitai Struct
FAQ明确指出,生成的解析器本来就不是为了“基于事件”的解析模型而设计的。我们可以修改ksc来生成基本不需要手动修改的代码(例如,自动生成参数规范,使用非延迟的实例规范,始终跟踪解析器的绝对路径等等),但是为了简单起见不去考虑Kaitai
Struct “原本的样子”。
不是基于文件的符号执行怎么办?例如,在我之前的帖子中,我展示了如何使用S2E来解决使用命令行字符串作为输入的CTF挑战。这篇文章中描述的方法对解决这个CTF的挑战是没有帮助的。同样我们可以扩展KaitaiStruct插件来处理命令行字符串。例如,我们可以在Kaitai
Struct中定义CTF挑战的输入字符串如下:
meta:
id: ctf-input
title: Google CTF input format
ks-version: 0.8
seq:
- id: prefix
size: 4
contents: "CTF{"
- id: to_solve
size: 63 # total length of 67 bytes minus the 4 byte prefix
process: s2e_make_symbolic(s2e_state, start_addr, _io.pos, "to_solve")
params:
- id: s2e_state
- id: start_addr
加上一些额外的代码,我们可以在输入字符串上的运行此解析器,只将最后63个字节符号化。 这将允许我们从S2E插件中删除onSymbolicVariableCreation方法。
尽管出现了这些问题,但是把S2E和Kaitai
Struct组合起来似乎对我目前正在做的工作(尽管你的目的可能会有所不同)还是很有帮助的。 我们可以通过更多的工作(更多的代码)来解决这些问题。 所以,我想我会把那作为一个未来的帖子:)
本文由看雪翻译小组 fyb波 编译,来源Adrian's Ramblings 转载请注明来自看雪社区