序列化
我们先来看下hadoop官网上给的MapReduce统计词频的示例:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
我们可以看到如:
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
为什么不直接试用int,string而要采用IntWritable和Text呢?这就涉及到了序列化。
序列化
- 什么是序列化?
将结构化对象转换成字节流以便于进行网络传输或写入持久存储的过程。
- 什么是反序列化?
将字节流转换为一系列结构化对象的过程。 - 序列化用途
- 作为一种持久化格式。
- 作为一种通信的数据格式。
- 作为一种数据拷贝、克隆机制。
- Java序列化和反序列化
- 创建一个对象实现了Serializable
- 序列化:ObjectOutputStream.writeObject(序列化对象)。反序列化:ObjectInputStream.readObject()返回序列化对象
序列化 - 为什么Hadoop不直接使用java序列化?
Hadoop的序列化机制与java的序列化机制不同,它将对象序列化到流中,值得一提的是java的序列化机制是不断的创建对象,但在Hadoop的序列化机制中,用户可以复用对象,这样就减少了java对象的分配和回收,提高了应用效率。
Hadoop定义了这样一个Writable接口:
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
| Java基本类型 | Writable | 序列化后长度 |
|---|---|---|
| 布尔型(boolean) | BooleanWritable | 1 |
| 字节型(byte) | ByteWritable | 1 |
| 整型(int) | IntWritable VIntWritable |
4 1~5 |
| 浮点型(float) | FloatWritable | 4 |
| 长整型(long) | LongWritable VLongWritable |
8 1~9 |
| 双精度浮点型(double) | DoubleWritable | 8 |
一个类要支持可序列化只需实现这个接口即可。下面是Writable类的层次结构。
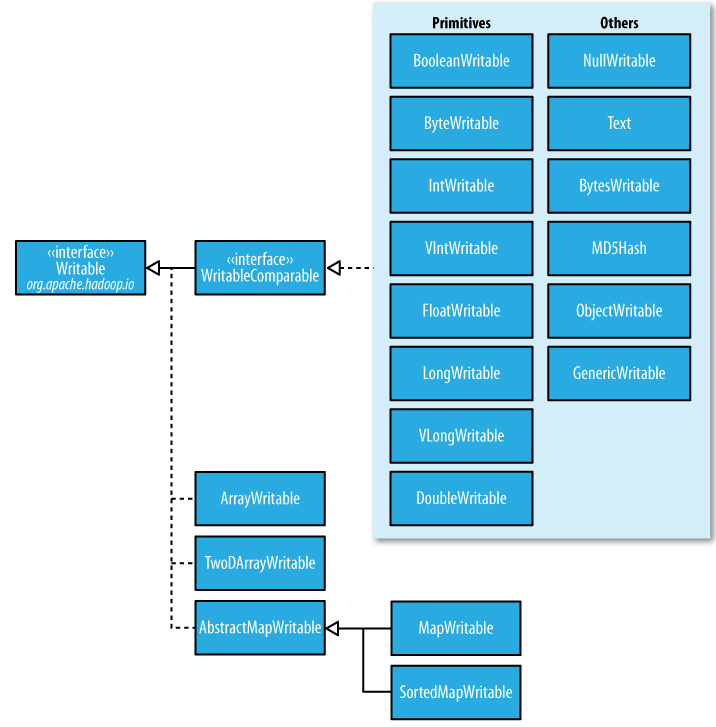
目前Java基本类型对应的Writable封装如下表所示。所有这些Writable类都继承自WritableComparable。也就是说,它们是可比较的。同时,它们都有get()和set()方法,用于获得和设置封装的值。
Java基本类型对应的Writable封装
| Java基本类型 | Writable | 序列化后长度 |
|---|---|---|
| 布尔型(boolean) | BooleanWritable | 1 |
| 字节型(byte) | ByteWritable | 1 |
| 整型(int) | IntWritable VIntWritable |
4 1~5 |
| 浮点型(float) | FloatWritable | 4 |
| 长整型(long) | LongWritable VLongWritable |
8 1~9 |
| 双精度浮点型(double) | DoubleWritable | 8 |
在表中,对整型(int和long)进行编码的时候,有固定长度格式(IntWritable和LongWritable)和可变长度格式(VIntWritable和VLongWritable)两种选择。固定长度格式的整型,序列化后的数据是定长的,而可变长度格式则使用一种比较灵活的编码方式,对于数值比较小的整型,它们往往比较节省空间。同时,由于VIntWritable和VLongWritable的编码规则是一样的,所以VIntWritable的输出可以用VLongWritable读入。
WritableComparable接口扩展了Writable和Comparable接口,以支持比较。正如层次图中看到,IntWritable、LongWritable、ByteWritable等基本类型都实现了这个接口。IntWritable和LongWritable的readFields()都直接从实现了DataInput接口的输入流中读取二进制数据并分别重构成int型和long型,而write()则直接将int型数据和long型数据直接转换成二进制流。IntWritable和LongWritable都含有相应的Comparator内部类,这是用来支持对在不反序列化为对象的情况下对数据流中的数据单位进行直接的,这是一个优化,因为无需创建对象。
定长Writable
IntWritable
package org.apache.hadoop.io;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for ints. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class IntWritable implements WritableComparable {
private int value;
public IntWritable() {}
public IntWritable(int value) { set(value); }
/** Set the value of this IntWritable. */
public void set(int value) { this.value = value; }
/** Return the value of this IntWritable. */
public int get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(value);
}
/** Returns true iff o is a IntWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof IntWritable))
return false;
IntWritable other = (IntWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return value;
}
/** Compares two IntWritables. */
@Override
public int compareTo(IntWritable o) {
int thisValue = this.value;
int thatValue = o.value;
return (thisValue 代码中的static块调用WritableComparator的static方法define()用来注册上面这个Comparator,就是将其加入WritableComparator的comparators成员中,comparators是HashMap类型且是static的。这样,就告诉WritableComparator,当我使用WritableComparator.get(IntWritable.class)方法的时候,你返回我注册的这个Comparator给我[对IntWritable来说就是IntWritable.Comparator],然后我就可以使用comparator.compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)来比较b1和b2,而不需要将它们反序列化成对象[像下面代码中]。comparator.compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)中的readInt()是从WritableComparator继承来的,它将IntWritable的value从byte数组中通过移位转换出来。
RawComparator comparator = WritableComparator.get(IntWritable.class);
comparator.compare(b1,0,b1.length,b2,0,b2.length);
BooleanWritable
package org.apache.hadoop.io;
import java.io.*;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/**
* A WritableComparable for booleans.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class BooleanWritable implements WritableComparable {
private boolean value;
/**
*/
public BooleanWritable() {};
/**
*/
public BooleanWritable(boolean value) {
set(value);
}
/**
* Set the value of the BooleanWritable
*/
public void set(boolean value) {
this.value = value;
}
/**
* Returns the value of the BooleanWritable
*/
public boolean get() {
return value;
}
/**
*/
@Override
public void readFields(DataInput in) throws IOException {
value = in.readBoolean();
}
/**
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeBoolean(value);
}
/**
*/
@Override
public boolean equals(Object o) {
if (!(o instanceof BooleanWritable)) {
return false;
}
BooleanWritable other = (BooleanWritable) o;
return this.value == other.value;
}
@Override
public int hashCode() {
return value ? 0 : 1;
}
/**
*/
@Override
public int compareTo(BooleanWritable o) {
boolean a = this.value;
boolean b = o.value;
return ((a == b) ? 0 : (a == false) ? -1 : 1);
}
@Override
public String toString() {
return Boolean.toString(get());
}
/**
* A Comparator optimized for BooleanWritable.
*/
public static class Comparator extends WritableComparator {
public Comparator() {
super(BooleanWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
return compareBytes(b1, s1, l1, b2, s2, l2);
}
}
static {
WritableComparator.define(BooleanWritable.class, new Comparator());
}
}
ByteWritable
package org.apache.hadoop.io;
import java.io.*;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for a single byte. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class ByteWritable implements WritableComparable {
private byte value;
public ByteWritable() {}
public ByteWritable(byte value) { set(value); }
/** Set the value of this ByteWritable. */
public void set(byte value) { this.value = value; }
/** Return the value of this ByteWritable. */
public byte get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = in.readByte();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeByte(value);
}
/** Returns true iff o is a ByteWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof ByteWritable)) {
return false;
}
ByteWritable other = (ByteWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return (int)value;
}
/** Compares two ByteWritables. */
@Override
public int compareTo(ByteWritable o) {
int thisValue = this.value;
int thatValue = o.value;
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
@Override
public String toString() {
return Byte.toString(value);
}
/** A Comparator optimized for ByteWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(ByteWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
byte thisValue = b1[s1];
byte thatValue = b2[s2];
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
}
static { // register this comparator
WritableComparator.define(ByteWritable.class, new Comparator());
}
}
LongWritable
package org.apache.hadoop.io;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for longs. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class LongWritable implements WritableComparable {
private long value;
public LongWritable() {}
public LongWritable(long value) { set(value); }
/** Set the value of this LongWritable. */
public void set(long value) { this.value = value; }
/** Return the value of this LongWritable. */
public long get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = in.readLong();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(value);
}
/** Returns true iff o is a LongWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof LongWritable))
return false;
LongWritable other = (LongWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return (int)value;
}
/** Compares two LongWritables. */
@Override
public int compareTo(LongWritable o) {
long thisValue = this.value;
long thatValue = o.value;
return (thisValue FloatWritable
package org.apache.hadoop.io;
import java.io.*;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for floats. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class FloatWritable implements WritableComparable {
private float value;
public FloatWritable() {}
public FloatWritable(float value) { set(value); }
/** Set the value of this FloatWritable. */
public void set(float value) { this.value = value; }
/** Return the value of this FloatWritable. */
public float get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = in.readFloat();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeFloat(value);
}
/** Returns true iff o is a FloatWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof FloatWritable))
return false;
FloatWritable other = (FloatWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return Float.floatToIntBits(value);
}
/** Compares two FloatWritables. */
@Override
public int compareTo(FloatWritable o) {
float thisValue = this.value;
float thatValue = o.value;
return (thisValue DoubleWritable
package org.apache.hadoop.io;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/**
* Writable for Double values.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class DoubleWritable implements WritableComparable {
private double value = 0.0;
public DoubleWritable() {
}
public DoubleWritable(double value) {
set(value);
}
@Override
public void readFields(DataInput in) throws IOException {
value = in.readDouble();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeDouble(value);
}
public void set(double value) { this.value = value; }
public double get() { return value; }
/**
* Returns true iff o is a DoubleWritable with the same value.
*/
@Override
public boolean equals(Object o) {
if (!(o instanceof DoubleWritable)) {
return false;
}
DoubleWritable other = (DoubleWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return (int)Double.doubleToLongBits(value);
}
@Override
public int compareTo(DoubleWritable o) {
return (value < o.value ? -1 : (value == o.value ? 0 : 1));
}
@Override
public String toString() {
return Double.toString(value);
}
/** A Comparator optimized for DoubleWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(DoubleWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
double thisValue = readDouble(b1, s1);
double thatValue = readDouble(b2, s2);
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
}
static { // register this comparator
WritableComparator.define(DoubleWritable.class, new Comparator());
}
}
可见ByteWritable、BooleanWritable、FloatWritable、DoubleWritable都基本一样
不定长Writable
VLongWritable
VIntWritable和VLongWritable,这两个基本类基本一样而且VIntWritable的value编码的时候也是使用VLongWritable的value编解码时的方法,主要区别是VIntWritable对象使用int型的value成员,而VLongWritable使用long型的value成员,这是由它们的取值范围决定的。它们都没有ComParator,不像上面的类。
package org.apache.hadoop.io;
import java.io.*;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for longs in a variable-length format. Such values take
* between one and five bytes. Smaller values take fewer bytes.
*
* @see org.apache.hadoop.io.WritableUtils#readVLong(DataInput)
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class VLongWritable implements WritableComparable {
private long value;
public VLongWritable() {}
public VLongWritable(long value) { set(value); }
/** Set the value of this LongWritable. */
public void set(long value) { this.value = value; }
/** Return the value of this LongWritable. */
public long get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = WritableUtils.readVLong(in);
}
@Override
public void write(DataOutput out) throws IOException {
WritableUtils.writeVLong(out, value);
}
/** Returns true iff o is a VLongWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof VLongWritable))
return false;
VLongWritable other = (VLongWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return (int)value;
}
/** Compares two VLongWritables. */
@Override
public int compareTo(VLongWritable o) {
long thisValue = this.value;
long thatValue = o.value;
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
@Override
public String toString() {
return Long.toString(value);
}
}
从源码中我们可以发现,它编码的时候使用的是WritableUtils.writeVLong()方法,WritableUtils是关于编解码用的
VIntWritable
VIntWritable中value的编码实际也是使用writeVLong()
package org.apache.hadoop.io;
import java.io.*;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for integer values stored in variable-length format.
* Such values take between one and five bytes. Smaller values take fewer bytes.
*
* @see org.apache.hadoop.io.WritableUtils#readVInt(DataInput)
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class VIntWritable implements WritableComparable {
private int value;
public VIntWritable() {}
public VIntWritable(int value) { set(value); }
/** Set the value of this VIntWritable. */
public void set(int value) { this.value = value; }
/** Return the value of this VIntWritable. */
public int get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = WritableUtils.readVInt(in);
}
@Override
public void write(DataOutput out) throws IOException {
WritableUtils.writeVInt(out, value);
}
/** Returns true iff o is a VIntWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof VIntWritable))
return false;
VIntWritable other = (VIntWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return value;
}
/** Compares two VIntWritables. */
@Override
public int compareTo(VIntWritable o) {
int thisValue = this.value;
int thatValue = o.value;
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
@Override
public String toString() {
return Integer.toString(value);
}
}
WritableUtils
writeVLong()
VIntWritable的长度是1-5,VLongWritable的长度是1-9,如果数值在[-112,127]时,使用1byte表示,即编码后的1byte存储的就是这个数值。如果不在这个范围内,则需要更多的byte,而第一个byte将被用作存储长度,其他byte存储数值。
public static void writeVLong(DataOutput stream, long i) throws IOException {
if (i >= -112 && i <= 127) {
stream.writeByte((byte)i);
return;//-112到127的数值只用一个byte
}
int len = -112;
if (i < 0) {
i ^= -1L; //连符号一起取反+1
len = -120;
}
long tmp = i;//到这里,i一定是正数
while (tmp != 0) {//然后用循环计算一下长度,i越大,实际长度就越大,偏离长度起始值[原来len]越大,len值越小。
tmp = tmp >> 8;
len--;
}
//现在,我们显然计算出了一个能表示其长度的值len,只要看其偏离长度起始值多少即可。
stream.writeByte((byte)len);
len = (len < -120) ? -(len + 120) : -(len + 112);//计算出了长度,不包含第一个byte【表示长度的byte】
for (int idx = len; idx != 0; idx--) {//这里将i的二进制码从左到右8位8位的拿出来,然后写入到流中。
int shiftbits = (idx - 1) * 8;
long mask = 0xFFL << shiftbits;
stream.writeByte((byte)((i & mask) >> shiftbits));
}
}
readVLong()
public static long readVLong(DataInput stream) throws IOException {
byte firstByte = stream.readByte();
int len = decodeVIntSize(firstByte);
if (len == 1) {
return firstByte;
}
long i = 0;
for (int idx = 0; idx < len-1; idx++) {
byte b = stream.readByte();
i = i << 8;
i = i | (b & 0xFF);
}
return (isNegativeVInt(firstByte) ? (i ^ -1L) : i);
}
这显然就是读出字节表示长度,然后从输入流中一个byte一个byte读出来,&0xFF是为了不让系统自动类型转换,然后在^-1L即连符号一起取反。
decodeVIntSize()
public static int decodeVIntSize(byte value) {
if (value >= -112) {
return 1;
} else if (value < -120) {
return -119 - value;
}
return -111 - value;
}
使用了-119和-111只是为了获取编码长度而不是实际数值长度
WritableComparator
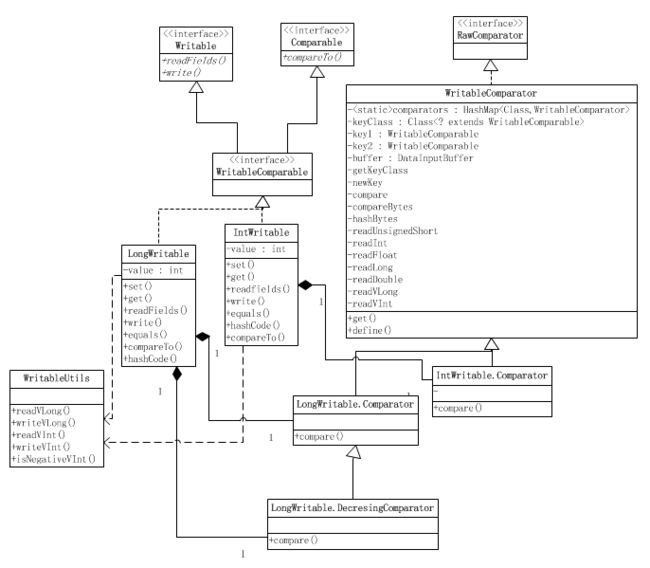
WritableComparator是RawComparator实例的工厂,注册了的Writable的实现类,它为这些Writable实现类提供了反序列化用的方法。Writable还提供了compare()的默认实现,它会反序列化才比较。
如果WritableComparator.get()没有得到注册的Comparator,则会创建一个新的Comparator,其实是WritableComparator的实例,然后当你使用 public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)进行比较,它会去使用你要比较的Writable的实现的readFields()方法读出value来。
比如,VIntWritable没有注册,我们get()时它就构造一个WritableComparator,然后设置key1,key2,buffer,keyClass,当你使用 public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) ,则使用VIntWritable.readField从编码后的byte[]中读取value值再进行比较。
package org.apache.hadoop.io;
import java.io.DataInput;
import java.io.IOException;
import java.util.concurrent.ConcurrentHashMap;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configurable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.util.ReflectionUtils;
/** A Comparator for {@link WritableComparable}s.
*
* This base implementation uses the natural ordering. To define alternate
* orderings, override {@link #compare(WritableComparable,WritableComparable)}.
*
*
One may optimize compare-intensive operations by overriding
* {@link #compare(byte[],int,int,byte[],int,int)}. Static utility methods are
* provided to assist in optimized implementations of this method.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class WritableComparator implements RawComparator, Configurable {
private static final ConcurrentHashMap comparators
= new ConcurrentHashMap(); // registry
private Configuration conf;
/** For backwards compatibility. **/
public static WritableComparator get(Class c) {
return get(c, null);
}
/** Get a comparator for a {@link WritableComparable} implementation. */
public static WritableComparator get(
Class c, Configuration conf) {
WritableComparator comparator = comparators.get(c);
if (comparator == null) {
// force the static initializers to run
forceInit(c);
// look to see if it is defined now
comparator = comparators.get(c);
// if not, use the generic one
if (comparator == null) {
comparator = new WritableComparator(c, conf, true);
}
}
// Newly passed Configuration objects should be used.
ReflectionUtils.setConf(comparator, conf);
return comparator;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return conf;
}
/**
* Force initialization of the static members.
* As of Java 5, referencing a class doesn't force it to initialize. Since
* this class requires that the classes be initialized to declare their
* comparators, we force that initialization to happen.
* @param cls the class to initialize
*/
private static void forceInit(Class cls) {
try {
Class.forName(cls.getName(), true, cls.getClassLoader());
} catch (ClassNotFoundException e) {
throw new IllegalArgumentException("Can't initialize class " + cls, e);
}
}
/** Register an optimized comparator for a {@link WritableComparable}
* implementation. Comparators registered with this method must be
* thread-safe. */
public static void define(Class c, WritableComparator comparator) {
comparators.put(c, comparator);
}
private final Class keyClass;
private final WritableComparable key1;
private final WritableComparable key2;
private final DataInputBuffer buffer;
protected WritableComparator() {
this(null);
}
/** Construct for a {@link WritableComparable} implementation. */
protected WritableComparator(Class keyClass) {
this(keyClass, null, false);
}
protected WritableComparator(Class keyClass,
boolean createInstances) {
this(keyClass, null, createInstances);
}
protected WritableComparator(Class keyClass,
Configuration conf,
boolean createInstances) {
this.keyClass = keyClass;
this.conf = (conf != null) ? conf : new Configuration();
if (createInstances) {
key1 = newKey();
key2 = newKey();
buffer = new DataInputBuffer();
} else {
key1 = key2 = null;
buffer = null;
}
}
/** Returns the WritableComparable implementation class. */
public Class getKeyClass() { return keyClass; }
/** Construct a new {@link WritableComparable} instance. */
public WritableComparable newKey() {
return ReflectionUtils.newInstance(keyClass, conf);
}
/** Optimization hook. Override this to make SequenceFile.Sorter's scream.
*
* The default implementation reads the data into two {@link
* WritableComparable}s (using {@link
* Writable#readFields(DataInput)}, then calls {@link
* #compare(WritableComparable,WritableComparable)}.
*/
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}
/** Compare two WritableComparables.
*
*
The default implementation uses the natural ordering, calling {@link
* Comparable#compareTo(Object)}. */
@SuppressWarnings("unchecked")
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}
@Override
public int compare(Object a, Object b) {
return compare((WritableComparable)a, (WritableComparable)b);
}
/** Lexicographic order of binary data. */
public static int compareBytes(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
return FastByteComparisons.compareTo(b1, s1, l1, b2, s2, l2);
}
/** Compute hash for binary data. */
public static int hashBytes(byte[] bytes, int offset, int length) {
int hash = 1;
for (int i = offset; i < offset + length; i++)
hash = (31 * hash) + (int)bytes[i];
return hash;
}
/** Compute hash for binary data. */
public static int hashBytes(byte[] bytes, int length) {
return hashBytes(bytes, 0, length);
}
/** Parse an unsigned short from a byte array. */
public static int readUnsignedShort(byte[] bytes, int start) {
return (((bytes[start] & 0xff) << 8) +
((bytes[start+1] & 0xff)));
}
/** Parse an integer from a byte array. */
public static int readInt(byte[] bytes, int start) {
return (((bytes[start ] & 0xff) << 24) +
((bytes[start+1] & 0xff) << 16) +
((bytes[start+2] & 0xff) << 8) +
((bytes[start+3] & 0xff)));
}
/** Parse a float from a byte array. */
public static float readFloat(byte[] bytes, int start) {
return Float.intBitsToFloat(readInt(bytes, start));
}
/** Parse a long from a byte array. */
public static long readLong(byte[] bytes, int start) {
return ((long)(readInt(bytes, start)) << 32) +
(readInt(bytes, start+4) & 0xFFFFFFFFL);
}
/** Parse a double from a byte array. */
public static double readDouble(byte[] bytes, int start) {
return Double.longBitsToDouble(readLong(bytes, start));
}
/**
* Reads a zero-compressed encoded long from a byte array and returns it.
* @param bytes byte array with decode long
* @param start starting index
* @throws java.io.IOException
* @return deserialized long
*/
public static long readVLong(byte[] bytes, int start) throws IOException {
int len = bytes[start];
if (len >= -112) {
return len;
}
boolean isNegative = (len < -120);
len = isNegative ? -(len + 120) : -(len + 112);
if (start+1+len>bytes.length)
throw new IOException(
"Not enough number of bytes for a zero-compressed integer");
long i = 0;
for (int idx = 0; idx < len; idx++) {
i = i << 8;
i = i | (bytes[start+1+idx] & 0xFF);
}
return (isNegative ? (i ^ -1L) : i);
}
/**
* Reads a zero-compressed encoded integer from a byte array and returns it.
* @param bytes byte array with the encoded integer
* @param start start index
* @throws java.io.IOException
* @return deserialized integer
*/
public static int readVInt(byte[] bytes, int start) throws IOException {
return (int) readVLong(bytes, start);
}
}