并发服务器
服务器分类
按连接类型分类
1.面向连接的服务器(如tcp)
2.面向无连接的服务器(如udp)
按处理方式分类
1.迭代服务器
2.并发服务器
“进程”基本概念
程序:存放在磁盘文件中可执行文件。
进程:程序的执行实例。它是一个动态实体,是独立的任务。“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时,它才能成为一个活动的实体,我们称其为进程。
它拥有独立的地址空间、执行堆栈、文件描述符等,一般情况下,包括代码段、数据段和堆栈段。
数据段:存放全局变量、常数以及动态数据分配的空间(malloc函数取得的空间)
代码段:存放程度代码;
堆栈段:存放子程序的返回地址、子程序参数以及程序的局部变量。
每个进程拥有独立的地址空间,进程间正常情况下,互不影响,一个进程的崩溃不会造成其他进程的崩溃。
当进程间共享某一资源时,需注意两个问题:同步问题和通信问题。
每个linux进程都一定有一个唯一的数字标识符,称为进程ID。进程ID都是一个非负整数。
创建进程
#include
#include
pid_t fork(void)
返回:父进程中返回子进程的进程ID, 子进程返回0,
-1-出错
该函数调用一次,但返回两次。两次返回的区别是子进程返回值是0,而父进程的返回值则是子进程的进程ID。
父进程中调用fork函数,在fork函数中开始的代码中首先创建一个子进程空间,然后逐步将数据段以及堆栈都拷贝过去,因为子进程的数据段以及堆栈都和父进程一样,而且创建完成后就会和父进程共享代码段,共同执行代码,所以fork创建完子进程后面的代码在子进程中也会执行,并且堆栈中也有fork函数等待返回。
在父进程中,fork返回的是子进程的进程ID ;在子进程中返回0。
fork后,子进程和父进程继续执行fork()函数后的指令,两者相互争夺系统资源,一般来说,在fork之后是父进程先执行还是子进程先执行是不确定的,这取决于内核所使用的调度算法。
父进程中调用fork之前打开的所有描述字在函数fork返回之后子进程会得到一个副本。fork后,父子进程均需要将自己不使用的描述字关闭,有两方面的原因:(1)以免出现不同步的情况;(2)最后能正常关闭描述字
#include
#include
pid_t vfork(void);
是完全共享的创建,新老进程共享同样的资源,完全没有拷贝。
当使用vfork()创建新进程时,父进程将被暂时阻塞,而子进程则可以借用父进程的地址空间。这个奇特状态将持续直到子进程退出,至此父进程才继续执行。 因此,子进程需小心处理共享变量。
终止进程
进程的终止存在两个可能:
父进程先于子进程终止(init进程领养)
子进程先于主进程终止
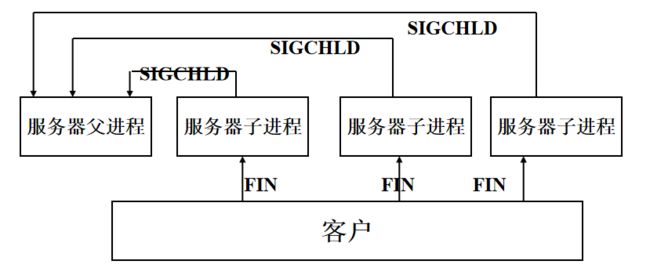
对于后者,系统内核为子进程保留一定的状态信息:进程ID、终止状态、CPU时间等;当父进程调用wait或waitpid函数时,获取这些信息,同时系统内核可以释放终止进程所使用的存储空间等;(什么叫“僵尸进程”?)
当子进程正常或异常终止时,系统内核向其父进程发送SIGCHLD信号;缺省情况下,父进程忽略该信号,或者提供一个该信号发生时即被调用的函数。
获取子进程终止信息
#include
#include
pid_t wait(int *stat_loc);
返回:终止子进程的ID-成功;-1-出错;stat_loc存储子进程的终止状态(一个整数);
如果没有终止的子进程,但是有一个或多个正在执行的子进程,则该函数将阻塞,直到有一个子进程终止或者wait被信号中断时,wait返回。
当调用该函数时,如果有一个子进程已经终止,则该系统调用立即返回,并释放子进程所有资源
pid_t waitpid(pid_t pid, int *stat_loc, int options);
返回:终止子进程的ID-成功;-1-出错;stat_loc存储子进程的终止状态;
当pid=-1,option=0时,该函数等同于wait,否则由参数pid和option共同决定函数行为,其中pid参数意义如下:
-1:要求知道任何一个子进程的返回状态(等待第一个终止的子进程);
>0:要求知道进程号为pid的子进程的状态;
<-1:要求知道进程号为pid的绝对值的子进程的终止状态
Options最常用的选项是WNOHANG,它通知内核在没有已终止进程时不要阻塞。
调用wait或waitpid函数时,正常情况下,可能会有以下几种情况:
阻塞(如果其所有子进程都还在运行);
获得子进程的终止状态并立即返回(如果一个子进程已终止,正等待父进程存取其终止状态);
出错立即返回(如果它没有任何子进程)
waitpid函数用法
pid_t pid;
if ((pid=fork()) > 0) /* parent process */
{
int child_status;
waitpid(pid, &child_status, 0);
}else if ( pid == 0 ) { /* child process */
exit(0);
}else { /* fork error */
printf(“fork error.\n”);
exit(1);
}
#include
void exit(int status);
本函数终止调用进程。关闭所有子进程打开的描述符,向父进程发送SIGCHLD信号,并返回状态
产生新的子进程后,父进程要关闭连接套接字,而子进程要关闭监听套接字,主要原因是:
关闭不需要的套接字可节省系统资源,同时可避免父子进程共享这些套接字可能带来的不可预计的后果;
另一个更重要的原因,是为了正确地关闭连接。和文件描述符一样,每个套接字描述符都有一个“引用计数”。当fork函数返回后,listenfd和connfd的引用计数变为2,而系统只有在某描述符的“引用计数”为0时,才真正关闭该描述符。
多进程并发服务器建立过程:
建立连接->服务器调用fork()产生新的子进程->父进程关闭连接套接字,子进程关闭监听套接字->子进程处理客户请求,父进程等待另一个客户连接。
多进程并发服务器模板
int main(void)
{
int listenfd, connfd;
pid_t pid;
int BACKLOG = 5;
if ((listenfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
perror(“Create socket failed.”);
exit(1);
}
bind(listenfd, …);
listen(listenfd, BACKLOG);
while(1) {
if ((connfd = accept(sockfd, NULL, NULL)) == -1) {
perror(“Accept error.”);
exit(1);
}
if((pid = fork() ) > 0){
/*parent process */
close(connfd);
…….
continue;
}
else if (pid == 0){
/*child process */
close(lisetenfd);
…….
exit(0);
}
else{
printf(“fork error\n”);
exit(1);
}
}
}
多进程服务器的问题
传统的网络服务器程序大都在新的连接到达时,fork一个子进程来处理。虽然这种模式很多年使用得很好,但fork有一些问题:
fork是昂贵的。fork时需要复制父进程的所有资源,包括内存映象、描述字等;目前的实现使用了一种写时拷贝(copy-on-write)技术,可有效避免昂贵的复制问题,但fork仍然是昂贵的;
fork子进程后,父子进程间、兄弟进程间的通信需要进程间通信IPC机制,给通信带来了困难;
多进程在一定程度上仍然不能有效地利用系统资源;
系统中进程个数也有限制。
“线程”基本概念
线程是进程内的独立执行实体和调度单元,又称为“轻量级”进程(lightwight process);创建线程比进程快10~100倍。一个进程内的所有线程共享相同的内存空间、全局变量等信息(这种机制又带来了同步问题)。而且它们还共享以下信息:

线程调用函数
#include
int pthread_create(pthread_t *tid, const pthread_attr_t *attr, void *(*func)(void *), void *arg);
返回:成功时为0;出错时为正的Exxx值
当一个程序开始运行时,系统会创建一个初始线程或主线程的单个线程。额外线程由上述函数创建;
新线程由线程id标识:tid,新线程的属性attr包括:优先级、初始栈大小、是否应该是守护线程等等。线程的执行函数和调用参数分别是:func和arg;
由于线程的执行函数的参数和返回值类型均为void *,因此可传递和返回指向任何类型的指针;
常见的返回错误值:
EAGAIN:超过了系统线程数目的限制。
ENOMEN:没有足够的内存产生新的线程。
EINVAL:无效的属性attr值。
线程或者是可联合的(joinable)(默认),或者是分离的(detached)。当可联合的线程终止时,其线程id和退出状态将保留,直到另外一个线程调用pthread_join。分离的线程则像守护进程,当它终止时,释放所有资源,我们不能等待它终止。
分离的线程退出后,系统将释放其所有资源,如果一个线程需要知道另一个线程什么时候终止,最好保留第二个线程的可联合性。
#inlcude
int pthread_join(pthread_t tid, void **status);
返回:成功时为0;出错时为正的Exxx值,不设置error
用来等待一个线程的结束。这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源被收回。如果执行成功,将返回0,如果失败则返回一个错误号。
该函数类似与waitpid函数,但必须指定等待线程的ID,该函数不能等待任意一个线程结束(如wait);
被等待线程必须是当前进程的成员,并且不是分离的线程和守护线程。
一个非分离(可联合)的线程终止后,该线程的内存资源(线程描述符和栈)并不会被释放,直到有线程对它使 用了pthread_join时才被释放。因此,必须对每个创建为非分离的线程调用一次pthread_join调用,以避免内存泄漏。
由于阻塞,代码中如果没有pthread_join主线程会很快结束从而使整个进程结束,从而使创建的线程没有机会开始执行就结束了。加入pthread_join后,主线程会一直等待直到等待的线程结束自己才结束,使创建的线程有机会执行。
pthread_t pthread_self(void);
返回:调用线程的线程id;
调用pthread_join(pthread_id)后,如果该线程没有运行结束,调用者会被阻塞,在有些情况下我们并不希望如此,比如在Web服务器中当主线程为每个新来的链接创建一个子线程进行处理的时候,主线程并不希望因为调用pthread_join而阻塞(因为还要继续处理之后到来的链接),这时可以在子线程中加入代码
pthread_detach(pthread_self())
或者父线程调用
pthread_detach(thread_id)(非阻塞,可立即返回)
这将该子线程的状态设置为detached,则该线程运行结束后会自动释放所有资源。或者进程的main函数执行完返回,也会终止终止该进程中所有线程,并释放其使用的资源。
#include
int pthread_detach(pthread_t tid)
返回:成功时为0;出错时为正Exxx值;
函数将线程分离,它设置线程的内部选项来说明线程退出后,自动释放其使用的资源。分离线程退出时不会报告它们的状态。
该函数将指定的线程变为脱离的。
pthread_detach(pthread_self());
#include
void pthread_exit(void *status);
无返回值;
线程通过调用pthread_exit函数终止执行
指针status:指向线程的退出状态。不能指向一个局部变量,因为线程终止时其所有的局部变量将被撤销;
还有其他方法可使线程终止
启动线程的函数(pthread_create的第3个参数)返回。其返回值便是线程的终止状态;
#include
int pthread_once(pthread_once_t *once_control, void (*init_routine) (void))
成功返回0,否则返回错误码
本函数作用:在本函数中,once_control变量使用的初值为PTHREAD_ONCE_INIT,可保证init_routine()函数在本进程执行序列中仅执行一次。
一般在init_routine函数中完成一些初始化工作。
LinuxThreads使用互斥锁和条件变量保证由pthread_once()指定的函数执行且仅执行一次,而once_control则表征是否执行过。如果once_control的初值不是PTHREAD_ONCE_INIT(LinuxThreads定义为0),pthread_once()的行为就会不正常;
int pthread_cancel(pthread_t tid);
返回值:成功时为0,失败为非0;
线程可以利用“取消机制”来终止另外一个线程;线程通过向另外一个线程发送取消请求,接收到取消请求的线程根据其设置状态,作出:1)忽略该请求;2)立即终止自己;3) 延迟一段时间终止自己;
互斥锁
在linux系统中,提供一种基本的进程同步机制—互斥锁,可以用来保护线程代码中共享数据的完整性。
操作系统将保证同时只有一个线程能成功完成对一个互斥锁的加锁操作。
如果一个线程已经对某一互斥锁进行了加锁,其他线程只有等待该线程完成对这一互斥锁解锁后,才能完成加锁操作。
互斥锁函数
pthread_mutex_lock(pthread_mutex_t *mptr)
返回:成功0,否则返回错误码
mptr:指向互斥锁的指针。
该函数接受一个指向互斥锁的指针作为参数并将其锁定。如果互斥锁已经被锁定,调用者将进入睡眠状态。函数返回时,将唤醒调用者。
如果互斥锁是静态分配的,就将mptr初始化为常值PTHREAD_MUTEX_INITIALIZER。
pthread_mutex_unlock(pthread_mutex_t *mptr) 用于互斥锁解锁操作。
返回:成功0,否则返回错误码
多线程并发服务器模板
void *start_routine( void *arg);
int main(void) {
int listenfd, connfd;
pthread_t tid;
type arg;
/* Create TCP socket */
……
/* Bind socket to address */
……
/* Listen */
……
while(1) {
/* Accept connection */
if ((pthread_create(&tid, NULL, start_routine, (void *)&arg))
/* handle exception */
……}
……}
给新线程传递参数
由于同一个进程内的所有线程共享内存和变量,因此在传递参数时需作特殊处理,下面参考如下几种方法:
传递参数的普通方法
通过指针传递参数
通过分配arg的空间来传递参数
还可以通过加锁等同步设施来实现传递参数;
通过指针传递参数
这种方法首先将要传递的数据转换成通用指针类型,然后传递给新线程,新线程再将其还原成原数据类型:
void *start_routine(void *arg);
int main(void) {
int connfd;
…
pthread_create(&tid, NULL, start_routine, (void *)connfd);
…
}
void *start_routine(void *arg) {
int connfd;
connfd =(int ) arg;
…
}
这种方法虽然简单,但却有很大的局限性。如:要求arg的类型必须能被正确地转换成通用指针类型,而且可传递的参数只有一个。
传递参数的普通方法
于线程创建函数只允许传递一个参数,因此当需要传递多个数据时,应首先将这些数据封装在一个结构中。
void *start_routine(void *arg);
struct ARG {
int connfd;
int other;
}
int main() {
struct ARG *arg;
…
While(1){
if((connfd = accept(sockfd,NULL,NULL))== -1){
…
}
arg.connfd = connfd;
pthread_create(&tid, NULL, start_routine, (void *)&arg);
…
}
}
void *start_routine(void *arg) {
ARG info;
info.connfd = ((ARG *)arg) -> connfd;
info.other = ((ARG *)arg) -> other;
…}
//这种方法有问题,对一个客户可以工作,但多个客户则可能出现问题。
通过分配arg的空间来传递
主线程首先为每个新线程分配存储arg的空间,再将arg传递给新线程使用,新线程使用完后要释放该空间。
void *start_routine(void *arg);
int main(void) {
struct ARG * arg;
int connfd;
…
loop {
…
if((connfd = accept(sockfd,NULL,NULL))== -1){
…
}
arg = new ARG;
arg -> connfd = connfd;
pthread_create(&tid, NULL, start_routine, (void *)arg);
…
}
}
void *start_routine(void *arg) {
struct ARG info;
info.connfd = ((ARG *)arg) ->connfd;
…
/*handle client*/
delete arg;
}
需要注意的是:与多进程并发服务器不同的是,由于多个线程间共享相同的内存空间和描述字,因此pthread_create后,不能关闭监听套接字和连接套接字,否则程序不能正常工作。(可以做试验验证)