从 ActiveMQ 5.9 开始,ActiveMQ 的集群实现方式取消了传统的Master-Slave 方式,增加了基于ZooKeeper + LevelDB的 Master-Slave实现方式,其他两种方式目录共享和数据库共享依然存在。
三种集群方式的对比:
(1)基于共享文件系统(KahaDB,默认):
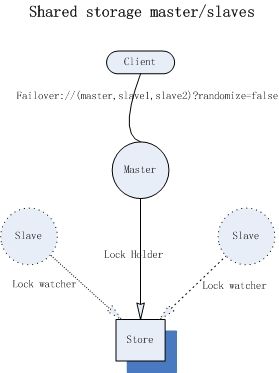
基于共享文件系统的master/slaves模式,此处所谓的“共享文件系统”目前只能是基于POSIX接口可以访问的文件系统,比如本地文件系统或者SAN分布式共享文件系统(比如:glusterFS);对于broker而言,启动时将会首先获取存储引擎的文件锁,如果获取成功才能继续初始化transportConnector,否则它将一直尝试获取锁(tryLock),那么对于共享文件系统而言,需要严格确保任何时候只能有一个进程获取排他锁,如果你选择的SAN文件系统不能保证此条件,那么将不能作为master/slavers的共享存储引擎。
“Shared File System”这种方式是最常用的模式,架构简单,可靠实用。我们只需要一个SAN文件系统即可。
在这种模式下,master与slave的配置几乎可以完全一样。如下示例中,我们使用一个master和一个slave,它们部署在一个物理机器上,使用本地文件系统作为“共享文件系统”。(仅作示例,不可用于生产环境)
对于Client端而言,可以使用failover协议来访broker:
failover://(tcp://localhost:61616,tcp://localhost:51616)?randomize=false
(2)基于 JDBC
显而易见,数据存储引擎为database,activeMQ通过JDBC的方式与database交互,排他锁使用database的表级排他锁,其他原理基本上和1)一致。JDBC Store相对于日志文件而言,通常认为是低效的,尽管数据的可见性较好,但是database的扩容能力非常的弱,无法良好的适应在高并发、大数据情况下(严格来说,单组M-S架构是无法支持大数据的),况且ActiveMQ的消息通常存储时间较短,频繁的写入,频繁的删除,都是性能的影响点。我们通常在研究activeMQ的存储原理时使用JDBC Store,或者在中小型应用中对数据一致性(可靠性,可见性)要求较高的环境中使用:比如订单系统中交易流程支撑系统等。但是因为JDBC架构的实施简便,易于管理,我们仍然倾向于首选这种方式。
在使用JDBC Store之前,必须有一个稳定的database,且指定授权给acitvemq中的链接用户具有“创建表”和普通CRUD的权限。master与slave中的配置文件基本一样,开发者需要注意brokerName和brokerId全局不可重复。此外还需要把相应的jdbc-connector的jar包copy到${acitvemq}/lib/optional目录下。
(3)基于可复制的 LevelDB(本文采用这种集群方式)
LevelDB 是 Google开发的一套用于持久化数据的高性能类库。LevelDB并不是一种服务,用户需要自 行实现Server。是单进程的服务,能够处理十亿级别规模Key-Value 型数据,占用内存小。
高可用的原理:使用ZooKeeper(集群)注册所有的ActiveMQ Broker。只有其中的一个Broker 可以提供 服务,被视为Master,其他的Broker 处于待机状态,被视为Slave。如果Master 因故障而不能提供服务,ZooKeeper 会从 Slave中选举出一个 Broker充当 Master。 Slave 连接 Master并同步他们的存储状态,Slave不接受客户端连接。所有的存储操作都将被复制到连接至 Master 的Slaves。如果 Master 宕了,得到了最新更新的 Slave 会成为 Master。故障节点在恢复后会重新加入到集群中并连接 Master 进入Slave 模式。
解释:需要同步的 disk 的消息操作都将等待存储状态被复制到其他法定节点的操作完成才能完成。所以,如果你配置了replicas=3,那么法定大小是(3/2)+1=2。Master 将会存储并更新然后等待 (2-1)=1 个Slave存储和更新完成,才汇报 success。至于为什么是 2-1,熟悉 Zookeeper 的应该知道,有一个 node要作为观擦者存在。当一个新的Master 被选中,你需要至少保障一个法定node 在线以能够找到拥有最新 状态的node。这个node 可以成为新的Master。因此,推荐运行至少3 个replica nodes,以防止一个node失败了,服务中断。(原理与 ZooKeeper 集群的高可用实现方式类似)
Replicated LevelDB”也同样允许有多个Slaves,而且Slaves的个数有了约束性的限制,这归结于其使用zookeeper作为Broker master选举。每个Broker实例将消息数据保存本地(类似于“Shared nothing”),它们之间并不共享任何数据,所以把“Replicated LevelDB”归类为“Shared storage”并不妥当。
当Broker启动时,它首先向zookeeper注册自己的信息(brokerName,消息日志的版本戳等),如果此时group中没有其他broker实例,并阻塞初始化过程,等到足够多的broker加入group;当brokers的数量达到“replicas的多数派"时,开始选举,选举将会根据“消息日志的版本戳”、“权重"的大小决定,即“版本戳”越大(数据最新)、权重越高的broker优先成为master,其他broker作为slave并跟随master。当一个broker成为master时,它会向zookeer注册自己的sync地址信息;此后slaves首先根据sync地址与master建立链接,并同步消息文件(download)。当足够多的slave数据同步结束后,master将初始化transportConnector,此后Client将可以与master进行数据交互。
Setup ActiveMQ
Go to ZOOKEEPER_HOME
Replace persistenceAdapter from kahaDB to replicatedLevelDB
Master-slaves集群中,所有的broker必须具有相同的brokerName,它作为group域来限定集群的成员,brokerId可以不同,它仅作为描述信息。“replicas”参数非常重要,默认为3,表示消息最多可以备份在几个broker实例上,同是只有当“replicas/2 + 1”个broker存活时(包含master),集群才有效,才会选举master和备份消息,此值必须>=2。Client发送给Master的持久化消息(包括ACK和事务),master首先在本地保存,然后立即同步(sync)给选定的(replicas/2)个slaves,只有当这些节点也同步成功后,此消息的交互才算结束;对于剩下的replicas个节点,master采用异步的方式(async)转发。这种设计要求,可以保证集群中消息的可靠性,只有当(replicas/2 + 1)个节点物理故障,才会有丢失消息的风险。通常replicas为3,这要求开发者需要至少部署3个broker实例。如果replicas过大,会严重影响master的吞吐能力,因为它在sync消息的过程中会消耗太多的时间。

如果集群故障,在重启broker实例时,建议首先查看每个broker中查看LevelDB日志文件的版本戳(文件名为16进制数字),并优先启动版本戳较大的实例。(因为replicas多数派的约束,随机重启也不会有太大的问题)。但是不得随意调小replicas的值,如果你确实需要修改,那就首先关闭集群,一定优先启动版本戳最大的broker。
尽管集群对zookeeper的操作并不是很多,但是我们还是希望不要接入负载过高的zookeeper集群,以免给消息服务引入不稳定因素。通常zookeeper集群至少需要3个实例,才能保证zookeeper本身的高可用性。
其中bind属性表示当此broker实例成为master时,开启一个socket地址,此后slave可以通过此地址与其同步数据。
我们还需要为Replicated LevelDB配置zookeeper的地址和path,其中path下用来存储group中所有broker的注册信息,此值在group中所有的broker上都要一样。“hostname”用来描述当前机器的核心信息,通常为机器IP。如果你在本机构建伪分布式,那么需要在系统hosts文件中使用转义。
127.0.0.1 broker0
127.0.0.1 broker1
127.0.0.1 broker2
对于Client端而言,仍然需要使用failover协议,而且协议中需要包含group中所有broker的链接地址。
failover://(tcp://localhost:61616,tcp://localhost:51616,tcp://localhost:41616)?randomize=false
和其他模式一样,对于非持久化消息仍然只会保存在master上,当master失效后,消息将会丢失
Start Zookeeper and ActiveMQ
sudo ZOOKEEPER_HOME/bin/zkServer.sh start
sudo ACTIVEMQ_HOME/bin/activemq start
Connecting to HA ActiveMQ
Given the setup above are performed without any errors, you can configure the ActiveMQ client to connect to this broker URL:
failover:(tcp://hostname1:61616,tcp://hostname2:61616,tcp://hostname3:61616)
zookeeper 只是