一、mysql性能优化
1.查询缓存
当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
// 查询缓存不开启
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// 开启查询缓存
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而 开启缓存。
2.当只获取一行数据时用 Limit 1
3.为搜索字段建索引
索引分类:
a.普通索引----这是最基本的索引,它没有任何限制,MyIASM中默认的BTREE类型的索引,也是我们大多数情况下用到的索引。
CREATE INDEX index_name ON table(column(length))
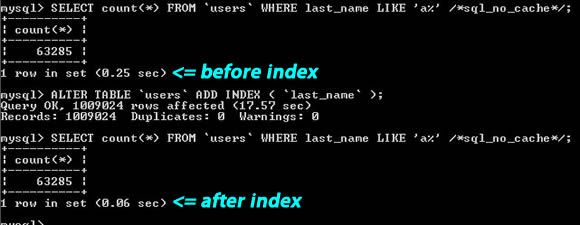
b.唯一索引----与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值(注意和主键不同)。
CREATE UNIQUE INDEX indexName ON table(column(length))
c.全文索引(FULLTEXT)----FULLTEXT索引仅可用于 MyISAM 表,他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,或是随后使用ALTER TABLE 或CREATE INDEX被添加。
–创建表的适合添加全文索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
FULLTEXT (content)
);
–修改表结构添加全文索引
ALTER TABLE article ADD FULLTEXT index_content(content)
–直接创建索引
CREATE FULLTEXT INDEX index_content ON article(content)
但是对于较大的数据来说往一个用于FULLTEXT的表中插入数据非常消耗时间和硬盘空间。
d.单列索引、多列索引----多个单列索引与单个多列索引的查询效果不同,因为执行查询时,MySQL只能使用一个索引,会从多个索引中选择一个限制最为严格的索引。
e.组合索引----例如上表中针对title和time建立一个组合索引
ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10))
4.使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
5.尽可能的使用 NOT NULL
NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.
NULL需要额外的空间
6.字段长度固定
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
7.避免 select *、count()
8.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
9.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
10.in 和 not in 也要慎用,否则会导致全表扫描。
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
11.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
select id from t where num/2=100
应改为:
select id from t where num=100*2
12.很多时候用 exists 代替 in 是一个好的选择。
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
14.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
15.拆分大的 DELETE 或 INSERT 语句。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
二、mysql优化分析
1.使用explain语句去查看分析结果
explain命令的使用十分简单,只需要"explain + sql语句"即可
explain select * from test1 where id=1;
会出现:id selecttype table type possible_keys key key_len ref rows extra各列。

id:SELECT识别符。这是SELECT的查询序列号;
select_type:查询类型,主要有PRIMARY(子查询中最外层查询)、SUBQUERY(子查询内层第一个SELECT)、UNION(UNION语句中第二个SELECT开始后面所有SELECT)、SIMPLE(除了子查询或者union之外的其他查询);
table:所访问的数据库表明;
type:对表的访问方式,包括以下类型all(全表扫描),index(全索引扫描),rang(索引范围扫描),ref(join语句中被驱动表索引引用查询),eq_ref(通过主键或唯一索引访问,最多只会有一条结果),const(读常量,只需读一次),system(系统表。表中只有一条数据),null(速度最快)。
possible_keys:查询可能使用到的索引;
key:最后选用的索引;
key_len:使用索引的最大长度;
ref:列出某个表的某个字段过滤;
rows:估算出的结果行数;
extra:查询细节信息,可能是以下值:distinct、using filesort(order by操作)、using index(所查数据只需要在index中即可获取)、using temporary(使用临时表)、using where(如果包含where,且不是仅通过索引即可获取内容,就会包含此信息)。
2.Profiling 的使用
mysql除了提供explain命令用于查看命令执行计划外,还提供了profiling工具用于查看语句查询过程中的资源消耗情况。首先我们要使用以下命令开启Profiling功能:
set profiling = 1;
然后执行一条查询命令:
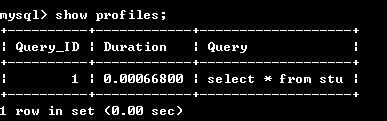
select * from stu;

在开启了Query Profiler功能之后,MySQL就会自动记录所有执行的Query的profile信息了。 然后我们通过以下命令获取系统中保存的所有 Query 的 profile 概要信息:
show profiles;
然后我们可以通过以下命令查看具体的某一次查询的profile信息:
show profile cpu, block io for query 1;

该profile显示了每一步操作的耗时以及cpu和Block IO的消耗,这样我们就可以更有针对性的优化查询语句了。
3.查看慢查询
我们可以用以下命令查看慢查询次数:
show status like 'slow_queries';
使用该命令只能查看慢查询次数,但是我们没有办法知道是哪些查询产生了慢查询,如果想要知道是哪些查询导致的慢查询,那么我们必须修改mysql的配置文件。打开mysql的配置文件(windows系统是my.ini,linux系统是my.cnf),在[mysqld]下面加上以下代码:
log-slow-queries=mysql_slow.log
long_query_time=1
此时我们在mysql中运行以下命令,可以看到slow_query_log是ON状态,log_file也是我们指定的文件:
mysql> show variables like 'slow_query%';
+---------------------+------------------------------+
| Variable_name | Value |
+---------------------+------------------------------+
| slow_query_log | ON |
| slow_query_log_file | mysql_slow.log |
+---------------------+------------------------------+
2 rows in set (0.00 sec)
运行以下命令我们可以看到我们设定的慢查询时间也生效了,此时只要查询时间大于1s,查询语句都将存入日志文件。
mysql> show variables like 'long_query_time';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 1.000000 |
+-----------------+----------+
1 row in set (0.00 sec)
现在我们运行一个查询时间超过1s的查询语句:
mysql> select * from emp where empno=413345;
+--------+--------+----------+-----+------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+-----+------------+---------+--------+--------+
| 413345 | vvOHUB | SALESMAN | 1 | 2014-10-26 | 2000.00 | 400.00 | 11 |
+--------+--------+----------+-----+------------+---------+--------+--------+
1 row in set (6.55 sec)
然后查看mysql安装目录下的data目录,该目录会产生一个慢查询日志文件:mysql_slow.log,在该日志文件中,我们可以知道慢查询产生的时间,最终产生了几行结果,测试了几行结果,以及运行语句是什么。