成果
并没有处理好循环中的重复采集问题,实际上是不能用于多进程的
根据关键词txt(一行一个关键词),以下拉框为标准扩展关键词:
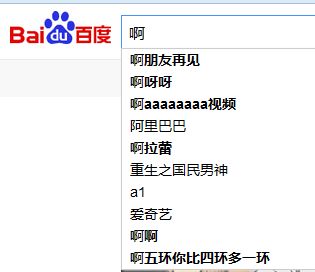
5OGB$AEQUJ`2V9E}ZA8J9FG.png
get_baidu_dasou(kw),get_sougou(kw),get_360(kw)
分别从三个搜索引擎获得扩展关键字,输入单个关键字(kw),返回扩展数列(final_longtaikeywords))
read(kw,zm1s,resultpath)
整合以上3个方法:
输入的单个关键词kw,与zm1s拼音首字母列表中的zm1结合,形成真正的扩展关键词kw+zm1,
由于三个扩展来源的关键词有很多是重复的,需要将3个返回数列打散,重新输入新的数列,并排重
最后将结果写入文档
final(kw)
关键词要经过2轮的扩展
定义zmi1s,zm2s为不同的数列,分别和关键词整合
read分别执行2次;
read(kw,zm1s,resultpath)#第一次扩展,结果在resultpath
read(kw, zm2s, finalpath)#对第一个扩展结果再扩展,结果在finalpath
lastpath第一次和第二结果的去重整合
if name == 'main':
打开startpath1文件(初始扩展关键词文档)
形成关键词list,将执行多线程
代码
import requests
import re
import time
from multiprocessing import Pool
time1 = time.strftime("%H:%M:%S").replace(':','')
def get_baidu_dasou(keyword ='剑圣'):
final_longtaikeywords=[]
try:
url1 = 'http://suggestion.baidu.com/su?json=1&p=3?wd=' + keyword
url2 = 'http://suggestion.baidu.com/su?sugmode=2&json=1&wd=' + keyword
reslt_baidu_dasou1 = requests.get(url1).text
reslt_baidu_dasou2 = requests.get(url2).text
kws = re.compile(r'"st": \{ "q": "(.*?)", "new":')
kws_list_dasou1 = kws.findall(reslt_baidu_dasou1)
kws_list_dasou2 = kws.findall(reslt_baidu_dasou2)
for kws1 in kws_list_dasou1:
final_longtaikeywords.append(kws1)
for kws2 in kws_list_dasou2:
final_longtaikeywords.append(kws2)
print(str(keyword)+':'+str(final_longtaikeywords))
return (final_longtaikeywords) #返回的是数列
except Exception as e:
time.sleep(5)
print(e)
def get_sougou(keyword ='剑圣'):
final_longtaikeywords=[]
try:
urlsougou = 'https://www.sogou.com/suggnew/ajajjson?key='+ keyword+'&type=web&ori=yes&pr=web'
reslt_sougou_dasou1 = requests.get(urlsougou).text
reslt_sougou_dasou1=reslt_sougou_dasou1.split('[')[2] #获得中间的长尾词结果
kws = re.compile(r'"(.*?)",')
kws_list_dasou1 = kws.findall(reslt_sougou_dasou1)
for kws1 in kws_list_dasou1:
final_longtaikeywords.append(kws1)
print(str(keyword)+':'+str(final_longtaikeywords))
return (final_longtaikeywords) #返回的是数列
except Exception as e:
time.sleep(5)
print(e)
def get_360(keyword ='剑圣'):
final_longtaikeywords=[]
try:
url360 = 'http://sug.so.360.cn/suggest?encodein=utf-8&encodeout=utf-8&format=json&fields=word,obdata&word='+ keyword
reslt_360_dasou1 = requests.get(url360).text
kws = re.compile(r'\{"word":"(.*?)"},')
kws_list_dasou1 = kws.findall(reslt_360_dasou1)
for kws1 in kws_list_dasou1:
kws1 = re.sub('","obdata":"{.*}', '', kws1)
final_longtaikeywords.append(kws1)
print(str(keyword)+':'+str(final_longtaikeywords))
return (final_longtaikeywords) #返回的是数列
except Exception as e:
time.sleep(5)
print(e)
def read(kw,zm1s,resultpath):
final_longtais=[]
last_longtais=[]
for zm1 in zm1s:
print('百度搜索:'+kw+zm1)#是否还要判断
final_longtais.append(get_baidu_dasou(kw+zm1))
print('百度搜索:' + zm1+ kw)
final_longtais.append(get_baidu_dasou(zm1+kw))#其他搜索引擎
print('搜狗搜索:' + kw + zm1)
final_longtais.append(get_sougou(kw + zm1))#搜狗不做
print('360搜索:' + kw + zm1)
final_longtais.append(get_360(kw + zm1))
print('360搜索:' + zm1+ kw)
final_longtais.append(get_360(zm1+ kw))
# 形成新的数列
if final_longtais!=None:
for final_longtai in final_longtais: #第一层数列
if final_longtai != None:
for each_word in final_longtai: #数列中的数列
last_longtais.append(each_word)
# 对新数列去重
last_longtais2 = list(set(last_longtais))#去重
last_longtais2.sort(key=last_longtais.index)#按原来的排序
print(last_longtais2)
print(len(last_longtais2))
with open(resultpath,'a+',encoding='utf-8') as text:#写入扩展结果
for last_longtai in last_longtais2:
text.write(last_longtai+'\n')
#写进数据库
def final(kw):
resultpath= r'C:/Users/Administrator/Desktop/result/xiala/'+time1+'resultkeywords.txt'
finalpath = r'C:/Users/Administrator/Desktop/result/xiala/'+time1+'finalkeywords.txt'
lastpath = r'C:/Users/Administrator/Desktop/result/xiala/' + time1 + 'lastpath.txt'
zm1s=['',' ','a','b','c','d','e','f','g','h','j','k','l','m','n','o','p','q','r','s','t','w','x','y','z','0','1','2','3','4','5','6','7','8','9']
#zm1s = ['']
zm2s=['',' ']
#zm2s = ['']
lastlist=[]
read(kw,zm1s,resultpath)#第一次扩展,结果在resultpath
with open(resultpath, 'r', encoding='utf-8') as text: #对第一个扩展结果再扩展
kwsline = text.readlines()
for kw in kwsline:
kw = kw.strip() # 去除空行
kw = kw.replace('\n', '') # 替换最后一行
read(kw, zm2s, finalpath)#对第一个扩展结果再扩展,结果在finalpath
lastlist.append(kw)#第一次扩展结果写入最终列表
with open(finalpath, 'r', encoding='utf-8') as text: #读取第二个结果
kwsline = text.readlines()
for kw in kwsline:
kw = kw.strip() # 去除空行
lastlist.append(kw)#第二次扩展结果写入最终列表
lastlist2 = list(set(lastlist)) # 最终列表去重
lastlist2.sort(key=lastlist.index) # 按原来的排序
print(len(lastlist2))
with open(lastpath, 'a+', encoding='utf-8') as text: #最终列表第三个结果
for singlelastlist in lastlist2:
text.write(singlelastlist + '\n')
if __name__ == '__main__':
start = time.clock()
pool = Pool(processes=6)
keywords_list=[]
startpath1 = r'C:\Users\Administrator\Desktop/result\xiala\testforkeywords.txt' # 关键词存放的地方
with open(startpath1, 'r', encoding='utf-8') as text: # 打开关键词文件,做列表list
kwsline = text.readlines()
for kw in kwsline:
kw = kw.strip() # 去除空行
kw = kw.replace('\n', '') # 替换最后一行
keywords_list.append(kw)
pool.map(final,keywords_list)
pool.close()
pool.join()
end = time.clock()
print ("read: %f s" %(end - start))
注意事项
list去重,顺序不变
lastlist2 = list(set(lastlist)) # 最终列表去重
lastlist2.sort(key=lastlist.index) # 按原来的排序