1.前期准备:
1、Linux基础知识
2、Ubuntu14.04TLS
3、hadoop安装包
2. 新建hadoop用户
adduser hadoop
passwd hadoop
3. 安装JDK
sudo apt-get update #更新后才可用吗default-jdk安装
sudo apt-get install default-jdk
4. 在home目录新建hadoop下载目录,hadoop_download
mkdir hadoop_download
5. 下载hadoop安装文件
cd hadoop_download
wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/hadoop-2.7.1.tar.gz
注:上面的网址有时下载缓慢,不稳定,可以选中下面的附件,右键复制链接地址,替换上述网址。(附件位于文末【文章存档链接中】)格式为:
wget --no-check-certificate [https://网址]
因为网址为https因此需要加--no-check-certificate参数
6. 为sudoers添加hadoop
su #切换root用户
vim /etc/sudoers #若编辑器不存在,请执行sudo apt-get install vim
#在 root ALL=(ALL:ALL) ALL下方新增
hadoop ALL=(ALL:ALL) ALL
#保存并退出vim编辑器
su hadoop #切换回hadoop用户
7. 安装openssh-server
sudo apt-get install openssh-server
#测试安装是否成功
ssh localhost
#输入yes后输入密码成功看到以下消息为成功
Last login: Wed Jan 17 21:08:16 2018 from desktop-eeg1rso.lan
hadoop@ubuntu:~$
8. 解压hadoop-2.7.1.tar.gz
sudo tar -zxvf hadoop_2.7.1.tar.gz -C /usr/local/
解释参数zxvf
x : 从 tar 包中把文件提取出来
z : 表示 tar 包是被 gzip 压缩过的,所以解压时需要用 gunzip 解压
v : 显示详细信息
f xxx.tar.gz : 指定被处理的文件是 xxx.tar.gz
tar -C指定解压的目录【来源网络】
9. 设置hadoop-2.7.1/的写权限
cd /usr/local/
sudo chmod a+W hadoop-2.7.1/
10. 配置文件
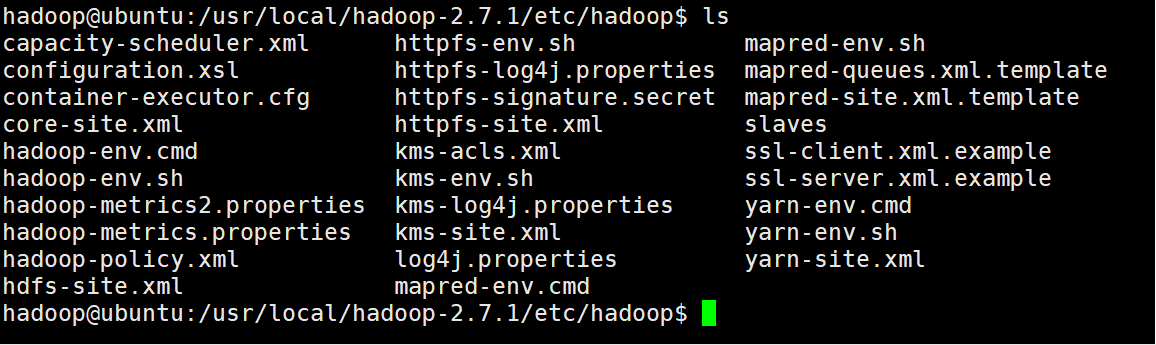
cd hadoop-2.7.1/etc/hadoop/
ll
如下图所示:
image
我们需要配置以下几个文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
10.1 找出Java安装路径
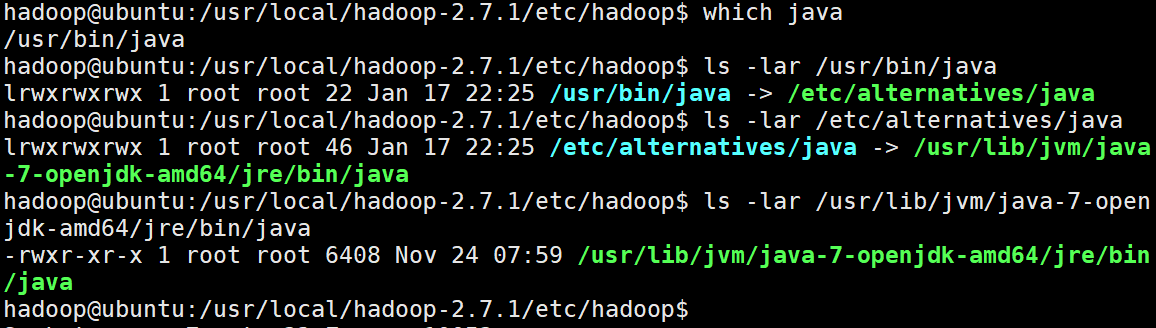
因为我们使用apt安装Java因此,需要找出安装的路径
which java
ls -lar /usr/bin/java
ls -lar /etc/alternatives/java
ls -lar /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
#当路径不在发生改变时,我们即找到了安装目录过程如下图所示
image
因此Java的目录为:
/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
10.2 修改hadoop-env.sh文件
sudo vim hadoop-env.sh
#修改下图的JAVA_HOME
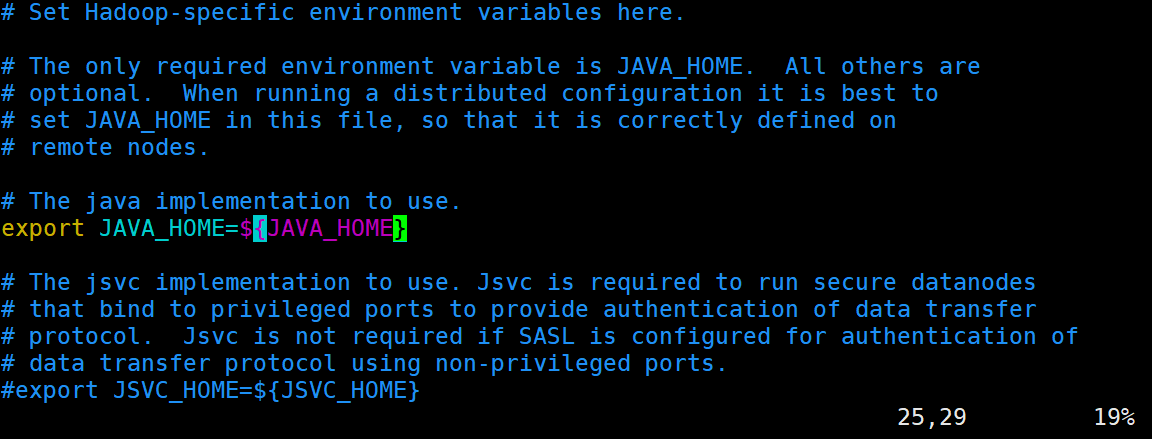
image
/usr/lib/jvm/java-7-openjdk-amd64/jre
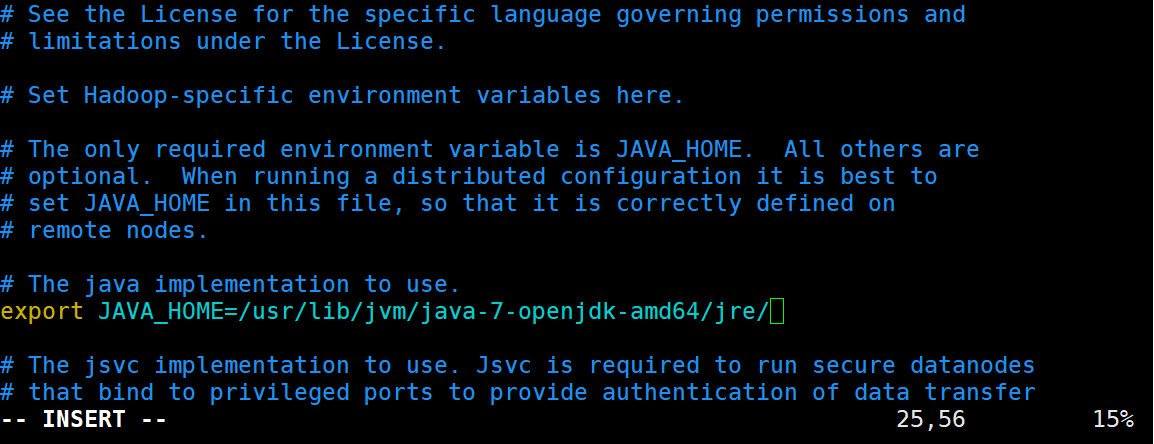
image
10.3 修改core-site.xml文件
mkdir /home/hadoop/hadoop_tmp_data
sudo vim core-site.xml
加入configuration标记之间
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/home/hadoop/hadoop_tmp_data
10.4 修改hdfs-site.xml文件
sudo vim hdfs-site.xml
加入configuration标记之间
dfs.replication
1
11. 格式化namenode
cd /usr/local/hadoop-2.7.1/
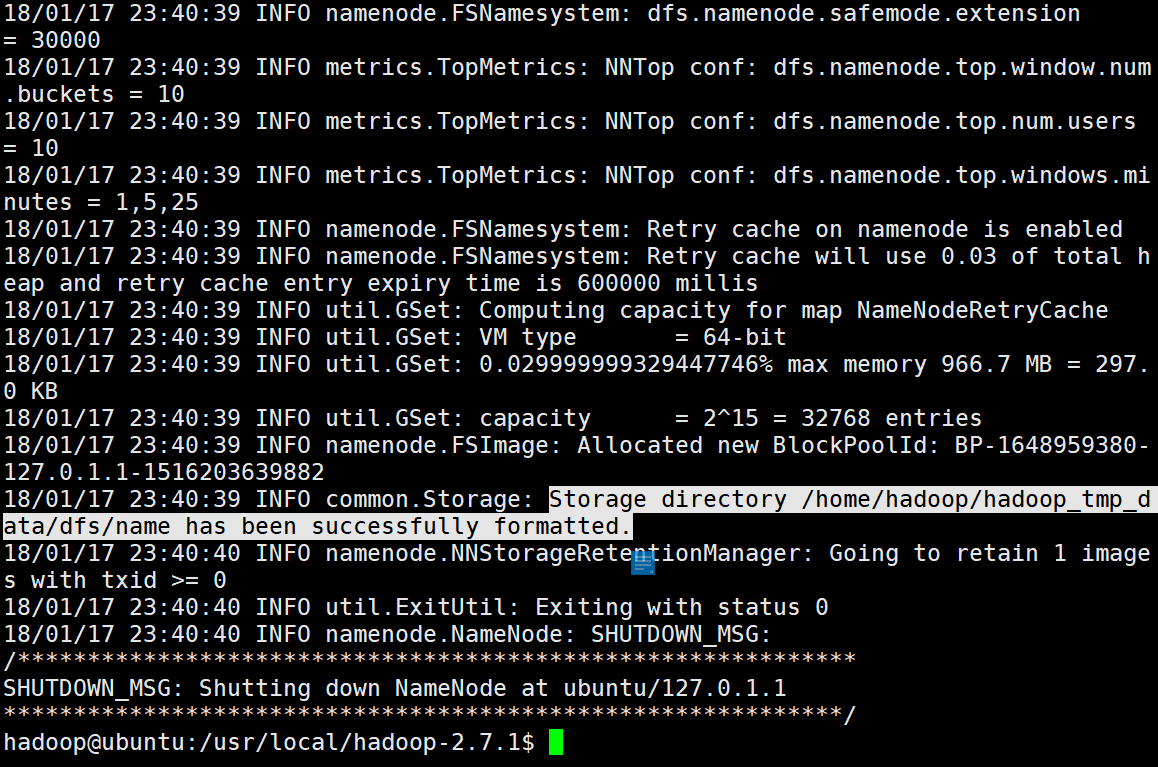
./bin/hdfs namenode -format
看到Storage directory /home/hadoop/hadoop_tmp_data/dfs/name has been successfully formatted.意味着namenode格式化成功。如下图
image
12. 启动hdfs
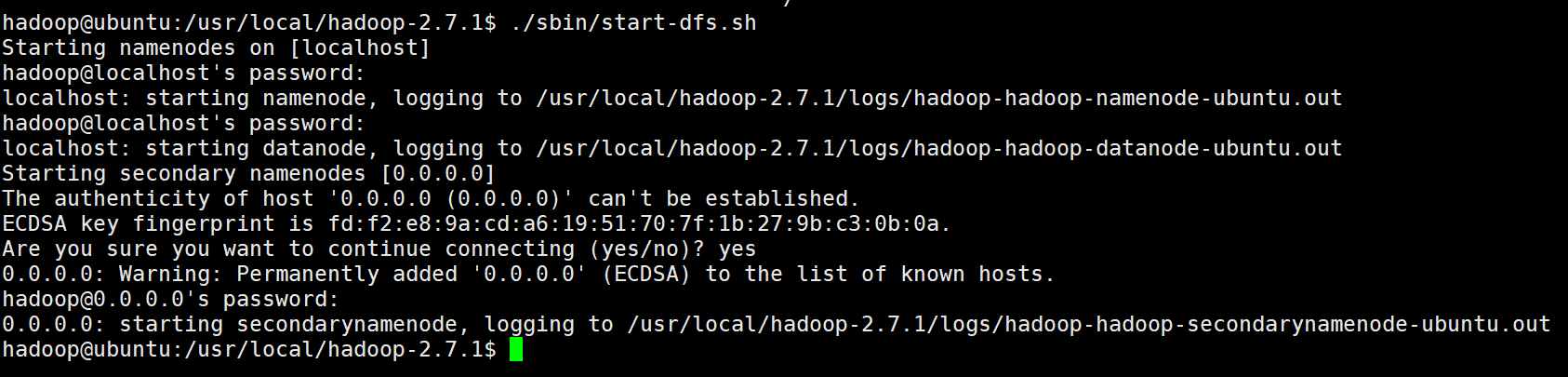
./sbin/start-dfs.sh
#下来会输好几次密码
结果如图
image
13. 验证启动
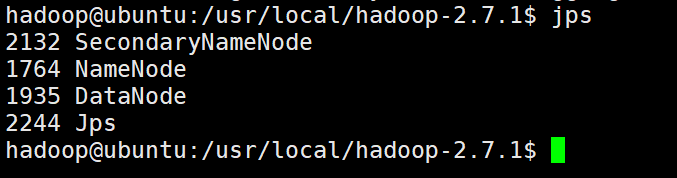
jps
输入后应如下图
image
14. 运行 hadoop伪分布式实例
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
./bin/hdfs dfs -ls input #查看创复制的文件列表
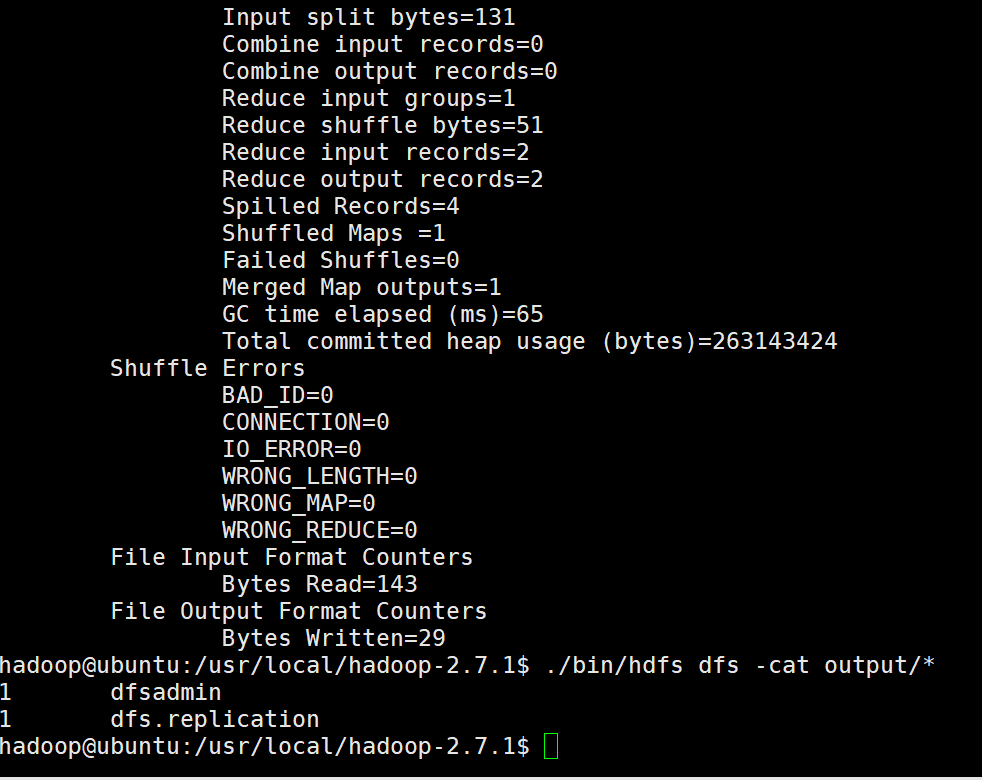
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+' #执行测试
./bin/hdfs dfs -cat output/* #输出结果
输出结果如下:
image
15. 将输出结果取回本地
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/* #输出output文件夹下所有文件
结果如下:

image
16. 关闭hdfs
./sbin/stop-dfs.sh
17. 安装过程可能遇到的错误
- sudo apt-get install defualt-jdk 无效
答:执行sudo apt-get update再执行上述命令即可。 - hdfs格式化namenode格式化失败
答:hadoop-env.sh文件的JAVA_HOME是否有问题,是否配置错误。 - jps执行后进程仅有jps一个
答:可能启动hdfs的用户为root,或hosts中没有公网ip对应hostname - 执行测试验证“./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-.jar grep input output 'dfs[a-z.]+'”是,Java运行库出错,内存过小。
答:Oracle VM VirtualBox可以关机后,增加虚拟机的内存,再次执行
/usr/local/hadoop-2.7.1/sbin/start-dfs.sh
后再次执行上述验证命令
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-.jar grep input output 'dfs[a-z.]+' - 执行13步的第一条命令出错
答:请检查当前位置是否位于/usr/local/hadoop-2.7.1目录中 - 虚拟机安装完毕默认hadoop用户没有root用户
答:给root用户设置密码即可sudo passwd root
- 其他错误请参考17步,文章参考中的①。
18. 文章参考
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
- Hadoop2.4.1伪分布式搭建【传智播客】
- 解压命令tar zxvf中zxvf分别是什么意思
19.备注
- hadoop版本为:2.7.1
- jdk版本为:1.7.0_151
- 实验日期:2018/1/17
20.文章存档
- 石墨文档