1、shell窗口中输入python,即可进入python界面,在输入exit(),即可出来
2、www.cnblogs.com/hester/p/5575658.html(ubuntu中运行python脚本*)
3、首先,总结一下python脚本在ubuntu中的使用:\
1) 新建一个test.py文件,在其中写入代码:
Print “Hello world”
保存
2) 在shell终端中输入,python test.py,就直接输出Hello world了
3) 或者运行进入python界面,直接写语句
注意:只有以上两种方式
4、单行注释是#
5、import sys:导入文件库\
6、import os:python编程时,经常和文件、目录打交道,这是就离不了os模块。os模块包含普遍的操作系统功能,与具体的平台无关。以下列举常用的命令
os.name()——判断现在正在实用的平台,Windows返回‘nt';Linux返回’posix'
os.getcwd()——得到当前工作的目录。
os.listdir()——指定所有目录下所有的文件和目录名。
7、import numpy: Numpy是Python的一个科学计算的库,提供了矩阵运算的功能
8. python区分大小写
9. print“变量名”或者‘变量名’#这样会直接输出变量名,应该是print变量名
10..npy文件查看:
import numpy
c= numpy.load(“文件名”)
c
11、__name__== "__main__":意思就是说让你写的脚本模块既可以导入到别的模块中用,另外该模块自己也可执行。
这句话,可能一开始听的还不是很懂。下面举例说明:
先写一个模块:

这个函数定义了一个main函数,我们执行一下该py文件发现结果是打印出”we are in __main__“,说明我们的if语句中的内容被执行了,调用了main():
但是如果我们从另我一个模块导入该模块,并调用一次main()函数会是怎样的结果呢?
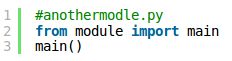
但是没有显示”we are in __main__“,也就是说模块__name__= '__main__'下面的函数没有执行。
这样既可以让“模块”文件运行,也可以被其他模块引入,而且不会执行函数2次。这才是关键。
总结一下:
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__=='__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
12. 注意:关于path的配置:不同的工具比如matlab,python,都有自己相应的path
13. python中二维数组矩阵表示:
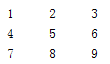
则表示成:[[1,2, 3], [4, 5, 6], [7, 8, 9]]
14、矩阵维度:a.shape
15、(1,1, 100, 100)例如:
[[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]]
16、(4,4,2)例如:
[[[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]]], dtype=float32)
而:(2,4,4,3):
[[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]],
[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]], dtype=float32
总结:python的矩阵都是以数组的形式,最后两位决定基本单元多少维矩阵,前面几位就是一环套一环了,并且都是按照先行后列来的
17、python三维数组读取一列:a[:][0][0][1]
18、注意:python的方法定义可以在python解释器中直接定义,那段代码可以copy进去实现
19、http://blog.csdn.net/lee_j_r/article/details/52791228以及www.tuicool.com/articles/a6JRr2Y里面是对jupyter notebook的使用
jupyter notebook python root和conda root的区别:
They will probably be the same. Conda is making kernels corresponding to conda environments on your computer; if you haven't created any manually, then the only environment will be the 'root environment' that Anaconda sets up by default.

(注:python [root]并不影响使用)
20、plt.figure("output")
plt.imshow(img)显示这个:matplotlib.image.AxesImageobject at 0x02FD5490怎么解决?
确保是在Linux的桌面环境下运行而不是从纯终端或ssh客户端
20、python中的中括号[]:代表list列表数据类型,列表是一种可变的序列。其创建方法即简单又特别,像下面一样:
21、np.dot([[[1,2,3],[1,1,1]],[[1,2,3],[1,1,1]]],[4,5,6]):
array([[32,15],
[32,15]])
结论:python的数组每一严格的行列,只是先行后列,或者先行后行后列,都是逗号分开
22、在python用import或者from...import来导入相应的模块。模块其实就一些函数和类的集合文件,它能实现一些相应的功能,当我们需要使用这些功能的时候,直接把相应的模块导入到我们的程序中,我们就可以使用了。这类似于C语言中的include头文件,Python中我们用import导入我们需要的模块。
from tensorflow.examples.tutorials.mnist import input_data
其中,我发现我有文件夹
/home/echo/anaconda2/envs/tensorflow/lib/python2.7/site-packages/tensorflow/examples/tutorials/mnist,里面还有一个input_data.py
所以有可能之前只是一个到文件夹或者是到某个类文件的路径一样的东西,后面是一个类文件或者类文件的某个函数,我猜是这样
23、with … as …:
with open("/tmp/foo.txt")
as file:
data=file.read()#理解成如下代码
file=open("/tmp/foo.txt")
try:
data=file.read()
finally:
file.close()
24、这里提一下就是因为上面有中文,所以在前面加上coding让他utf-8这是python基础知识
25、”“”...”””也可以作为单行注释
26、python -m xxx.py与python xxx.py几乎一样,只影响sys.path(寻找依赖的库的目录),但是python xxx.py中的.py必须有
27、// "来表示整数除法
28、好像python喜欢把函数定义放在使用之前,所以会形成函数与命令夹杂的情况
29、python中定义新的类:www.cnblogs.com/chenxiaoyong/p/6279874.html
30、函数的参数可以写为xxx=xx,也可以直接写数值,不用写“xxx=”
31、cython:Python和c的混血Cython作为一个Python的编译器,在科学计算方面很流行,用于提高Python的速度
32、python的import与from...import的不同之处:
在Python用import或者from...import来导入相应的模块。模块其实就是一些函数和类的集合文件,它能实现一些相应的功能,当我们需要使用这些功能的时候,直接把相应的模块导入到我们的程序中,我们就可以使用了。这类似于C语言中的include头文件,Python中我们用import导入我们需要的模块。
eg:
import sys
print('================Python import mode==========================');
print ('The command line arguments are:')
for i in sys.argv:
print (i)
print ('\n The python path',sys.path)
from sys import argv,path # 导入特定的成员
print('================python from import===================================')
print('path:',path) # 因为已经导入path成员,所以此处引用时不需要加sys.path
如果你要使用所有sys模块使用的名字,你可以这样:
from sys import *
print('path:',path)
从以上我们可以简单看出:
############################
#导入modules,import与from...import的不同之处在于,简单说:
# 如果你想在程序中用argv代表sys.argv,
# 则可使用:from sys import argv
# 一般说来,应该避免使用from..import而使用import语句,
# 因为这样可以使你的程序更加易读,也可以避免名称的冲突
###########################
from...import
如 from A import b,相当于
import A
b=A.b
再如:
"from t2 import var1" 相当于:
import t2
var1= t2.var1
在此过程中有一个隐含的赋值的过程
import......as
import A as B,给予A库一个B的别称,帮助记忆
33、anaconda里面集成了很多关于python科学计算的第三方库(集成了python),主要是安装方便,而python是一个编译器,如果不使用anaconda,那么安装起来会比较痛苦,各个库之间的依赖性就很难连接的很好
34、python进入编译界面直接就会先显示版本信息,或者python --version
35、python与matlab都属于脚本语言,来源于编程语言(c\c++等),应该是属于那种一步一步执行的样子
36、上下都是三对单引号或者双引号,对多行注释
37、python对格式要求非常高
38、想安装到conda环境就用anaconda的pip install,想安装到系统的python就sudo pip install就可以了
39、pip与conda安装方式不一样,conda会安装所需的python之外的依赖包
40、Python中单引号与双引号都可以表示字符串,只是有时候字符串中出现单引号双引号啥的,可能要用转义字符
41、Cpython:我最喜欢的是Python,它的代码优雅而实用,可惜纯粹从速度上来看它比大多数语言都要慢。大多数人也认为的速度和易于使用是两极对立的——编写C代码的确非常痛苦。而 Cython(准确说Cython是单独的一门语言,专门用来写在Python里面import用的扩展库。实际上Cython的语法基本上跟Python一致,而Cython有专门的“编译器”;先将 Cython代码转变成C(自动加入了一大堆的C-Python API),然后使用C编译器编译出最终的Python可调用的模块) 试图消除这种两重性,并让你同时拥有 Python 的语法和 C 数据类型和函数——它们两个都是世界上最好的。
42. Clone是用git客户端clone代码库,代码处于版本管理下。download就是普通下载了。
43. 如何从GitHub获取源代码
github是当前流行的开源项目托管网站,里面有成千上万的项目值得学习和借鉴,可以把项目源代码下载到本地研究。本文介绍如何获取github的源代码。
方法1-克隆(Clone)源代码到本地
克隆之后会把源代码下载到本地,创建一个本地的代码库,可以任意在本地修改代码并使用git所提供的命令操作代码,有代码对应的历史记录和分支。
方法2-下载源代码Zip包
只是最新源代码的打包,没有git对象信息,不能查看代码的分支和历史记录。
方法3-直接在线浏览代码并复制想要的代码段
项目的源代码可以直接在代码浏览窗口查看,感兴趣的话可以直接复制或者下载。
44.